












Giới thiệu
hocvietcode.com là website chia sẻ và cập nhật tin tức công nghệ, chia sẻ kiến thức, kỹ năng. Chúng tôi rất cảm ơn và mong muốn nhận được nhiều phản hồi để có thể phục vụ quý bạn đọc tốt hơn !
Liên hệ quảng cáo: trienkhaiweb@gmail.com
Kürzlich habe ich ein kleines Projekt mit LSTMs durchgeführt, aber das Lesen vietnamesischer Dokumente, um das Sprechen tief zu verstehen, ist nicht sehr klar, es gibt diesen Artikel https://dominhhai.github.io/vi/2017/10 /what-is-lstm / ist von einer fremden Seite übersetzt, was ich ziemlich gut finde. Dann möchte ich durch das Projekt, das ich gemacht habe, hier sein, um in Zukunft einige Dinge für alle und mich selbst zu teilen, wenn ich es lange nicht benutzt habe, und es dann erneut lesen, um darüber nachzudenken.
Mục lục
Bevor ich LSTMs erkläre, sollte ich ein wenig über die Wurzeln der unten abgebildeten RNN (Recurrent Neural Networks) wissen:
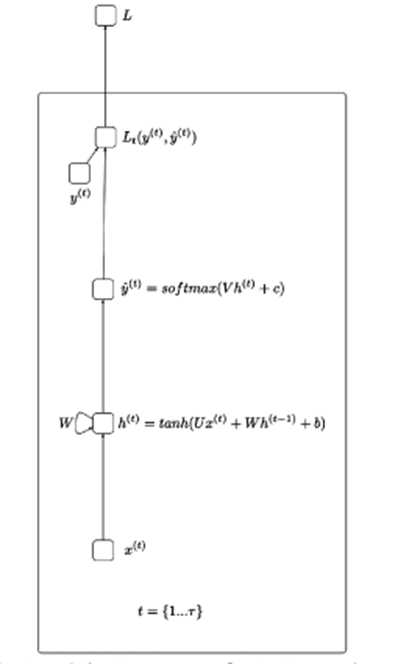
Einfach ausgedrückt hilft RNN dabei, Daten in Form einer sequentiellen Sequenz zu verarbeiten – wie z. B. die Verarbeitung von Sprache, Aktionen, … Die Idee der obigen Abbildung ist, dass die Eingabe x die verborgenen Schichten durchläuft und den Ausgabewert zurückgibt (kann 1 Array sein) Aus der Ausgabe, die durch die Verlustfunktion geht, wird y_hat.
X(t): Eingangswert im Zeitschritt t
H(t): Versteckter Zustand im Zeitschritt t
O(t): Ausgabewert im Zeitschritt t
Y_hat: Normalisierter Wahrscheinlichkeitsvektor durch Softmax-Funktion im Zeitschritt t
U, V, W: Die Gewichtsmatrizen im RNN entsprechen den Verbindungen in Richtung vom Anfang zum verborgenen Zustand, vom verborgenen Zustand zum Ausgang und vom verborgenen Zustand zum verborgenen Zustand.
B, c: Abweichung (Bias)
LSTM hilft, den verschwindenden Gradienten von RNN zu überwinden. Da wir Gradienten verwenden, um Neuronen zu trainieren, und RNN vom Kurzzeitgedächtnis beeinflusst wird, wenn die Eingabedaten lang sind, kann RNN wichtige übertragene Informationen von Anfang an vergessen.
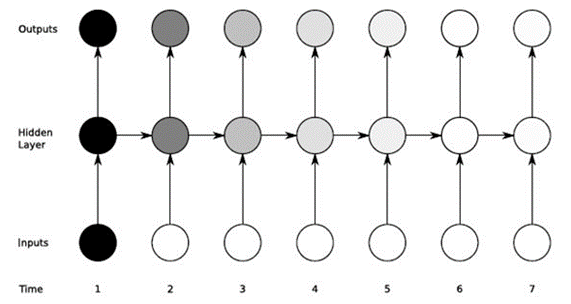
Wenn wir uns beispielsweise eine Filmserie ansehen, speichert unser Gehirn die Inhaltsinformationen der vorherigen Teile und kombiniert sie mit der Folge, die wir uns ansehen, um eine Geschichte zu erstellen.
LSTM hilft, unnötige Datenpunkte zu reduzieren, indem Gates intern installiert werden und ein durchgehender Zellzustand vorhanden ist.

Es gibt viele Artikel und Bilder, die den Betrieb jedes Tors und die aktiven Funktionen erklären. Also versuche ich hier, Mathe zu benutzen, um diesen Typen zu erklären. Um es schnell zusammenzufassen, verwendet LSTM 1 Zellzustand und 3 Gatter, um Eingabedaten zu verarbeiten. Das Rezept habe ich im Bild unten eingefügt:


Dies ist die Operation des LSTM in einem Zeitschritt, was bedeutet, dass diese Formeln in einem anderen Zeitschritt neu berechnet werden. Und die Gewichte (Wf, Wi, Wo, Wc, Uf, Ui, Uo, Uc) und die Vorspannung (bf, bi, bo, bc) ändern sich nicht.
Um beispielsweise LSTM in 10 Zeitschritten bereitzustellen, können Sie Folgendes tun:
Sequenzlänge = 10
für i im Bereich (0,sequence_len):
# wenn wir uns auf dem ersten Schritt befinden
# h(t-1) und c(t-1) initialisieren
# nach dem Zufallsprinzip
wenn i==0:
ht_1 = zufällig()
ct_1 = zufällig()
anders:
ht_1 = h_t
ct_1 = c_t
f_t = sigmoid (
matrix_mul(Wf, xt) +
matrix_mul(Uf, ht_1) +
bf
)
i_t = sigmoid (
matrix_mul(Wi, xt) +
matrix_mul(Ui, ht_1) +
Bi
)
o_t = sigmoid (
matrix_mul(Wo, xt) +
matrix_mul(Uo, ht_1) +
bo
)
cp_t = tanh (
matrix_mul(Wc, xt) +
matrix_mul(Uc, ht_1) +
v. Chr
)
c_t = element_wise_mul(f_t, ct_1) +
element_wise_mul(i_t, cp_t)
h_t = element_weise_mul(o_t, tanh(c_t))
Ein unverzichtbares Problem in der linearen Mathematik ist die Dimensionalität der Daten (dies ist möglicherweise der Teil, den ich in Zukunft erneut lesen muss, da er häufig auf der Liste der Interviewfragen steht).
Mit den Formeln des LSTM in einem Zeitschritt wie folgt:
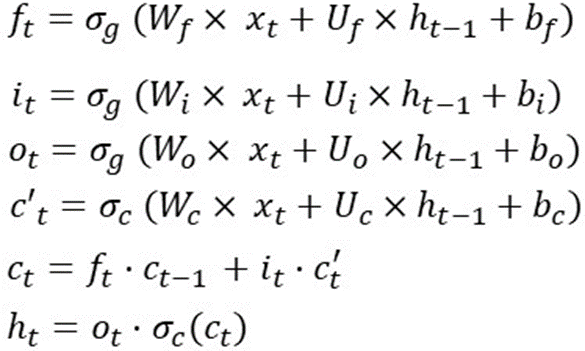
Nehmen wir an, dim(o(t)) ist [12×1] => dim(h(t)) und dim(c(t)) ist [12×1], weil h(t) eine elementweise Multiplikation zwischen o( t) und tanh(c(t)).
Und x(t) hat Dimensionen von [80×1] => W(f) ist [12×80], weil f(t) = [12×1] und x(t)=[80×1]
Bf, bi, bc, bo haben Abmessungen von [12×1]
Und Uf, Ui, Uc, Uo haben Abmessungen von [12×12]
Das Gesamtgewicht des LSTM ist also: 4*[12×80] + 4*[12×12] + 4*[12×1] = 4464.
Wenn man sich die obige Berechnung ansieht, ist ersichtlich, dass LSTMs an zwei Dingen interessiert sind: Eingabedimension und Ausgabedimensionalität (einige Blogs nennen es möglicherweise Anzahl von LSTM-Einheiten oder versteckte Dimension, …).
Zusammenfassend ist die Gewichtungsmatrixgröße von LSTM 4*Output_Dim*(Output_Dim + Input_Dim + 1)
Es gibt eine Anmerkung zu dem Parameter, die viele Leute verwirren:

In Keras gibt es einen Parameter, der return_sequence ist (gibt true, false zurück), wenn return_squence=False (Standard) viele zu eins ist und ansonsten True von vielen zu vielen.
Beispiel mit Eingabedaten X der Größe [5×126]
Modelle sind wie folgt:
Modell = Sequentiell ()
model.add(LSTM(64, return_sequences=True, activation='relu', input_shape=(5,126)))
model.add(LSTM(128, return_sequences=True, activation='relu'))
model.add(LSTM(64, return_sequences=False, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(actions.shape[0], activation='softmax'))
Es ist durch die erste LSTM-Schicht mit einer versteckten Zahl von 64 zu sehen => Die Anzahl der Parameter nach dem Passieren dieser Schicht beträgt:
4 * ((126 + 64) * 64 + 64) = 48896 (dasselbe gilt für die folgenden 2 LSTM-Schichten, und ihre Ausgabe ist die Eingabe der nächsten Schicht).
Für dichte Schichten (ist eine Schicht in Keras, bei der output_dim die Ausgabedimension dieser Schicht ist), ist die Anzahl der neuen Parameter gleich output_dim * output_dim (der vorherigen Schicht) + 1
Beispiel mit der ersten dichten Schicht: Die Anzahl der Parameter ist: 64*(64+1)=4160

Zusammenfassend habe ich in diesem Artikel versucht, die Funktionsweise von LSTM aus der Perspektive der Berechnung von Parametern zu erklären. Dies ist ein ziemlich wichtiger Schritt, um Ihnen beim Entwerfen und Beschleunigen des Modells für maschinelles Lernen zu helfen.

hocvietcode.com là website chia sẻ và cập nhật tin tức công nghệ, chia sẻ kiến thức, kỹ năng. Chúng tôi rất cảm ơn và mong muốn nhận được nhiều phản hồi để có thể phục vụ quý bạn đọc tốt hơn !
Liên hệ quảng cáo: trienkhaiweb@gmail.com