
Giới thiệu
hocvietcode.com là website chia sẻ và cập nhật tin tức công nghệ, chia sẻ kiến thức, kỹ năng. Chúng tôi rất cảm ơn và mong muốn nhận được nhiều phản hồi để có thể phục vụ quý bạn đọc tốt hơn !
Liên hệ quảng cáo: trienkhaiweb@gmail.com

Einführung in die Ereignisbehandlung in AngularJS, wie Ereignisse in AngularJS durch die ng
Das Konzept des Filters in AngularJS, selbstdefinierte benutzerdefinierte Direktive für AngularJS-Anwendung
Das Konzept von Routen in AngularJS, Erläuterung des clientseitigen Rendering-Mechanismus und des aktuell verwendeten Javascript-Frameworks
Einführung in die Formularvalidierung in AngularJS, Formularzustände, Eingabe, CSS-Klassenrollen in AngularJS-Formular
Stellen Sie das Konzept von Animationen (Bewegung) in AngularJS vor und wie man sie in der Praxis verwendet.
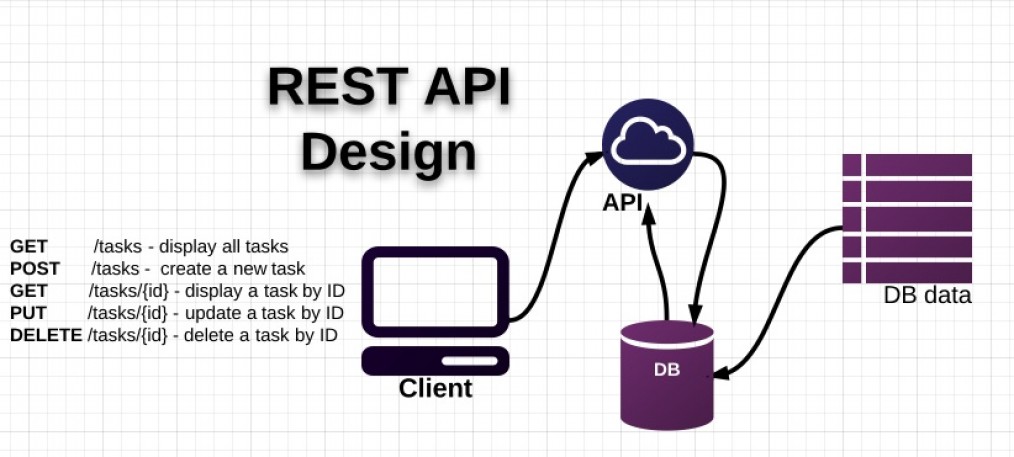
Einführung in die Client-Server-Kommunikation über den REST-API-Mechanismus, Einführung in REST-Regeln, Normalisierung, HTTP-Antwortnachricht...
Das Konzept des Abhängigkeitsinjektionsmechanismus in angleJS und Einführung von value(),constant(),provider()
Einführung in Factory- und Service-Methoden in AngularJS zur Erstellung benutzerdefinierter Services, die gemeinsame Geschäfte durch Injektion abwickeln
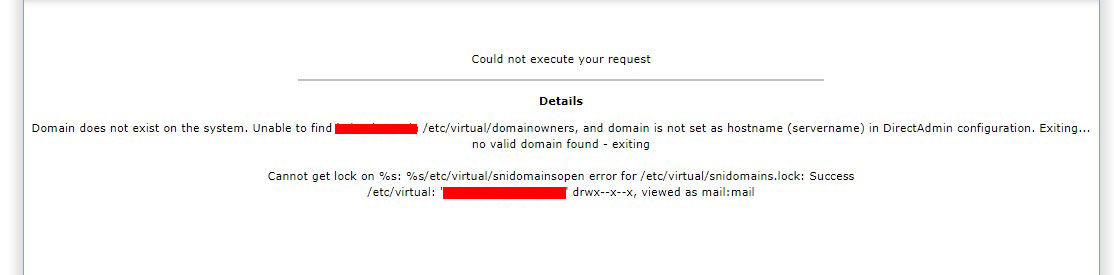
Handhabung des Fehlers Domäne existiert nicht auf dem System. Kann nicht gefunden werden

Einführung in das Konzept des verwandten Datenbankmanagementsystems (Related Database Management System / RDBMS)[| ]
In der Praxis halten Websites, Softwareprojekte, Organisationen - Agenturen in der Regel eine große Menge an Daten, die das Ergebnis der täglichen Datenerfassung sind (z im Grunde auf Papier gespeichert werden, heutzutage digitalisieren die Menschen sie.Für eine einfachere Speicherung bestehen die grundlegendsten Speicherlösungen darin, aus Sicht des Benutzers in Dateien (Dateien) zu speichern, früher .txt-Textdateien, dann Word-, Excel-Dateien ( .doc, .xls) Was Programmierer betrifft, so speichern wir sie in Dateien (Rezension Lesen und Schreiben von Textdateien und Lesen und Schreiben von Binärdateien in C). In der modernen Programmierung, wenn die Datenmenge immer größer und schwieriger zu verwalten ist , führten die Leute das Konzept einer Datenbank (Datenbank) ein, um eine Organisation von Daten darzustellen, die ein oder mehrere Datenelemente enthalten kann, die als Datensätze bezeichnet werden. Wir können eine Datenbank verstehen u ist ein Datensatz, der Daten nach verschiedenen Fragestellungen erfüllen kann. Zum Beispiel:
Daten sind Informationen und sie sind die wichtigste Komponente in jeder Art von Arbeit, Organisationsmechanismus ... Bei täglichen Aktivitäten verwenden wir verfügbare Daten, erstellen oder aktualisieren, fügen neu generierte Daten hinzu, die Daten werden gesammelt und analysiert und den Informationen präsentiert der Nutzer. Das können Informationen über Personen, Fahrzeuge, Produkte, Sport, Wetter usw. sein. Kurz gesagt, Daten sind Informationen, und auf der Grundlage dieser Informationen sammeln wir sie in einem Datenblock, der bestimmten Aufgaben dient.
Kommen wir zu einem Beispiel: Die Regierung hat einen Datensatz, um die gesamten Bevölkerungsdaten zu speichern, basierend auf den gesammelten Daten kann die Regierung identifizieren:
Oder ein Beispiel: Ein Unternehmen, das Computerkomponenten herstellt, plant, eine Komponente zu produzieren, die zuvor nur importiert wurde. Wenn das Unternehmen über alte Daten zu den Importpreisen von Komponenten für die letzten 5 Jahre verfügt, wird die Sache einfacher, das Unternehmen kann die Gesamtkosten der importierten Teile basierend auf dem Importpreis, der Importmenge und den jedes Jahr importierten Komponenten berechnen und anhand dieser Daten ist es möglich zu überlegen, ob sich die Kosten für Fabrikinvestitionen, Arbeit und Produktion von Fertigprodukten stark von denen der Importe unterscheiden ...
Auf der Grundlage dieses Datensatzes kann die Regierung ihn vollständig verwenden, um zu urteilen und in Zukunft auf der Grundlage der Entwicklungsorientierung vernünftige Richtlinien zu treffen.
In Organisationen, Unternehmen ... ist es dasselbe, die Informationen ermöglichen es, basierend auf historischen Daten Vorhersagen zu treffen und entsprechend zu planen, und wenn die Aggregation einfach ist, helfen Smart Performances Unternehmen und Organisationen, eine Menge Ressourcen und Geld zu sparen.
Eine Datenbank ist eine Sammlung von Datenlisten oder kann als kompatibler Datenorganisationsmechanismus zum Speichern von Daten verstanden werden. Auf diese Informationen kann der Benutzer effizient und schnell zugreifen.
Zum Beispiel:
Das Telefonbuch ist eine Datenbank. In dieser Datenbank werden die Kontaktinformationen jeder Person als Datensatz bezeichnet. Dieser Datensatz enthält:
Zusammenfassend ist eine Datenbank eine organisierte Liste von Daten, auf deren Inhalt leicht zugegriffen, verwaltet oder aktualisiert werden kann.
Data Governance ist sinnvoll, wenn wir große Mengen an Informationen verwalten müssen, einschließlich der Organisation der Informationsspeicherung und der Bereitstellung von Mechanismen zur Bearbeitung von und Arbeit mit Informationen oder Daten. Darüber hinaus muss das System in verschiedenen Fällen auch die Sicherheit gespeicherter Informationen gewährleisten, beispielsweise Mechanismen zur Einschränkung der Rechte von Benutzern, die darauf zugreifen können, Daten, die vertraulich behandelt werden müssen, oder Mechanismen zur Zugriffsbeschränkung. Speichern von Passwörtern ... .
Die Größe der Daten beim Speichern ist immer ein großes Problem, in der Vergangenheit verwendeten die Leute das Dateisystem (Dateien) zum Speichern von Daten (Sie können den Artikel Arbeiten mit DATEI in C-Sprache noch einmal sehen. ). In diesem System werden Daten in unterschiedlichen diskreten Dateien gespeichert, und die Sammlung dieser Dateien wird im Computer gespeichert. Sie können abgefragt und mit Daten aus dem Betriebssystem interagiert werden. Die zum Speichern von Daten verwendeten Dateien werden normalerweise als Tabellen bezeichnet, die Zeilen in dieser Tabelle werden als Datensätze bezeichnet und die Spalten werden als Felder bezeichnet.
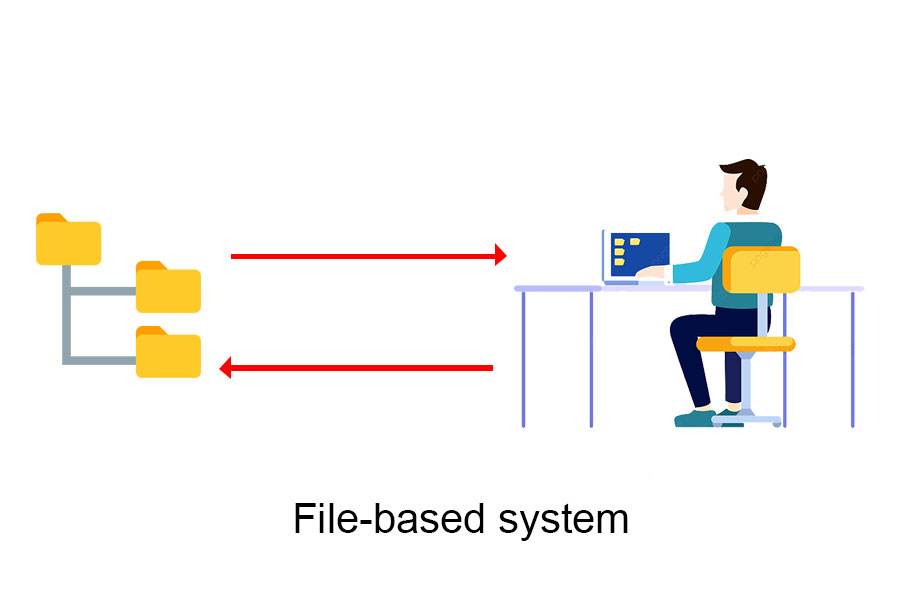
Bevor es Datenbankverwaltungssysteme gab, benutzten Menschen Dateien, um Daten in Softwareanwendungen zu speichern.
In einem dateibasierten System interagieren verschiedene Programme und Funktionen einer Anwendung mit verschiedenen Dateien, um das Geschäft zu erfüllen, es hat kein Datenstandardisierungssystem oder zeigt, wie Daten organisiert werden, Struktur und Struktur dieser einzelnen Dateien.
Wenn Dateien aufgeteilt werden, um separate Daten zu speichern, werden die diskreten Daten leicht redundant und inkonsistent. Betrachten Sie zum Beispiel: Eine Funktion, die Schüler hinzufügt/bearbeitet/löscht/sortiert, interagiert mit der Datei, in der die Schülerliste gespeichert ist, eine Funktion, die Klassen hinzufügt/bearbeitet/löscht/sortiert, arbeitet mit der Archivdatei class ... , während ein Schüler vorhanden ist ein Objekt, das zur Klasse gehört, z. B. Student Nguyen Van A ist in Klasse 1B -> das Problem wird von hier aus entstehen. Wir müssen der Schülerdatendatei ein Feld hinzufügen, um die Klasse zu speichern, die der Schüler studiert hat, basierend auf den verfügbaren Klassendaten. Einige Situationen mit falschem Code, nicht standardmäßigen Daten (z. B. falsche Schülereingaben) führen auch zu unangemessenen Situationen (Klasse ist nicht in der Datenbank oder wurde gelöscht, aber die Schülerseite hat sie noch). Feld repräsentiert diese Klasse. ..
In einem dateibasierten System kann eine abrupte oder spontane Abfrageverarbeitung sehr schwierig sein, insbesondere wenn Änderungen am Programm vorgenommen werden. Beispielsweise muss ein Banker eine Liste aller Kunden mit einem Kontostand von 2000 $ oder mehr erstellen. Banker haben Optionen: Sie erhalten eine Liste aller Kunden und extrahieren die erforderlichen Informationen manuell oder beauftragen einen Systemprogrammierer mit der Entwicklung des erforderlichen Anwendungsprogramms. Beide Alternativen sind unbefriedigend. Angenommen, ein solches Programm wird geschrieben, und ein paar Tage später muss der Mitarbeiter diese Liste kürzen, um nur Kunden aufzunehmen, die ihr Konto vor einem Jahr eröffnet haben. Da ein solcher Listengenerator nicht existiert, ist der Zugriff auf die Daten schwierig.
Die Daten sind in vielen verschiedenen Dateien verstreut, und die Datei kann ein anderes Format haben. Obwohl die Daten von verschiedenen Programmen in der Anwendung verwendet werden, gibt es einige Situationen, in denen die Daten verknüpft werden können, sie werden als verstreute und nicht verknüpfte Datendateien gespeichert.
In einem Mehrbenutzersystem können viele Benutzer gleichzeitig auf Dateien oder Datensätze zugreifen, was die Handhabung des dateibasierten Systems erschwert.
In Unternehmen oder Organisationen ist auch die Datensicherheit ein großes Thema, Daten sollten sicher sein und nur dann zugänglich sein, wenn autorisierte, dateibasierte Systeme dies nicht gut können.
In jeder Anwendung sind bestimmte Datenintegritätsregeln erforderlich, die eingehalten werden sollten. Sie können bestimmte Bedingungen oder Einschränkungen für die Elemente oder Aufzeichnungen der Daten haben. Bei einem dateibasierten System kann dies nicht auf der Datenschicht erfolgen, da Daten naturgemäß nur in Dateien gespeichert werden, diese Dinge nur auf der Codeschicht ausgeführt werden können und sehr kompliziert sind, sie weiterhin zu pflegen oder zu ändern die Anwendungsdaten werden größer.
Das Datenbanksystem wurde in den 1960er Jahren entwickelt, um die Probleme der Anwendungsentwicklung beim Umgang und Umgang mit Big Data zu lösen und ist datenintensiver. Und auch um Probleme zu lösen, die sich aus den Nachteilen dateibasierter Systeme ergeben.
Die Datenbank wird verwendet, um Daten effizient und organisiert zu speichern. Eine Datenbank ermöglicht eine einfache und schnelle Datenverwaltung. Beispielsweise muss ein Unternehmen Daten zu Personalinformationen in einer Datenbank pflegen, die Daten sollten jederzeit einfach abgefragt, hinzugefügt oder durchsucht werden können...
Wenn nur in Bezug auf die Speicherung, auch unter Verwendung einfacher manueller Dateien, die Daten erfüllt werden können, muss die Universität beispielsweise Informationen zu Lehrern, Schülern, Fächern pflegen. Diese Informationen können jedoch im Laufe der Zeit in separaten Dateien gepflegt und gespeichert werden die Daten Dateien werden Junk, verbrauchen viel Speicherplatz, das Verwalten von mehr Bearbeiten und Löschen ist sehr schwierig, daher ist es nicht für die langfristige Speicherung über viele Jahre geeignet.
Wenn Sie stattdessen diese in einem Datenbanksystem gespeicherten Daten verwenden, können die Daten für eine lange Zeit gespeichert werden, einfacher abgefragt und aktualisiert werden.
Daten oder Informationen werden normgerecht langfristig gespeichert und über ein Datenbanksystem digitalisiert. Das Datenbanksystem hat viele Vorteile, da es eine zentralisierte Datenspeicherlösung bereitstellt.
Innerhalb einer Organisation oder Behörde haben die Daten der Abteilungen oft die gleiche Struktur. Durch die Kombination einer zentralisierten Datenbank können mehrere Abteilungen auf Daten zugreifen, die denselben Standards entsprechen, wodurch Datenduplizierung oder Datenredundanz minimiert werden.
Wenn Daten in verschiedenen Abteilungen mit einem dateibasierten System dupliziert werden, wirkt sich jede Änderung an den Daten auf die zugehörigen Daten aus, was manchmal zu Inkonsistenzen in den Daten führt, da die Aktualisierung von Daten auf der Codeebene erfolgt, wenn die Daten und die Quellcode wird komplex, dann treten Probleme auf. In einem zentralisierten Datenbanksystem oder der Datenbank, von der wir sprechen, ist es durchaus möglich, die Daten regelmäßig zu aktualisieren, in diesem Fall kann nur ein Datensatz aktualisiert werden, und das Problem von Dateninkonsistenzen reduzieren.
Die Datenbank kann sich auf einem Server befinden und verfügt über einen Mechanismus zur gemeinsamen Nutzung mit verschiedenen Benutzern, wenn diese erteilt werden. Auf diese Weise können Benutzer jederzeit auf die Daten zugreifen und diese aktualisieren.
Eine zentralisierte Governance stellt sicher, dass Datenstandards, wie sie dargestellt werden, festgelegt und eingehalten werden können. Beispielsweise ist es üblich, den vollständigen Namen eines Benutzers darzustellen, um Mr. Toan Ngo Vinh (vollständiger Name), also wird es in 3 Komponenten unterteilt:
Die Verwendung der Datenbank stellt dieses Format bei der Speicherung gemäß der Absicht des Datenbankdesigners sicher.
Die Datenintegrität wirkt sich auf die Genauigkeit der Datenbank aus. Wenn beispielsweise ein Mitarbeiter aus einer Organisation ausscheidet, muss die Personaldatenbank aktualisiert werden, die Informationen des Mitarbeiters, der gerade gekündigt hat, und zugehörige Daten sollten aus der Datenbank gelöscht oder an einem anderen Ort gespeichert werden, um die Personalhistorie zu speichern. Die Daten über die Arbeit dieses Mitarbeiters sollten auf einen anderen Mitarbeiter übertragen werden, damit die Arbeit fortgesetzt werden kann.
Eine zentral gehostete Datenbank hilft, diese Fehler zu vermeiden. Mit dem Mechanismus der Datenbank werden die Daten definitiv aus der Tabelle gelöscht und die Verknüpfungen mit diesem Datensatz werden ebenfalls gelöscht oder aktualisiert, je nach Absicht des Designers.
In einem zentralisierten Datenbanksystem müssen die Privilegien zum Aktualisieren von Daten autorisiert werden. Der richtige Mechanismus besteht darin, dass nur eine Person die vollständige Kontrolle über die gesamte Datenbank hat. Diese Person wird Datenbankadministrator (DBA) genannt. Der DBA kann einen Sicherheitsmechanismus implementieren, indem er den Daten Beschränkungen auferlegt. Basierend auf der Berechtigung des DBA können autorisierten Benutzern Berechtigungen zum Hinzufügen, Bearbeiten, Löschen und Abfragen von Daten zugewiesen werden.
Das DBMS kann eine Liste verwandter Datensätze und eine Reihe von Programmen definieren, die diese Datensätze abfragen und mit ihnen arbeiten können. Mit DBMS können Benutzer auf Daten zugreifen, diese speichern und verwalten. Das Hauptproblem bei früheren DBMSs bestand darin, dass Daten in Dateien geschrieben wurden, sodass Informationen zu verschiedenen Objekten in verschiedenen physischen Dateien verwaltet wurden. Daher verbleibt die Zuordnung zwischen Objekten in getrennten Dateien, was zu einer Situation führt, in der es zu viele Dateien und viele Funktionen gibt, um sie in ein einzelnes System zu integrieren.
Die Lösung für diese Probleme besteht darin, die Daten in einem zentralisierten Datenbanksystem zu normalisieren. Die Datenbank wird an einem einzigen Ort gespeichert, die Benutzer können über ihre eigenen Geräte auf die auf dem Server gespeicherten Daten zugreifen.
Kurz gesagt, eine Datenbank ist eine Sammlung von Listen zusammenhängender Daten , und ein DBMS ist ein System, das aus einer Reihe von Programmen besteht, die zum Hinzufügen, Bearbeiten und Löschen dieser Daten verwendet werden. Verständlicherweise ist ein DBMS eine Software, die eine Reihe von Funktionen enthält, die dabei helfen, eine Datenbank zu definieren, Daten zu erstellen, mit ihnen zu interagieren und mit ihnen zu arbeiten.
DBMS bietet eine komfortable und effiziente Umgebung für die Arbeit mit großen Datensätzen und interaktiven Aktualisierungsvorgängen. DBMS kann von einem kleinen System, das auf einem Personal Computer läuft, bis zu einem großen Computersystem angepasst werden.
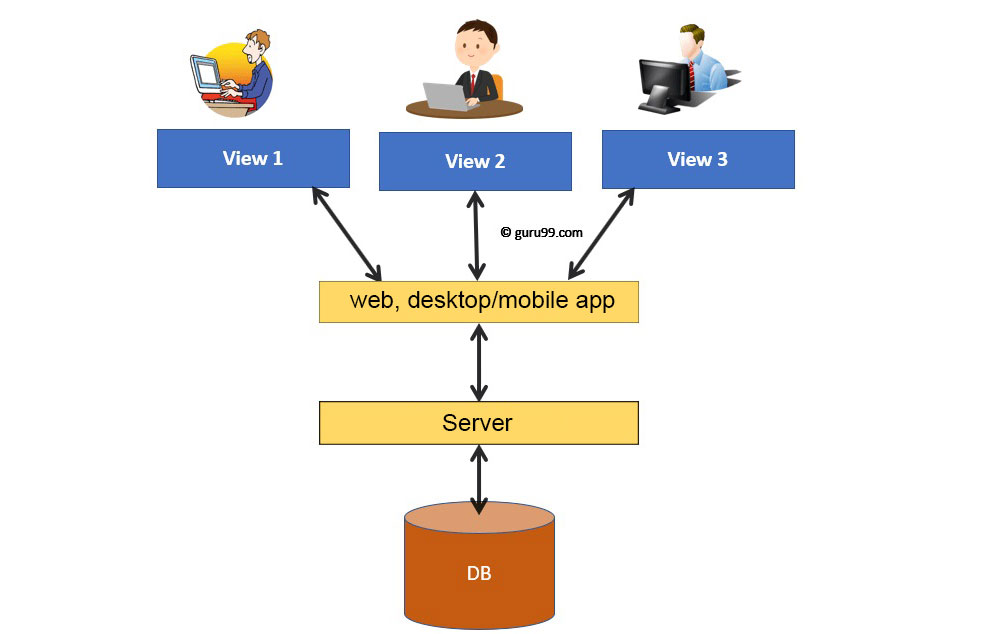
Hier sind einige Beispiele dafür, was DBMS-Anwendungen in der Praxis leisten können:
Aus technischer Sicht weisen DBMS-Produkte viele Unterschiede auf. DBMS unterstützt verschiedene Abfragesprachen, aber im Allgemeinen haben sie immer noch einige gemeinsame Punkte, die Programmierern helfen, auf DBMS einfach zuzugreifen und es nach Wunsch zu konvertieren. Die Leute nennen diese Sprache: Structured Query Language (SQL).
Die Sprache zur Verwaltung von Datenbanksystemen heißt Fourth Generation Language (4GL). Informationen aus der Datenbank können in einer Vielzahl von Formaten präsentiert werden. Die meisten DBMS enthalten ein Programm zum Schreiben von Berichten, mit dem Benutzer Daten in einem Berichtsformat exportieren können. Viele DBMS enthalten auch grafische Informationen in Form von Grafiken und Diagrammen.
Es ist nicht erforderlich, ein allgemeines DBMS zu verwenden, um eine Datenbank bereitzustellen. Benutzer können ihren eigenen Satz von Programmen schreiben, um Datenbanken zu erstellen und zu pflegen, wodurch Datenbanken und DBMSs erstellt werden, die zum Abfragen, Interagieren mit Daten usw. verwendet werden können, je nach Zweck des Programmierers. Datenbank und Software zusammen werden als Datenbanksystem bezeichnet.
Endbenutzer greifen auf das Datenbanksystem über die grafische Schnittstelle von Anwendungen zu, die die Datenbank direkt abfragen. Ein DBMS ermöglicht es Benutzern, Abfragen auszuführen und Daten aus der Datenbank über den Quellcode hinter der Software und den Programmen abzurufen, die die Ergebnisse an den Endbenutzer zurückgeben.
Das DBMS ist dafür verantwortlich, Daten zu verarbeiten und in Informationen umzuwandeln. Zu diesem Zweck muss die Datenbank manipuliert werden, einschließlich Abfragen der Datenbank zum Abrufen bestimmter Daten, Aktualisieren der Datenbank und Generieren von Berichten.
Berichte enthalten Informationen, d. h. verarbeitete Daten. Das DBMS ist auch für die Gewährleistung der Datensicherheit und -integrität verantwortlich.
Einige der Vorteile der Verwendung eines DBMS:
Normalerweise müssen die meisten Programme so gestaltet werden, dass sie Daten speichern können, dieses Problem wird vom DBMS gehandhabt, indem komplexe Datenstrukturen erstellt werden, und dieser Prozess wird als Datenverwaltung bezeichnet.
Das DBMS bietet Funktionen zum Definieren der Struktur der Daten in der Anwendung. Dazu gehören das Definieren und Ändern der Struktur der Datensätze, der Datentypen und -größen der Felder sowie der Einschränkungen und Bedingungen, die jedes Feld erfüllen muss.
Sobald die Datenstruktur definiert ist, müssen die Daten hinzugefügt, aktualisiert und gelöscht werden können. Diese Funktionen sind Teil des DBMS. Diese Funktionen können geplante und ungeplante Datenbearbeitungsanfragen verarbeiten. Geplante Abfragen sind diejenigen aus dem Feature der Anwendung der Anwendung. Ungeplante Abfragen sind Ad-hoc-Abfragen, die nach Bedarf ausgeführt werden.
Datensicherheit ist eines der wichtigsten Merkmale, wenn die Datenbank in einer Mehrbenutzerumgebung verwendet wird. Benutzerdatenzugriffsprüfungen sind erforderlich. Die Datenbank legt die Regeln fest, welche Benutzer auf die Datenbank zugreifen können, auf welche Datenelemente der Benutzer zugreifen kann oder die Operationen mit den Daten, die der Benutzer ausführen kann.
Die Daten in der Datenbank sollten möglichst wenige Fehler enthalten. Beispielsweise sollte der Studentenausweis immer gültig sein und darf nicht leer sein. Telefonnummern sollten nur Zahlen enthalten. Diese können über das DBMS überprüft werden.
Die Datenwiederherstellung im Falle eines Systemausfalls und der gleichzeitige Zugriff auf Datensätze durch mehrere Benutzer können vom DBMS problemlos gehandhabt werden
Die Optimierung der Abfrageleistung ist eine der wichtigen Funktionen eines DBMS. Daher verfügt DBMS über eine Reihe von Programmen, die bei der Standardisierung und Optimierung der Leistung helfen. Kurz gesagt, DBMS errät verschiedene Abfrageimplementierungen und wählt die optimalste zu verwendende Lösung aus.
Zu jeder Zeit können mehrere Benutzer auf dieselben trene DB-Daten zugreifen, das DBMS ist für die gemeinsame Nutzung der Daten zwischen verschiedenen Benutzern verantwortlich und trägt so zur Wahrung der Datenintegrität bei.
Die DBMS-Abfragesprache implementiert die Datenzugriffslösung. SQL ist die am häufigsten verwendete Abfragesprache. Eine Abfragesprache ist eine nicht -prozedurale Sprache , was bedeutet, dass der Benutzer abfragt, was gewünscht wird, und nicht angeben muss, wie es zu tun ist.
Beispiel: Nehmen Sie eine Liste der 10 Schüler mit den höchsten Punktzahlen in der Schülerdatenbank, mit SQL, ganz zu schweigen von der Syntax-Perspektive, die Bedeutung der Anweisung wäre einfach, mir die 10 Schüler mit den höchsten Punktzahlen sortiert von oben zu geben zu niedrig, aber für prozedurale Sprachen müssen wir dies der Reihe nach tun: Nehmen Sie das Schülerarray heraus, sortieren Sie es in einer Schleife von oben nach unten und nehmen Sie dann die ersten 10 Elemente heraus.
Datenbanken können nach Funktionen und Datenmodellen unterschieden werden. Das Datenmodell beschreibt einen Container zum Speichern von Daten und den Prozess zum Speichern und Abrufen von Daten aus diesem Container. Die Analyse und Gestaltung von Datenmodellen ist die Basis der Entwicklung von Datenbanken.
In diesem Modell enthält die Datenbank nur eine Tabelle oder eine Datei. Dieses Modell wird für einfache Datenbanken verwendet. Sie möchten beispielsweise Rollennummer, Name, Fach und Note einer Gruppe von Schülern speichern. Dieses Modell kann keine komplexen Daten verarbeiten. Dieses Muster kann die Ursache für Datenredundanz sein, wenn Daten mehr als einmal wiederholt werden.

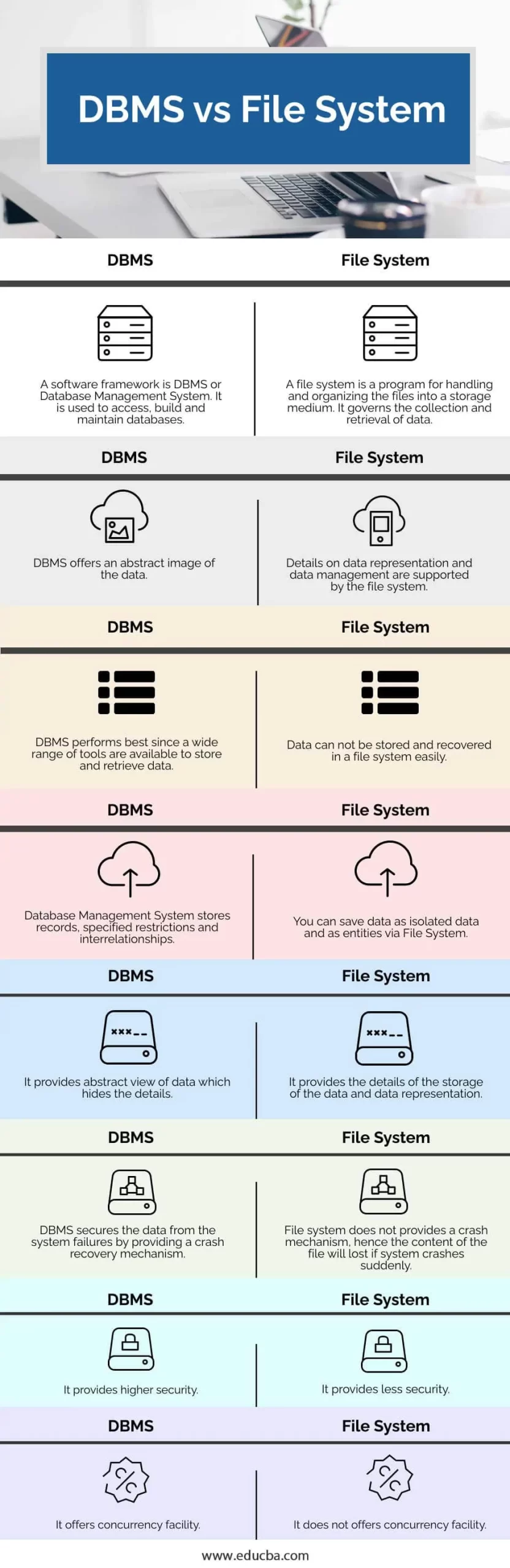
In einem hierarchischen Datenmodell sind verschiedene Datensätze durch eine Hierarchie oder Baumstruktur miteinander verbunden. In diesem Modell erfolgt die Beziehung durch Eltern-Kind-Terme oder -Strukturen. Aber die untergeordnete Struktur hat nur einen Elternteil. Um in diesem Modell nach Daten zu suchen, müssen die Benutzer die hierarchische Struktur der Daten verstehen.
Die Windows-Registrierung ist ein Beispiel für eine abgestufte Datenbank, in der die Konfiguration und Einstellungen des Windows-Betriebssystems gespeichert werden.
Dieses Modell ist äußerst effektiv, wenn die Datenbank eine große Datenmenge enthält.
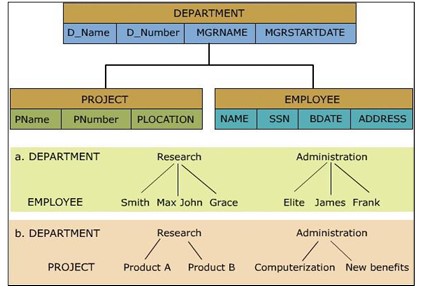
Dieses Modell ähnelt dem Schichtmodell. Das geschichtete Modell ist im Wesentlichen eine Teilmenge des Netzwerkmodells. Anstatt hierarchische Eltern-Kind-Bäume zu verwenden, verwendet das Netzwerkmodell jedoch die Mengenlehre, um ein hierarchisches Modell bereitzustellen, mit der Ausnahme, dass die Kindtabelle mehr als einen Elternteil zulässt.
Im Netzwerkmodell werden Daten in Aggregationen und nicht in einem geschichteten Format gespeichert. Damit ist das Redundanzproblem gelöst. Die Datensätze werden also über verknüpfte Listen auf die physische Verbindung hochgeladen.
Einige Firmen entwickeln Netzwerkdatenmodelle:
https://en.wikipedia.org/wiki/IDMS
Das Netzwerkmodell und das hierarchische Datenmodell waren früher die Hauptdatenmodelle für die Implementierung vieler kommerzieller DBMS. Die Netzwerkmodellkonstrukte und Sprachkonstrukte wurden vom Conference/ Committee on Data Systems Languages (CODASYL) Committee on Data Systems Languages definiert.
Für jede Datenbank werden die Definition des Datenbanknamens, der Datensatztyp für jeden Datensatz und die Komponenten, aus denen diese Datensätze bestehen, gespeichert, die als Netzwerkschema bezeichnet werden. Der Teil der Datenbank, den das Anwendungsprogramm sieht, besteht tatsächlich aus den gewünschten Informationen aus dem Datencontainer in der Datenbank, der als Subschema bezeichnet wird. Es ermöglicht Anwendungsprogrammen, auf angeforderte Daten aus der Datenbank zuzugreifen.
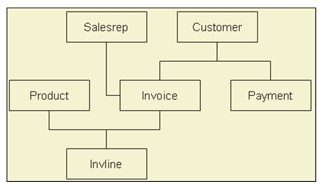
In diesem Modell können wir einfach auf Daten zugreifen und die Anwendung kann auch auf Eigentümerdatensätze und Mitgliederdatensätze in einem Satz zugreifen. Das Netzwerkmodell erlaubt es Mitgliedern nicht, ohne Eigentümer zu existieren, was die Datenintegrität sicherstellt.
Das Design oder die Struktur dieses Modells ist nicht benutzerfreundlich . Dieses Modell hat keinen automatischen Abfrageoptimierungsbereich, die Abfrageleistung hängt stark von den Fähigkeiten, der Erfahrung und dem Algorithmus des Programmierers ab. Dieses Modell erreicht keine strukturelle Unabhängigkeit, obwohl das Netzwerkdatenbankmodell in der Lage ist, Datenunabhängigkeit zu erreichen.
Aufgrund der wachsenden Notwendigkeit, mit Informationen zu arbeiten, und der zunehmenden Komplexität der Entwicklung von Anwendungen, die mit Datenbanken arbeiten, wird das Entwerfen, Verwalten und Interagieren mit Daten immer umständlicher. Aufgrund fehlender Abfragemöglichkeiten brauchten Programmierer viel Zeit, um selbst die einfachsten Berichte zu erstellen, was zur Entwicklung des Konzepts führte, das als relationale Modelldatenbank bekannt ist.
Der Begriff „Relation“ leitet sich aus der mathematischen Mengenlehre ab. In diesem Modell gibt es im Gegensatz zu den hierarchischen und Netzwerkmodellen überhaupt keine physische Verbindung (Eltern-Kind-Baummodell wird als Assoziation verstanden). Alle Daten werden in einer Tabellenvorlage gespeichert, die aus Zeilen und Spalten besteht. Die Daten in den beiden Tabellen sind durch gemeinsame Spalten anstelle von physischen Verknüpfungen (übergeordnet und untergeordnete) miteinander verknüpft. Der Programmierer verwendet die bereitgestellte Syntax oder Softwareschnittstelle, um mit den Zeilen oder Datensätzen in der Tabelle zu arbeiten.
Zu den bekanntesten relationalen Datenbanken gehören: Oracle (Mysql) , Sybase, DB2, Posgres, Microsoft SQL Server ...
Dieses Modell repräsentiert die Datenbank als eine Sammlung von Beziehungen. In diesem Modellbegriff können Zeilen auch als Tupel bezeichnet werden (unübersetzt, siehe Wiki: https://en.wikipedia.org/wiki/tuple , Spalten sind Attribute), Tabellen werden als Relationen (Relationship) bezeichnet, die Liste der verwendeten Werte zu den Feldern wird als Domäne bezeichnet, die Anzahl der Attribute der Beziehung wird als Grad der Beziehung bezeichnet. Die Anzahl der Tupel (Werte) von Feldern) bestimmt die Art der Beziehung.
Das ist die Theorie, Brüder, merkt euch das einfach zum leichteren Verständnis:
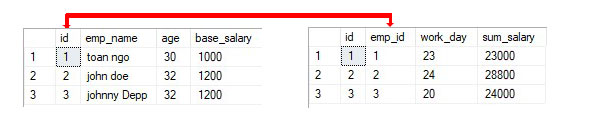
Zum Beispiel 2 Tabellen zur Darstellung einer einfachen HR-Berechnung:
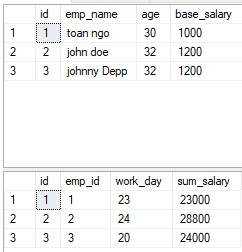
Das relationale Datenbankmodell gibt Programmierern Zeit, sich auf die logische Ansicht der Datenbank zu konzentrieren, anstatt sich um die physische Ansicht zu kümmern. Einer der Gründe für Flexibilität. Die meisten relationalen Datenbanken verwenden die strukturierte Abfragesprache (SQL). Das RDBMS verwendet SQL, um die Abfrage des Benutzers in den technischen Code zu übersetzen, der zum Abrufen der angeforderten Daten erforderlich ist. Das relationale Modell ist so einfach zu handhaben, dass selbst Ungeschulte problemlos praktische Abfragen und Berichte erstellen können, ohne die vielen Anforderungen, die zum Entwerfen einer richtigen Datenbank erforderlich sind.
Das relationale Modell ist ein Versuch, die Datenbankstruktur zu vereinfachen. Es antwortet auf alle Daten in der Datenbank als einfache zeilenfarbene Datenwerttabellen. Ein RDBMS ist ein Softwareprogramm, das relationale Datenbanken erstellt, verwaltet und manipuliert. Eine relationale Datenbank ist eine Datenbank, die in logische Einheiten namens Tabellen unterteilt ist, wobei die Tabellen in der Datenbank miteinander in Beziehung stehen.
Die Tabelle ist in einer relationalen Datenbank verknüpft, sodass vollständige Daten in einer einzigen Abfrage abgerufen werden können (ersetzen Sie gewünschte Daten, die möglicherweise in mehreren Tabellen vorhanden sind). Durch gemeinsame Schlüssel oder Felder zwischen relationalen Datenbanktabellen können Daten aus mehreren Tabellen aus einer großen Ergebnismenge kombiniert werden
Eine relationale Datenbank ist also eine Datenbank, die nach dem relationalen Modell strukturiert ist. Das grundlegende Merkmal eines relationalen Modells besteht darin, dass in einem relationalen Modell Daten in Relationen gespeichert werden.
| Regeln | Sinnvoll |
| Beziehung | Tafel |
| Tupel | Zeile oder Datensatz in der Tabelle |
| Attribut | Feld oder Spalte in einer Tabelle |
| Kardinalität einer Relation | Anzahl der Datensätze in der Tabelle |
| Grad der Beziehungen | Anzahl der Tabellenattribute |
| Domäne eines Attributs | Menge aller möglichen Werte, die vom Attribut verwendet werden |
| Primärschlüssel einer Relation | Ein Attribut oder eine Kombination von Attributen, die jedes Tupel in einer Beziehung eindeutig identifiziert (Tabelle) |
| Fremdschlüssel (Fremdschlüssel) | Ein Attribut oder eine Kombination von Attributen, die die Beziehung zwischen Tabellen definiert |
Das Hauptziel eines Datenbanksystems besteht darin, eine Umgebung zum Abrufen von Informationen aus der Datenbank und zum Speichern neuer Informationen in der Datenbank bereitzustellen.
Bei einer kleinen persönlichen Datenbank definiert normalerweise eine Person die Strukturen und Operationen mit der Datenbank
RDBMS bietet jedoch Funktionen, die mehreren Benutzern helfen, sich an der Gestaltung, Verwendung und Wartung einer großen Datenbank zu beteiligen.
In der Lage zu sein, sie als reale Objekte wie Personen, Orte, Dinge, Objekte oder einfach eine Idee zu visualisieren, wird eindeutig identifiziert. Entitäten in einer Schule können beispielsweise Schüler, Lehrer, Ausbildungspersonal, Fächer usw. sein.
Jede Entität hat einzigartige Merkmale, die als Attribute bezeichnet werden. Beispielsweise kann die Studentenentität Attribute wie Studenten-ID, Name, Punktzahl usw. enthalten. Jedes Attribut hat einen geeigneten Namen zur Beschreibung.
Eine Gruppe verwandter Entitäten wird als Entitätsmenge bezeichnet. Jede Entität hat einen eindeutigen Namen, der Name der Entität spiegelt den Inhalt und die darin gespeicherten Daten wider. Daher werden die Eigenschaften aller Schüler der Schule in dem Objekt mit dem Namen student gespeichert
Datenzugriff und -bearbeitung werden erleichtert, indem Datenbeziehungen basierend auf einer als Tabelle bezeichneten Struktur erstellt werden. Die Tabelle enthält Gruppen verwandter Entitäten, die den Entitätssatz darstellen. Menschen verwenden Tabellen als Namen, um Entitäten zu ersetzen. Tabellen sind Relationen, Zeilen sind Tupel, Spalten sind Attribute.
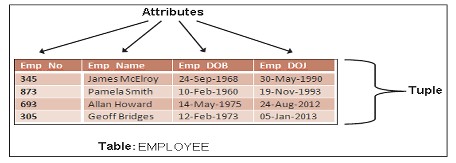
Die Eigenschaften des Tisches unterliegen folgenden Kriterien:
| DBMS | RDBMS |
| Es sind weder Daten in einer tabellarischen Struktur noch tabellarische Beziehungen zwischen Datenelementen erforderlich. | In einem RDBMS ist eine Tabellenstruktur ein Muss, und Tabellenbeziehungen ermöglichen es Benutzern, Geschäftsregeln anzuwenden und zu verwalten und die Arbeit und Komplexität des Schreibens von Code zu reduzieren. |
| Daten können in einer kleinen Größe gespeichert und abgerufen werden | Daten können in großen Größen gespeichert und abgerufen werden |
| Weniger Sicherheit | Höhere Sicherheit |
| Einplatzsystem | Mehrbenutzersystem |
| Die meisten DBMS unterstützen keine Client/Server-Architektur | Unterstützung der Client/Server-Architektur |
In einem RDBMS wird einer Beziehung mehr Bedeutung beigemessen. Infolgedessen können die Tabellen im abhängigen RDBMS und der Benutzer unterschiedliche Integritätsbedingungen für diese Tabellen einrichten, sodass die vom Benutzer verbrauchten endgültigen Daten korrekt bleiben. Im Falle eines DBMS wird Objekten mehr Bedeutung beigemessen und es gibt keine stabile Beziehung zwischen diesen Entitäten.
Ich hoffe, Sie verstehen in diesem Artikel den Unterschied und die Entwicklungsgeschichte der Datenbank bis heute. Wenn der Artikel Fehler enthält, kommentieren Sie ihn bitte unten, damit das Team ihn aktualisieren kann, und zögern Sie nicht, Fragen zu stellen. Viel Glück mit Ihrem Studium!
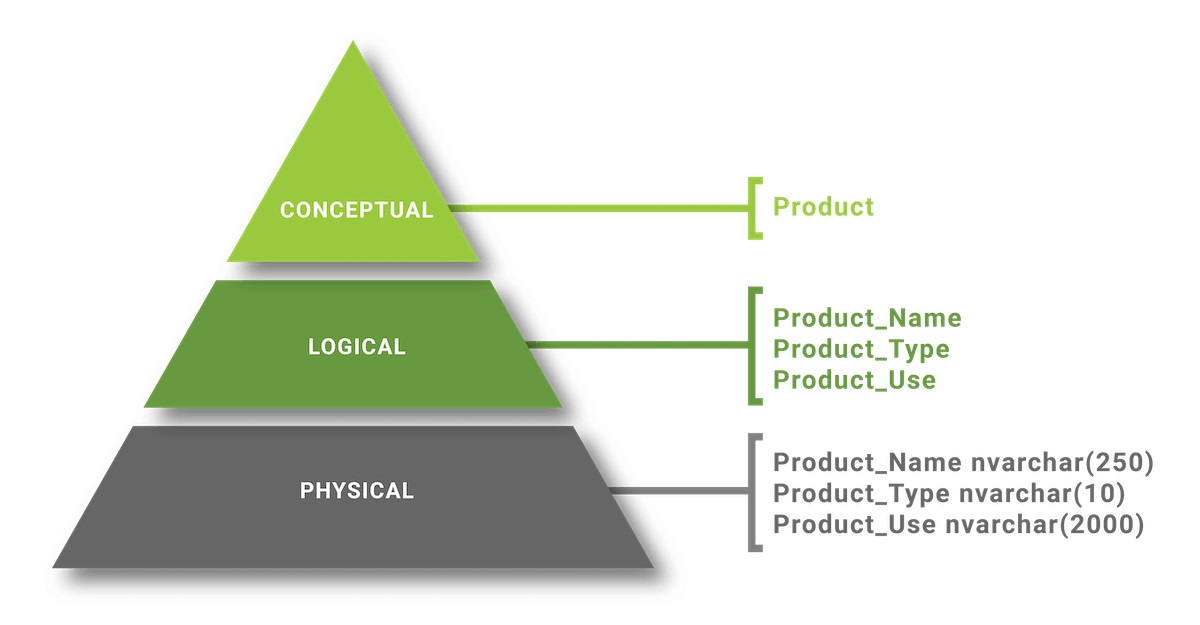
Ein Datenmodell ist eine Gruppe von konzeptionellen Werkzeugen, die verwendet werden, um Daten, ihre Beziehungen und ihre Bedeutungen zu beschreiben. Sie beinhalten auch Konsistenzeinschränkungen, denen die Daten folgen sollten. Im Entity-Relationship-Modell sind die Netzwerkbeziehung oder das hierarchische Modell Beispiele für Datenmodelle, siehe den Artikel Einführung in Datenbankmodelle, stellen Sie das RDBMS-Konzept (Related Database Management System) […]

Anweisungen zum Hinzufügen, Aktualisieren oder Löschen von Feldern (Eingabefeldern) auf der WooCommerce-Kasse-Seite durch verfügbare Filter
Heute habe ich ein Projekt, das ein Feld zur Woocommerce-Kasse hinzufügen muss. Wenn ich den Kern direkt bearbeite, sagen Sie nicht, dass mir jedes Mal, wenn ich den Code aktualisiere, die Luft wegbleibt, also ist es bequem für mich, es so umzuschreiben dass ihr in Zukunft Zeit sparen könnt.
Dokumente: https://woocommerce.com/document/tutorial-customising-checkout-fields-using-actions-and-filters/
Die Erklärung ist, dass es auf der normalen Woocommerce-Checkout-Seite 2 Spalten mit einer Liste von Eingabefeldern gibt, die erste Spalte ist die Rechnungsstellung, die zweite Spalte die Lieferadresse. Alle von ihnen werden in einer Array-Variablen gespeichert, wir können Felder hinzufügen, aktualisieren, löschen, um Eingaben zum Woocommerce-Formular hinzuzufügen, indem wir die Funktion verwenden:
add_filter('woocommerce_checkout_fields', 'custom_override_checkout_fields'); function custom_override_checkout_fields($fields) { /* todo, biến fields là biến mảng có cấu trúc, bên trong là các phần tử billing,shipping,account,order và các phần tử này lại là các mảng con, mô tả cấu trúc của các fields nhập liệu khi người dùng checkout */ }if dump würde die durch den Filter erfasste $fields-Variable wie folgt strukturiert sein:
array(4) { ["billing"]=> array(11) { ["billing_first_name"]=> array(5) { ["label"]=> string(4) "Tên" ["required"]=> bool(true) ["class"]=> array(1) { [0]=> string(14) "form-row-first" } ["autocomplete"]=> string(10) "given-name" ["priority"]=> int(10) } ["billing_last_name"]=> array(5) { ["label"]=> string(4) "Họ" ["required"]=> bool(true) ["class"]=> array(1) { [0]=> string(13) "form-row-last" } ["autocomplete"]=> string(11) "family-name" ["priority"]=> int(20) } ["billing_company"]=> array(5) { ["label"]=> string(13) "Tên công ty" ["class"]=> array(1) { [0]=> string(13) "form-row-wide" } ["autocomplete"]=> string(12) "organization" ["priority"]=> int(30) ["required"]=> bool(false) } ["billing_country"]=> array(6) { ["type"]=> string(7) "country" ["label"]=> string(16) "Country / Region" ["required"]=> bool(true) ["class"]=> array(3) { [0]=> string(13) "form-row-wide" [1]=> string(13) "address-field" [2]=> string(23) "update_totals_on_change" } ["autocomplete"]=> string(7) "country" ["priority"]=> int(40) } ["billing_address_1"]=> array(6) { ["label"]=> string(12) "Địa chỉ" ["placeholder"]=> string(12) "Địa chỉ" ["required"]=> bool(true) ["class"]=> array(2) { [0]=> string(13) "form-row-wide" [1]=> string(13) "address-field" } ["autocomplete"]=> string(13) "address-line1" ["priority"]=> int(50) } ["billing_address_2"]=> array(5) { ["placeholder"]=> string(39) "Apartment, suite, unit, etc. (optional)" ["class"]=> array(2) { [0]=> string(13) "form-row-wide" [1]=> string(13) "address-field" } ["autocomplete"]=> string(13) "address-line2" ["priority"]=> int(60) ["required"]=> bool(false) } ["billing_postcode"]=> array(6) { ["label"]=> string(16) "Mã bưu điện" ["required"]=> bool(false) ["class"]=> array(2) { [0]=> string(13) "form-row-wide" [1]=> string(13) "address-field" } ["validate"]=> array(1) { [0]=> string(8) "postcode" } ["autocomplete"]=> string(11) "postal-code" ["priority"]=> int(65) } ["billing_city"]=> array(5) { ["label"]=> string(21) "Tỉnh / Thành phố" ["required"]=> bool(true) ["class"]=> array(2) { [0]=> string(13) "form-row-wide" [1]=> string(13) "address-field" } ["autocomplete"]=> string(14) "address-level2" ["priority"]=> int(70) } ["billing_state"]=> array(9) { ["type"]=> string(5) "state" ["label"]=> string(12) "Bang / Hạt" ["required"]=> bool(false) ["class"]=> array(2) { [0]=> string(13) "form-row-wide" [1]=> string(13) "address-field" } ["validate"]=> array(1) { [0]=> string(5) "state" } ["autocomplete"]=> string(14) "address-level1" ["priority"]=> int(80) ["country_field"]=> string(15) "billing_country" ["country"]=> string(2) "VN" } ["billing_phone"]=> array(7) { ["label"]=> string(20) "Số điện thoại" ["required"]=> bool(true) ["type"]=> string(3) "tel" ["class"]=> array(1) { [0]=> string(13) "form-row-wide" } ["validate"]=> array(1) { [0]=> string(5) "phone" } ["autocomplete"]=> string(3) "tel" ["priority"]=> int(100) } ["billing_email"]=> array(7) { ["label"]=> string(18) "Địa chỉ email" ["required"]=> bool(true) ["type"]=> string(5) "email" ["class"]=> array(1) { [0]=> string(13) "form-row-wide" } ["validate"]=> array(1) { [0]=> string(5) "email" } ["autocomplete"]=> string(14) "email username" ["priority"]=> int(110) } } ["shipping"]=> array(9) { ["shipping_first_name"]=> array(5) { ["label"]=> string(4) "Tên" ["required"]=> bool(true) ["class"]=> array(1) { [0]=> string(14) "form-row-first" } ["autocomplete"]=> string(10) "given-name" ["priority"]=> int(10) } ["shipping_last_name"]=> array(5) { ["label"]=> string(4) "Họ" ["required"]=> bool(true) ["class"]=> array(1) { [0]=> string(13) "form-row-last" } ["autocomplete"]=> string(11) "family-name" ["priority"]=> int(20) } ["shipping_company"]=> array(5) { ["label"]=> string(13) "Tên công ty" ["class"]=> array(1) { [0]=> string(13) "form-row-wide" } ["autocomplete"]=> string(12) "organization" ["priority"]=> int(30) ["required"]=> bool(false) } ["shipping_country"]=> array(6) { ["type"]=> string(7) "country" ["label"]=> string(16) "Country / Region" ["required"]=> bool(true) ["class"]=> array(3) { [0]=> string(13) "form-row-wide" [1]=> string(13) "address-field" [2]=> string(23) "update_totals_on_change" } ["autocomplete"]=> string(7) "country" ["priority"]=> int(40) } ["shipping_address_1"]=> array(6) { ["label"]=> string(12) "Địa chỉ" ["placeholder"]=> string(12) "Địa chỉ" ["required"]=> bool(true) ["class"]=> array(2) { [0]=> string(13) "form-row-wide" [1]=> string(13) "address-field" } ["autocomplete"]=> string(13) "address-line1" ["priority"]=> int(50) } ["shipping_address_2"]=> array(5) { ["placeholder"]=> string(39) "Apartment, suite, unit, etc. (optional)" ["class"]=> array(2) { [0]=> string(13) "form-row-wide" [1]=> string(13) "address-field" } ["autocomplete"]=> string(13) "address-line2" ["priority"]=> int(60) ["required"]=> bool(false) } ["shipping_postcode"]=> array(6) { ["label"]=> string(16) "Mã bưu điện" ["required"]=> bool(false) ["class"]=> array(2) { [0]=> string(13) "form-row-wide" [1]=> string(13) "address-field" } ["validate"]=> array(1) { [0]=> string(8) "postcode" } ["autocomplete"]=> string(11) "postal-code" ["priority"]=> int(65) } ["shipping_city"]=> array(5) { ["label"]=> string(21) "Tỉnh / Thành phố" ["required"]=> bool(true) ["class"]=> array(2) { [0]=> string(13) "form-row-wide" [1]=> string(13) "address-field" } ["autocomplete"]=> string(14) "address-level2" ["priority"]=> int(70) } ["shipping_state"]=> array(9) { ["type"]=> string(5) "state" ["label"]=> string(12) "Bang / Hạt" ["required"]=> bool(false) ["class"]=> array(2) { [0]=> string(13) "form-row-wide" [1]=> string(13) "address-field" } ["validate"]=> array(1) { [0]=> string(5) "state" } ["autocomplete"]=> string(14) "address-level1" ["priority"]=> int(80) ["country_field"]=> string(16) "shipping_country" ["country"]=> string(2) "VN" } } ["account"]=> array(0) { } ["order"]=> array(1) { ["order_comments"]=> array(4) { ["type"]=> string(8) "textarea" ["class"]=> array(1) { [0]=> string(5) "notes" } ["label"]=> string(20) "Ghi chú đơn hàng" ["placeholder"]=> string(107) "Ghi chú về đơn hàng, ví dụ: thời gian hay chỉ dẫn địa điểm giao hàng chi tiết hơn." } } }Woocommerce integriert und aktualisieren Sie die Feldvariable, indem Sie ein Element hinzufügen oder ein vorhandenes Element aktualisieren. Das Beispielcodebeispiel sieht wie folgt aus, um ein Feld mit der Bezeichnung „Geburtstag“ und dem Datum hinzuzufügen, damit der Benutzer das Datum auswählen kann:
// Hook in add_filter('woocommerce_checkout_fields', 'custom_override_checkout_fields'); // Our hooked in function - $fields is passed via the filter! function custom_override_checkout_fields($fields) { // add birthday fields $fields['billing']['birthday'] = array( 'label' => __('Birthday', 'woocommerce'), // nội dung text thẻ label cho input 'type' => 'date', // type của input 'required' => false, // trường required hay không 'class' => array('form-row-wide'), // class html trong input 'clear' => true ); return $fields; }Nach dem Hinzufügen des Feldes müssen wir beim Aktualisieren die Daten im benutzerdefinierten Feld in der Datenbank für die Bestellung speichern
/** * Update the order meta with field value */ add_action( 'woocommerce_checkout_update_order_meta', 'my_custom_checkout_field_update_order_meta' ); function my_custom_checkout_field_update_order_meta( $order_id ) { if ( ! empty( $_POST['birthday'] ) ) { update_post_meta( $order_id, 'birthday', sanitize_text_field( $_POST['birthday'] ) ); } }Sobald Sie die Daten in der Datenbank haben, verwenden Sie den folgenden Code, um die Backend-Bestellung anzuzeigen
/** * Display field value on the order edit page */ add_action( 'woocommerce_admin_order_data_after_billing_address', 'my_custom_checkout_field_display_admin_order_meta', 10, 1 ); function my_custom_checkout_field_display_admin_order_meta($order){ echo '<p><strong>'.__('Sinh nhật').':</strong> ' . get_post_meta( $order->id, 'birthday', true ) . '</p>'; }Wenn Sie die Daten auch in der Quickview-Reihenfolge im Backend anzeigen möchten, beziehen Sie sich auf den folgenden Code:
/** * Add to quickview order */ add_filter( 'woocommerce_admin_order_preview_get_order_details', 'admin_order_preview_add_custom_billing_data', 10, 2 ); function admin_order_preview_add_custom_billing_data( $data, $order ) { $custom_billing_data = []; // initializing // Custom field 1: Replace '_custom_meta_key1' by the correct custom field metakey if( $custom_value1 = $order->get_meta('birthday') ) { $custom_billing_data[] = $custom_value1; } ## ……… And so on (for each additional custom field). // Check that our custom fields array is not empty if( count($custom_billing_data) > 0 ) { // Converting the array in a formatted string $formatted_custom_billing_data = implode( '<br>', $custom_billing_data ); if( $data['formatted_billing_address'] === __( 'N/A', 'woocommerce' ) ) { $data['formatted_billing_address'] = $formatted_custom_billing_data; } else { $data['formatted_billing_address'] .= '<br>' .'<strong>Sinh nhật</strong>'. $formatted_custom_billing_data; } } return $data; }Der obige Code ist verfügbar unter: https://stackoverflow.com/questions/57846511/show-custom-fields-in-woocommerce-quick-order-preview
Viel Glück !
Erweiterte Abfrageanweisungen und eine Einführung in SQL-Aggregatfunktionen, eine Einführung in AVG(),SUM(), Min(),MAX(),COUNT() in SQL Server
Sql Server-Fehlerbehandlungshandbuch, in dem Try-Catch-Blöcke und Systemfunktionen vorgestellt werden, die Fehler in SQL Server darstellen
Metadaten und dynamisches Verwaltungsobjekt in SQL Server abfragen

Einführung in die Programmiersprache PHP, die Entwicklungsgeschichte von PHP und ein kurzer Überblick über die Unterschiede zwischen PHP und Javascript
Verbesserungen von PHP 8 im Vergleich zu PHP 7 und Einführung des Just-In-Time-Compilers zur Steigerung der Ausführungsleistung in PHP 8
Eine PHP-Laufzeitumgebung installieren und PHP-Grundlagen für Einsteiger Schritt für Schritt ausführlich einführen.
So installieren Sie PHP manuell auf MacOS über Homebrew
PHP manuell auf Linux- und Unix-Betriebssystemen installieren

hocvietcode.com là website chia sẻ và cập nhật tin tức công nghệ, chia sẻ kiến thức, kỹ năng. Chúng tôi rất cảm ơn và mong muốn nhận được nhiều phản hồi để có thể phục vụ quý bạn đọc tốt hơn !
Liên hệ quảng cáo: trienkhaiweb@gmail.com