
Datenvorverarbeitung im maschinellen Lernen, konkretes Beispiel.
Die Datenvorverarbeitung ist ein unverzichtbarer Schritt beim Machline Learning, denn wie Sie wissen, sind Daten ein sehr wichtiger Bestandteil, der sich direkt auf das Trainingsmodell auswirkt. Daher ist es sehr wichtig, die Daten vorzuverarbeiten, bevor sie in das Modell eingefügt werden, um die fehlenden Daten zu entfernen oder zu kompensieren.
In diesem Artikel werde ich Ihnen helfen, zu verstehen, wie die Daten verarbeitet werden, bevor Sie in das Modell eintreten, und zwar anhand eines konkreten Beispiels, nicht nur durch trockene Theorie.
Der erste ist definitiv ein Datensatz für Sie zum Üben.
Mục lục
Daten vorbereiten.
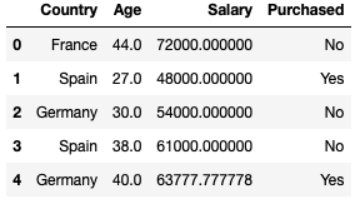
Die Daten erhalten Sie unter folgendem Link. Dann sind dies einfach Daten, die aus 10 Zeilen und 4 Spalten bestehen. Später werden Sie verstehen, warum ich die Daten von 10 Zeilen zur Ausführung ausgewählt habe. Statistische Daten zum Autokaufverhalten einer Reihe von Personen in verschiedenen Ländern mit unterschiedlichem Alter und Gehalt. Es gibt auch einige verlorene Daten.
dataset = pd.read_csv("data.csv") Country Age Salary Purchased 0 France 44.0 72000.0 No 1 Spain 27.0 48000.0 Yes 2 Germany 30.0 54000.0 No 3 Spain 38.0 61000.0 No 4 Germany 40.0 NaN Yes 5 France 35.0 58000.0 Yes 6 Spain NaN 52000.0 No 7 France 48.0 79000.0 Yes 8 Germany 50.0 83000.0 No 9 France 37.0 67000.0 YesDatentrennung
Funktionshandhabung .iloc[] in pandas.core, um die Daten aufzuteilen, zu bestimmen, was Features sind und was ausgegeben wird.
Beispiel: X = dataset.iloc[:3, :-1] // aus den oberen 3 Zeilen schneiden und die letzte Spalte löschen.
Land Alter Gehalt
0 France 44.0 72000.0 1 Spain 27.0 48000.0 2 Germany 30.0 54000.0 Und um Daten zu verarbeiten, müssen Sie mit der Funktion X = dataset.iloc[:3, :-1].values in ein numpy-Array konvertieren.
Datenvorverarbeitung
Hier sind einige der Konzepte, die ich in diesem Artikel verwendet habe:
- Umgang mit fehlenden Daten
- Standardisierung (Standardverteilung)
- Umgang mit kategorialen Variablen
- One-Hot-Codierung
- Multikollinearität
1. Umgang mit fehlenden Daten
Auf jeder Art von Datensatz auf der Welt gibt es nur wenige Nullwerte. Das ist wirklich nicht gut, wenn Sie Modelle wie Regression oder Klassifizierung oder irgendein anderes Modell verwenden möchten. Hinweis: In Python wird NULL auch durch NAN repräsentiert. Daher können sie austauschbar verwendet werden .
Sie können Ihren eigenen Code implementieren, indem Sie die Elemente jeder Spalte durchlaufen, um zu sehen, welche Spalte das Äquivalent von isnull() und process hat.
In diesem Beispiel zeige ich Ihnen, wie Sie die Sklearn-Bibliothek verwenden können, um den Umgang mit fehlenden Daten zu erleichtern. SimpleImputer ist eine Klasse von Sklearn, die den Umgang mit fehlenden numerischen Daten unterstützt und sie durch einen Durchschnitt der Spalte, die Häufigkeit der sichtbarsten Daten, …
from sklearn.impute import SimpleImputer #Create an instance of Class SimpleImputer: np.nan is the empty value in the dataset imputer = SimpleImputer(missing_values=np.nan, strategy='mean') #Replace missing value from numerical Col 1 'Age', Col 2 'Salary' imputer.fit(X[:, 1:3]) #transform will replace & return the new updated columns X[:, 1:3] = imputer.transform(X[:, 1:3])
2. Kategorische Datenverarbeitung
Encode Independent Variables : Hilft uns, eine Spalte mit Strings in Vektor 0 & 1 umzuwandeln
- Verwenden der ColumnTransformer-Klasse von sklearn und OneHotEncoder.
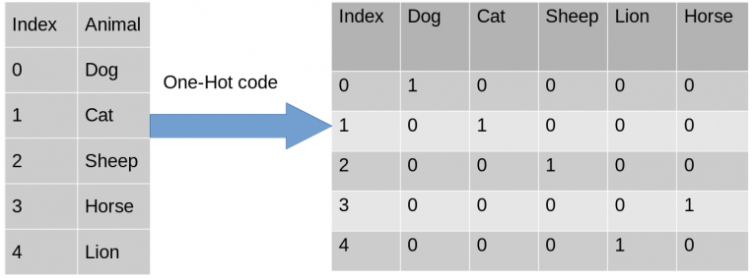
from sklearn.compose import ColumnTransformer from sklearn.preprocessing import OneHotEncoderErstellen Sie ein Tupel (Encoder-Codierungstransformation, Instanz der Klasse OneHotEncoder, [Spalten möchten transformieren) und andere Spalten, mit denen Sie nichts zu tun haben möchten. Sie können rest="passthrough" verwenden, um sie zu überspringen.
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [0])] , rest="passthrough" )Anpassen und transformieren mit input = X und ct Instanz der Klasse ColumnTransformer
#fit und transformiere mit input = X #np.array: muss die Ausgabe von fit_transform() von matrix in np.array umwandeln X = np.array(ct.fit_transform(X))
Nach der Umrechnung erhalten wir France = [1.0,0.0,0.0] was schon One-Hot ist.
Codieren Sie abhängige Variablen : Das heißt, wir müssen die Ausgabeetiketten codieren, damit die Maschine sie verstehen kann.
- Verwenden Sie Label Encoder, um Labels zu codieren
aus sklearn.preprocessing importieren Sie LabelEncoder le = LabelEncoder() #output von fit_transform von Label Encoder ist bereits ein Numpy-Array y = le.fit_transform(y) #y = [0 1 0 0 1 1 0 1 0 1]
Trainingsset und Testset aufteilen
- Verwenden Sie train_test_split von Sklearn-Model Selection, um Zug- und Testdaten aufzuteilen.
- Verwenden Sie den Parameter: test_size=… um die Daten des Testsatzes auf alle Daten aufzuteilen.
- random_state = 1: Hilft bei der Verwendung von Pythons eingebautem Zufallssatz.
aus sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0,2, random_state = 1)
Funktionsskalierung
Warum tritt FS auf: Wenn wir Data Mining betreiben, kann es einige Features geben, die größer sind als andere, sodass kleinere Features definitiv ignoriert werden, wenn wir ML-Modelle erstellen.
# Hinweis 1: FS muss nicht auf Multi-Regressionsmodelle angewendet werden, denn wenn y = b0 + b1*x1 + b2*x2 + … + bn*xn vorhersagt, dann (b0, b1, …, bn) ) sind Koeffizienten zum Kompensieren der Differenz, sodass kein FS benötigt wird.
# Hinweis 2: Für die Codierung der kategorialen Merkmale muss FS nicht angewendet werden.

#Hinweis 3: FS muss nach dem Aufteilen von Trainings- und Testsätzen durchgeführt werden. Denn wenn wir FS verwenden, bevor wir Trainings- und Testsätze aufteilen, verlieren die Daten ihre Korrektheit.
Also, wie man die Skalierung kennzeichnet .
Dazu gibt es zwei Techniken:
- Standardisierung: Transformiert die Daten so, dass der Mittelwert 0 und die Standardabweichung 1 ist.
An diesen Daten können Sie sehen, dass Alter und Gehalt ziemlich unterschiedlich sind, daher dürfen Altersdaten nicht im Modell verwendet werden. Daher müssen wir die Daten normalisieren, um sie auf eine kleinere Zahl zu reduzieren und dennoch die Korrelation der Daten sicherzustellen.
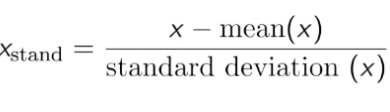
Sie können den StandardScaler von sklearn.preprocessing zu Std für die Daten verwenden.
aus sklearn.preprocessing importieren Sie StandardScaler sc = StandardSkalierer() X_train[:,3:] = sc.fit_transform(X_train[:,3:]) #only use Transform, um den GLEICHEN Skalierer als Trainingssatz zu verwenden X_test[:,3:] = sc.transform(X_test[:,3:])
- Normalisierung: Bewirkt, dass der Datensatz zwischen 0 und 1 schwankt.
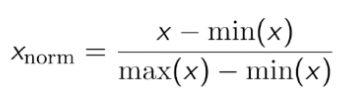
Bài viết liên quan:












Dịch vụ thiết kế Wesbite

