
Einführung in maschinelles Lernen
Mục lục
Warum Maschinelles Lernen lernen?
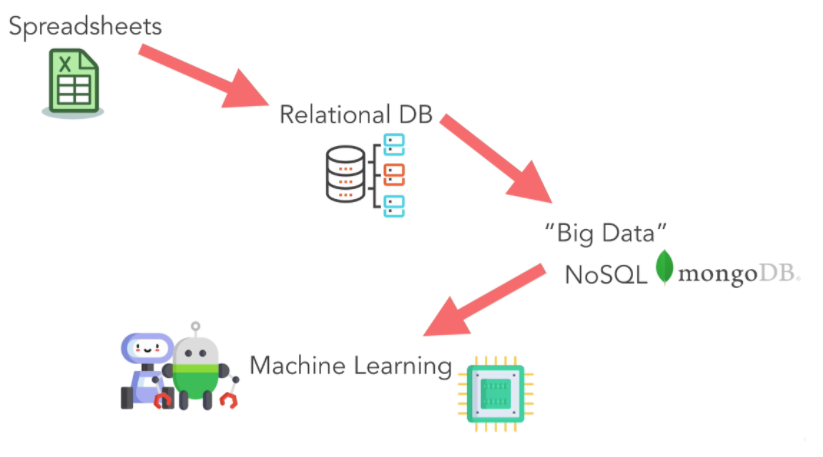
- Tabellenkalkulationen (Excel, CSV): Als Ort zum Speichern der erforderlichen Geschäftsdaten ist dies eines der nützlichsten Tools, die heute verfügbar sind. Hilft uns bei der Analyse und Darstellung der Daten, die ein Unternehmen benötigt.
- Relationale DB (MySQL): Ist ein besserer Datenspeicherort als Tabellenkalkulationen und wird durch Abfrageanweisungen ausgeführt, von denen Unternehmen Anweisungen zum Suchen und Verarbeiten von Daten verwenden können.
- Big Data (NoSQL): FB, Amazon, Shopee, … aufgrund großer Nutzerdaten spricht man von Big Data und hier sind die Daten nicht streng organisiert, daher ist es notwendig, maschinelles Lernen anstelle von Entscheidungsträgern einzusetzen.
Mehrere Bereiche sind mit maschinellem Lernen verbunden.
Künstliche Intelligenz KI?
Künstliche Intelligenz oder künstliche Intelligenz (KI) ist ein Teilgebiet der Informatik. Eine von Menschen geschaffene Intelligenz mit dem Ziel, Computern zu helfen, intelligente Verhaltensweisen wie Menschen zu automatisieren.
Maschinelles Lernen
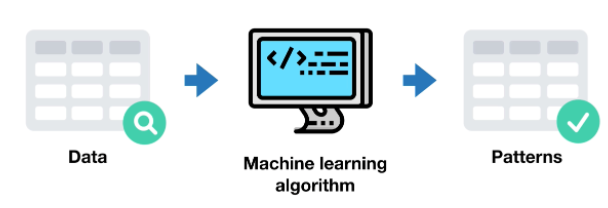
Als Unterzweig der KI verwendet maschinelles Lernen Algorithmen ( Algorithms ) oder Computerprogramme, um verschiedene Daten zu lernen, und verwendet dann den Algorithmus und das, was er zuvor gelernt hat, um eine Vorhersage zu treffen, zu erraten oder basierend auf ähnlichen Daten neu zu klassifizieren.
Beispiel: Kategorisierung oder Produktanalyse.
Unterschied zwischen maschinellem Lernen und normalen Algorithmen
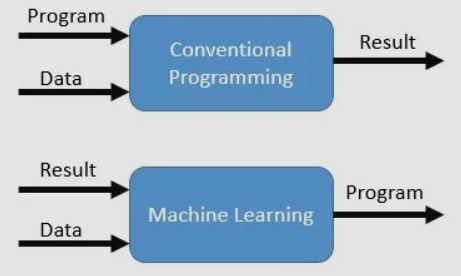
- Normaler Algorithmus: Eingabe + Algorithmus -> Ergebnis (Ausgabe) verwenden.
- Maschinenalgorithmus: Beginnen Sie mit Input und Output -> bestimmen Sie von dort aus das Verhältnis zwischen I/P und O/P.
Einige Probleme beim maschinellen Lernen

Überwacht: Daten mit Labels
zB: Wie Hunde- und Katzendaten, …
Unbeaufsichtigt: Unbeschriftete Daten wie eine Excel-Datei ohne Spaltenüberschriften.
- Clustering: Hilft uns, Gruppen zu clustern. zB: Clustering von Kunden nach Kundenpräferenzen.
- Lernen von Zuordnungsregeln: Zuordnung mehrerer Attribute zur Vorhersage des Kundenverhaltens. zB Was in Zukunft kaufen.
Verstärkung: Bringen Sie der Maschine bei, zu versuchen und zu scheitern, damit sie beim nächsten Mal belohnt wird, um sich zu verbessern. zB: angewendet in alpha go – weltberühmte Schachmaschine.
Tiefes Lernen
Deep Learning ist eine Teilmenge des maschinellen Lernens, das sich in einigen wichtigen Aspekten vom traditionellen flachen maschinellen Lernen unterscheiden kann und es Computern ermöglicht, eine Vielzahl unlösbarer komplexer Probleme zu lösen.
Datenwissenschaft
Datenanalyse: Analysieren Sie Daten von dort, um die erforderlichen Berichte zu erstellen.
Data Science: Führen Sie Tests an Datensätzen durch, um nützliche Informationen zu diesen Daten zu erhalten.
Wie maschinelles Lernen funktioniert

Schritt 1 : Identifizieren Sie das Problem – wandeln Sie den Satz des Kunden in das Problem des maschinellen Lernens um.
Sie müssen bestimmen, was Ihr Problem gelöst werden muss?
- Beaufsichtigt
- Unbeaufsichtigt
- Klassifizierung
- Rückfall
Schritt 2 : Daten: Was ist der vorhandene Datentyp?
Schritt 3 : Bewertung
- Bestimmen Sie, wann der Algorithmus korrekt ist.
- Indikatoren, die beachtet werden müssen, helfen uns bei der Bewertung des Projekts.
Schritt 4: Datenmerkmale (Merkmale)
- Welche Funktionen haben Ihre Daten und welche Funktionen müssen Sie verwenden, um das Modell zu erstellen? Von dort verwandeln Sie die Merkmale in Muster.
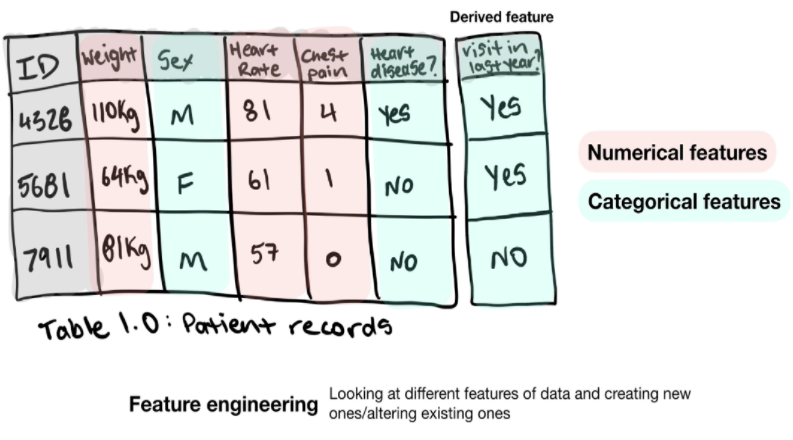
- Es gibt 3 Haupttypen von Funktionen:
- Kategoriale Merkmale: Kann Geschlecht oder ja/nein sein.
- Kontinuierliche (oder numerische) Merkmale: Ein numerischer Wert, z. B. die Nachrichtenspanne oder die Häufigkeit, mit der eine Aktion ausgeführt wird.
- Abgeleitete Features (die Art von Features, die Sie aus Daten erstellen): Wird häufig als Feature-Engineering bezeichnet. Wenn Sie beispielsweise Geschwindigkeit und Zeit aus Ihren Anfangsdaten erhalten, können Sie ein abgeleitetes Feature erstellen, das die zurückgelegte Entfernung darstellt.
Schritt 5 : Modelle
Heutzutage gibt es viele Bibliotheken, die Ihnen helfen, Probleme zu lösen. Es ist wichtig zu bestimmen, wann welches Modell verwendet werden soll.
- Überwachtes Lernen: (Input & Output) Daten + Label → Klassifikationen, Regressionsmodell, …
- Unüberwachtes Lernen: Nur Eingabedaten → Clustering, …
- Reinformendes Lernen: Abschließen und Belohnen: Muss einen Weg finden, ML-Scores zu aktualisieren.
Schritt 6 : Testen, auswerten.
Bitte überprüfen Sie das Modell und verwenden Sie algorithmische Bewertungsmethoden, um festzustellen, ob Ihr Modell korrekt ist und wie genau es ist.
| Einstufung | Rückfall | Empfehlung |
|---|---|---|
| Genauigkeit | Mittlerer absoluter Fehler (MAE) | Präzision bei KY |
| Präzision | Mittlerer quadratischer Fehler (MSE) | |
| Abrufen | Mittlerer quadratischer Fehler (RMSE) |
Einige häufige Probleme bei der maschinellen Lernverarbeitung.

Überanpassung
Wenn der Trainingsdatensatz gut ist und die Testdaten gut sind, ist Ihr allgemeines Modell nicht gut.
Lösung : Versuchen Sie, ein einfacheres Modell zu verwenden, und stellen Sie sicher, dass Ihre Testdaten den gleichen Typ wie die Trainingsdaten haben.
Unterausstattung
Die Leistung der Trainingsdaten ist schlecht, sodass Ihre Daten überhaupt nicht richtig gelernt werden. Führt zu Underfitting.
Lösung: Versuchen Sie erneut, Datentraining und Datentest zu unterteilen, und versuchen Sie, die Parameter der Daten anzupassen.
Bài viết liên quan:












Dịch vụ thiết kế Wesbite

