Erweiterte SQL-Funktionen in SQL Server 2019
Mục lục
Detaillierte Kürzungswarnungen (Ausführliche Kürzungswarnungen)
Dies ist eine der neuen erweiterten Funktionen in SQL Server 2019, die angeboten werden. Es spart Zeit beim Berichten, Hinzufügen neuer und Aktualisieren großer Datenmengen.
Zum Beispiel:
Schritt 1 – Musterdatenbank 2017 erstellen
USE [master] GO CREATE DATABASE [SampleDB2017] GO ALTER DATABASE [SampleDB2017] SET COMPATIBILITY_LEVEL = 140 GOSchritt 2 – Fügen Sie der obigen Datenbank eine Tabelle mit einigen Datensätzen hinzu
USE [SampleDB2017] GO CREATE TABLE [dbo].[tbl_Color]( [ColorID] int IDENTITY not null, [ColorName] varchar(3) NULL ) GO INSERT INTO dbo.tbl_Color (ColorName) values ('Red'), ('Blue'),('Green') GOBei älteren Versionen wird der Fehler wie folgt zurückgegeben:
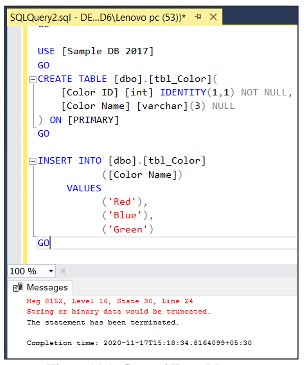
Der Fehler tritt auf, wenn der Datensatz „Green“ in die Spalte mit nvarchar(3)-Daten eingefügt wird, obwohl der Fehler angezeigt wird, aber wenn die Anzahl der Datensätze groß ist, ist es schwierig zu bestimmen, welcher Fehler beim Einfügen welchen Datensatzes aufgetreten ist , in der Session-Version 2019 ist die Fehlermeldung behoben und detaillierter dargestellt, wodurch Fehler leichter identifiziert werden können.
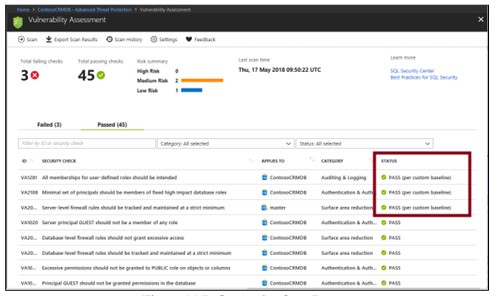
Schwachstellenanalyse
Es ist ein einfach zu konfigurierendes Unternehmen, das Datenbank-Schwachstellen entdeckt, umkehrt oder reduziert.
Datenbankadministratoren können es verwenden, um die Datenbanksicherheit proaktiv zu entwickeln.
Schwachstellenressourcen sind Teil von Azure Defensive for SQL, einem einheitlichen Paket für erweiterte SQL-Sicherheitsfunktionen. Es kann über Azure Defender für das SQL-Portal aufgerufen und verwaltet werden.
Hinweis SQL-Schwachstelle, die in Azure SQL-Datenbank, Azure SQL Managed Instance, Azure Synapse Analytics (SQL Data Warehouse) verwendet wird.
SQL Vulnerability Asset enthält Schritte zur Verbesserung der Datenbanksicherheit und kann Ihnen dabei helfen:
- Erfüllen Sie Compliance-Anforderungen mit Berichtsanforderungen für Datenbank-Scans
- Datenschutzstandards erfüllen
- Überwachen Sie dynamische Datenbankumgebungen, in denen Änderungen schwer nachzuverfolgen sind
Die Regeln basieren auf Best Practices von Microsoft und konzentrieren sich auf Sicherheitsprobleme, die das größte Risiko für Ihre Datenbank und ihre wertvollen Daten darstellen. Die Ergebnisse des Scans umfassen umsetzbare Schritte zur Lösung jedes Problems und bieten anwendbare benutzerdefinierte Reparaturszenarien.
Sie können einen Schwachstellenbericht für die Umgebung anpassen, indem Sie eine Baseline festlegen für:
- Berechtigungen konfigurieren
- Feature-Konfiguration
- Datenbankeinstellungen
Schritte zum Bereitstellen der Schwachstellenbewertung:
Scan ausführen
Hinweis: Der Scanvorgang ist leicht und sicher, er dauert nur wenige Sekunden und der gesamte Scanvorgang ist schreibgeschützt, es werden keine Änderungen in Ihrer Datenbank vorgenommen.
Zeige Bericht
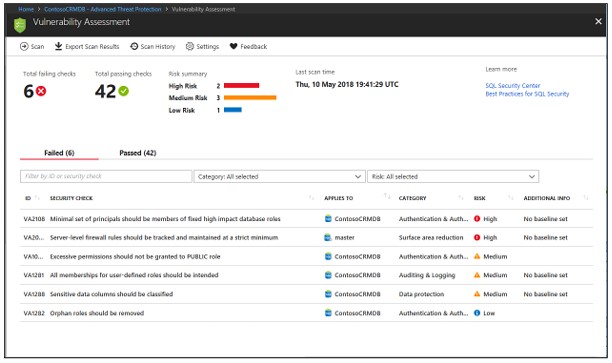
Wenn der Scan abgeschlossen ist, wird der Bericht automatisch im Azure-Portal angezeigt
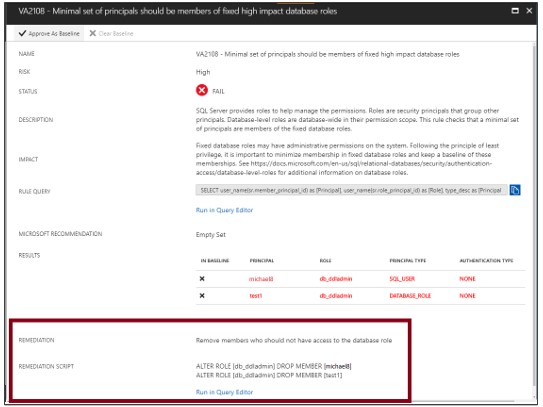
Zu den Ergebnissen gehören Warnungen zu Abweichungen von Best Practices und Snapshots Ihrer sicherheitsrelevanten Einstellungen wie Datenbankrollen und -richtlinien sowie Berechtigungen.
Ergebnisse analysieren und Probleme lösen
Überprüfen Sie die Ergebnisse erneut und stellen Sie im Bericht fest, ob es Probleme in Ihrer Umgebung gibt.
Tauchen Sie in jedes Fehlerergebnis ein, um die Auswirkungen der Erkennung zu verstehen und warum jede Sicherheitsprüfung fehlschlägt.
Verwenden Sie die im Bericht bereitgestellten Informationen zur umsetzbaren Behebung, um das Problem zu beheben.
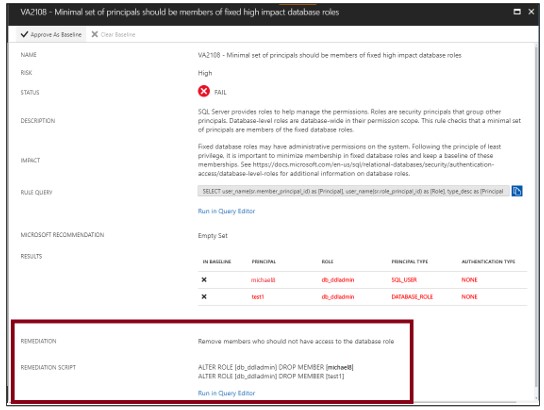
Grundlinie festlegen
Beim Überprüfen Ihrer Bewertungsergebnisse können Sie bestimmte Ergebnisse als akzeptable Baseline markieren. Ergebnisse, die mit der Baseline übereinstimmen, gelten in nachfolgenden Scans als bestanden. Nachdem Sie Ihre Basissicherheit festgelegt haben, meldet die Schwachstellenanalyse nur Abweichungen von der Basislinie.
Ergebnisse, die mit der Baseline übereinstimmen, gelten in nachfolgenden Scans als bestanden. Nachdem Sie Ihr Sicherheits-Baseline-Datum festgelegt haben, meldet die Schwachstellenanalyse nur Abweichungen von der Baseline.
Führen Sie einen neuen Scan durch, um Ihre benutzerdefinierten Tracking-Berichte anzuzeigen.
Führen Sie nach der Installation von Rule Baselines einen Scan durch, um benutzerdefinierte Berichte anzuzeigen. Die Schwachstellenbewertung meldet nur Sicherheitsprobleme, die von Ihrer genehmigten Baseline abweichen.
Big-Data-Cluster
In SQL Server 2019 ermöglicht Big Data Cluster die Bereitstellung skalierbarer Cluster von SQL Server, Spark und Hadoop Distributed File System (HDFS)…
Big Data Cluster wird hauptsächlich verwendet, um:
- Stellen Sie skalierbare SQL Server-, Spark- und HDFS-Container-Cluster bereit, die auf Kubernetes ausgeführt werden.
- Big Data aus T-SQL oder Spark SQL lesen, schreiben und verarbeiten.
- Kombinieren und analysieren Sie einfach wertvolle relationale Daten mit wertvollen Big Data.
- Fragen Sie eine externe Datenquelle ab.
- Speichern Sie Big Data in HDFS, das von SQL Server verwaltet wird.
- Fragen Sie Daten aus mehreren externen Datenquellen über den Cluster ab.
- Verwenden Sie Daten für KI, ML oder andere analytische Aufgaben.
- Stellen Sie Anwendungen in Big Data Cluster bereit und führen Sie sie aus, virtualisieren Sie Daten mit PolyBase.
- Fragen Sie Daten von externen SQL Server-, Oracle Teradata-, MongoDB- und ODBC-Datenquellen mit externen Tabellen ab.
- Bieten Sie Hochverfügbarkeit für wichtige Instanzen von SQL Server und alle Datenbanken mithilfe der Always On-Verfügbarkeitstechnologiefamilie.
Datenvirtualisierung (Datenvirtualisierung)
SQL Server Big Data-Cluster können externe Datenquellen abfragen, ohne Daten zu verschieben oder zu kopieren.
Datensee
Der Data Lake ist ein Containerspeicher, der große Mengen an Rohdaten in seinem nativen Format enthält.
Es ist ein skalierbarer HDFS-Speicherpool.
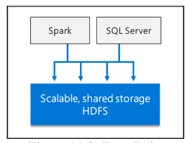
Scale-out-Datamart
Bietet Rechenleistung und Speicher in großem Umfang, um die Leistung jeder Datenanalyse zu verbessern.
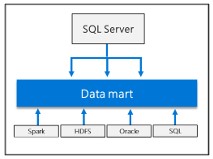
Integration von KI und maschinellem Lernen
Ermöglicht die Ausführung von KI- und maschinellen Lernaufgaben mit Daten, die in HDSF-Speicherpools und Datenpools gespeichert sind.
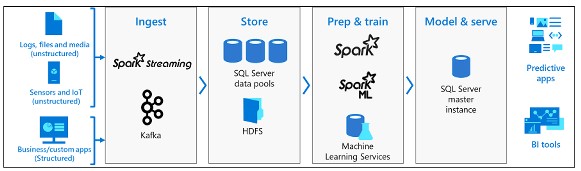
Der Big-Data-Cluster von SQL Server ist ein Cluster von Linux-Containern, die von der Kubernetes-Plattform gehostet werden.
Der Begriff Kubernetes
Kubernetes ist eine Open-Source-Container-Orchestrierung, die Container-Bereitstellungen nach Bedarf skalieren kann. Einige wichtige Kubernetes-Begriffe:
| Bedingungen | Beschreiben |
| Cluster | Kubernetes-Cluster ist eine Sammlung von Maschinen, die als Knoten verstanden werden. Ein Knoten steuert den Cluster und bestimmt ihn als Master-Knoten, die restlichen Knoten sind Worker-Knoten. Der Kubernetes-Master ist für die Verteilung der Arbeit auf die Worker und die Überwachung des Zustands des Clusters verantwortlich. |
| Knoten | Ein Knoten, der die Anwendung ausführt, ist im Container enthalten. Es kann eine physische Maschine oder eine virtuelle Maschine sein. Ein Kubernetes-Cluster kann sowohl physische als auch virtuelle Maschinenknoten enthalten. |
| Schote | Pods sind die atomare Implementierung von Kubernetes. Ein Bucket ist eine logische Gruppierung aus einem oder mehreren Containern und erforderlichen zugehörigen Ressourcen |
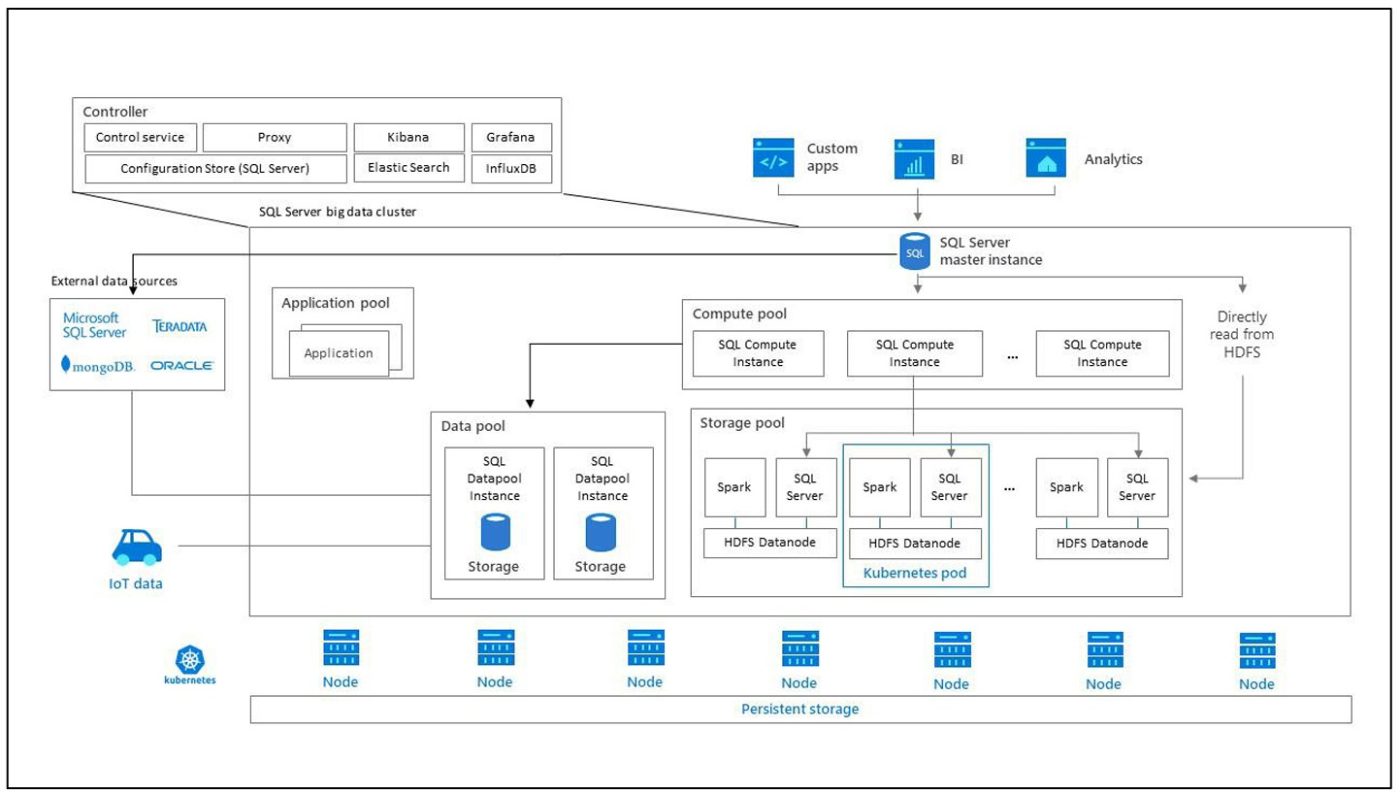
Controller
Der Controller bietet Verwaltung und Sicherheit für den Cluster. Es umfasst Steuerungs-, Konfigurations- und Cluster-Layer-Services wie Kibana, Grafana und Elastic Search.
Rechenpool
Der Rechenpool stellt Rechenressourcen für den Cluster bereit. Es enthält SQL Server-Knoten, die auf Linux-Pods ausgeführt werden. Pods in einem berechneten Pool werden für bestimmte Verarbeitungsvorgänge in SQL Compute-Instanzen unterteilt.
Datenpool
Der Datenpool wird für die Datenpersistenz und das Caching verwendet. Der Datenpool enthält einen oder mehrere Pods, auf denen SQL Server unter Linux ausgeführt wird. Es wird verwendet, um Daten aus SQL- oder Spark-Abfragen abzurufen. Big-Data-Cluster-Datamarts von SQL Server behalten die Persistenz im Datenpool bei.
Speicherpool
Der Speicherpool umfasst Speicherpool-Pods einschließlich SQL Server unter Linux, Spark und HDFS. Alle Speicherknoten im SQL Server-Bigdata-Cluster sind Mitglieder des HDFS-Clusters.
Bài viết liên quan:












Dịch vụ thiết kế Wesbite

