Index in SQL Server
-Architekturen
Mục lục
Einführung in den Index
Ein Index ist eine spezielle Datenstruktur, die einer Tabelle oder Ansicht zugeordnet ist, um Abfragen zu beschleunigen. Kurz gesagt, wenn Sie ein Feld in einer Tabelle indizieren, werden die Werte dieses Felds organisiert und strukturiert gespeichert, was dazu beiträgt, Daten in Bezug auf Leistung und Geschwindigkeit effizienter abzufragen. Die Liste der allgemeinen Indizes in SQL Server lautet wie folgt:
| Indextyp | Beschreiben |
| Geclustert | Es sortiert und speichert Datenzeilen einer Tabelle oder Ansicht in der Reihenfolge basierend auf Schlüsseln. Der in der B-Tree-Struktur implementierte gruppierte Index unterstützt das Abrufen von Zeilendaten basierend auf Schlüsselwertindizes |
| Nicht gruppiert | Nicht gruppierte Indizes werden für eine Tabelle oder Ansicht gelöscht, die Daten in einer gruppierten Struktur oder auf einem Heap enthält. Jede Indexzeile im nicht gruppierten Index enthält den Schlüsselwert und einen Zeilenlokator. Der Locator zeigt auf die Datenzeile im Clustered-Index oder den Heap mit dem Wert von key. Die Zeilen im Index werden in der Reihenfolge der Indexschlüsselwerte gespeichert, aber die Datenzeilen sind nicht garantiert in einer bestimmten Reihenfolge, es sei denn, es wird ein gruppierter Index für die Tabelle erstellt. |
| Einzigartig | Ein eindeutiger Index stellt sicher, dass der Indexschlüssel keine doppelten Werte enthält und somit jede Zeile in der Tabelle oder Ansicht in gewisser Weise eindeutig ist. Eindeutigkeit kann eine Eigenschaft von gruppierten und nicht gruppierten Indizes sein. |
| Columnstore | Index Columnstore speichert und verwaltet Daten mithilfe von spaltenbasierter In-Memory-Datenspeicherung und spaltenbasierter Abfrageverarbeitung Index Columnstore funktioniert, wenn Datenspeicher-Workloads hauptsächlich integrierte Lade- und schreibgeschützte Warteschlangen ausführen. Verwenden Sie Index Columnstore, um eine bis zu 10-fache Abfrageleistung gegenüber herkömmlicher zeilenorientierter Speicherung und eine bis zu 8-fache Datenkomprimierung für unkomprimierte Datengrößen zu erreichen |
| gefiltert | Clustered-Indizes sind so optimiert, dass sie Abfragen enthalten, die aus einer wohldefinierten Teilmenge von Daten auswählen. Es verwendet ein Filterprädikat, um einen Teil der Tabellenzeilen zu indizieren. Ein gut gestalteter gefilterter Index kann die Abfrageleistung verbessern, die Indexwartungskosten senken und die Indexspeicherkosten im Vergleich zu vollständigen Tabellenindizes senken. |
| Räumlich | Es bietet die Möglichkeit, einige effizientere Operationen an räumlichen Objekten innerhalb einer Spalte des Geometriedatentyps durchzuführen. |
| XML | Aufgrund der großen XML-Spalten können Suchanfragen in diesen Spalten langsam sein. Sie können diese Abfragen beschleunigen, indem Sie pro Spalte einen XML-Index erstellen. Der XML-Index kann ein Clustered-Index oder ein Nonclustered-Index sein. |
Es gibt auch andere Arten von Indizes wie Hash, Memory Optimized Nonclustered, Index mit eingeschlossener Spalte, Index auf berechneter Spalte, Volltext.
SQL Server verwendet Indizes ähnlich wie ein Buch indiziert wird. Betrachten wir beispielsweise eine Situation, in der wir alle „INSERT“-Tasten in einem SQL-Lernbuch finden möchten, wäre der unmittelbare Ansatz, jede Seite des Buchs zu scannen, beginnend mit der Startseite, und dann jedes Mal ein Lesezeichen zu setzen, wenn das Wort „INSERT “ wird bis zum Ende des Buches gefunden. Dieser Ansatz erfordert Zeit und Mühe. Die zweite Möglichkeit besteht darin, das Inhaltsverzeichnis des Buchs zu verwenden und zu der Seite zu gehen, auf der die Ergebnisse über INSERT sprechen, und diese Seite zu finden und zu verwenden. Methode 2 ergibt ähnliche Ergebnisse wie Methode 1, spart aber mehr Zeit und Mühe.
Wenn SQL Server keinen Index definiert, verhält es sich wie im ersten Beispiel, die SQL-Engine muss auf jeden Datensatz in der Datenbank zugreifen, in Datenbankbegriffen wird dieses Verhalten als Tabellenscan oder einfach als Scan bezeichnet.
Der Tabellen-Scan ist nicht ineffizient, aber in einigen spezifischen Situationen müssen wir eine andere Lösung verwenden, die Indizes verwendet, um die Leistung zu steigern, da die Scans langsam und ressourcenschonend sind, wenn die Datentabelle größer wird und die Anzahl der Datensätze auf Millionen ansteigt -intensiv, in dieser Situation sind immer Indizes zu empfehlen.
Überblick über die Datenspeicherung
Ein Buch enthält Seiten, darin Absätze und Sätze, ähnlich wie SQL Server Daten in Einheiten speichert, die als Datenseiten bezeichnet werden. Diese Seiten enthalten Daten in Zeilen.
Jede Seite des Buches hat physische Abmessungen. Ebenso haben in SQL Server alle Datenseiten die gleiche Größe von 8 KB. Das heißt, eine Datenbank enthält 128 Datenseiten pro Megabyte (MB) Speicherplatz.
Eine Seite beginnt mit einem 96-Byte-Header, der Systeminformationen über die Seite speichert, darunter:
- Seitenzahl
- Seitenstil
- Menge des freien Speicherplatzes auf der Seite
- Die Zuordnungs-ID des Objekts für die zugeordnete Seite
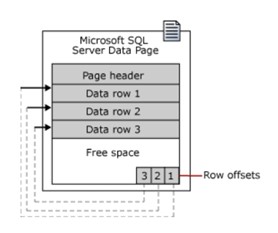
Hinweis: Die Datenseite ist die kleinste Einheit der Datenspeicherung. Eine Zuordnungseinheit ist eine Sammlung von Datenseiten, die basierend auf dem Seitentyp gruppiert sind. Durch die Gruppierung wird die Datenverwaltung effizienter.
Datei
Alle Eingabe- und Ausgabeaufgaben in der Datenbank werden auf der Seitenschicht behandelt. Das bedeutet, dass die Datenbank-Engine Datenseiten liest oder schreibt. Ein Satz von acht aufeinanderfolgenden Seiten wird Extent genannt.
SQL Server speichert Datenseiten in Dateien, die Datendateien genannt werden. Der für die Datendatei zugewiesene Speicherplatz wird in die Anzahl der nacheinander angeordneten Datenseiten unterteilt, die Seiten beginnen bei 0 , geometrische Darstellung wie unten gezeigt.
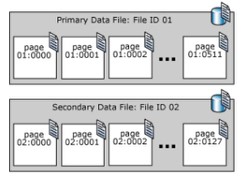
Es gibt 3 Arten von 3 Datendateien, die wie folgt erklärt werden:
- Primär: Die Hauptdatei wird automatisch zum Zeitpunkt der Datenbankerstellung erstellt, diese Datei hat Verweise auf alle verbleibenden Dateien in der Datenbank. Die empfohlene und standardmäßige Erweiterung für primäre Datendateien ist .mdf
- Sekundär: sind optionale benutzerdefinierte Datendateien. Daten können auf mehrere Laufwerke verteilt werden, indem jede Datei auf einem anderen Laufwerk abgelegt wird. Die empfohlene Erweiterung für sekundäre Datendateien ist .ndf
- Transaktionsprotokoll: Protokolldateien speichern Informationen über den Verlauf von Änderungen in der Datenbank. Diese Informationen sind nützlich für die Wiederherstellung von Sicherungsdaten, z. B. bei einem plötzlichen Stromausfall oder der Notwendigkeit, die Datenbank auf einen anderen Server zu verschieben. In jeder Datenbank gibt es mindestens eine Protokolldatei. Die empfohlene Erweiterung für Protokolldateien ist .ldf
Voraussetzung für Indizes
Um das schnelle Abrufen von Daten aus einer Datenbank zu erleichtern, stellt SQL Server eine Indizierungsfunktion bereit.Ähnlich wie das Inhaltsverzeichnis eines Buchs enthält ein Index in einer SQL Server-Datenbank Informationen, die es Ihnen ermöglichen, Daten einzeln korrekt zu durchsuchen, ohne sie vollständig zu durchsuchen Tisch.

Index
In einer Tabelle werden die Datensätze in der Reihenfolge ihrer Eingabe gespeichert, sie werden in der Datenbank ungeordnet abgelegt, dh sortiert nach der Eingabehistorie. Wenn Daten aus der Tabelle abgerufen werden, muss die gesamte Tabelle gescannt werden, was den Vorgang verlangsamt. Um den Prozess zu beschleunigen, führen wir eine sogenannte Indizierung durch.
Wenn ein Index in der Tabelle erstellt wird, erstellt er eine sortierte Version des Datensatzes, was das Auffinden und Abrufen von Daten während einer Suche beschleunigt.
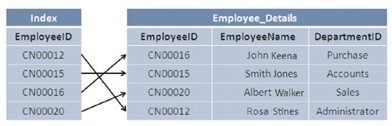
Der Index wird automatisch erstellt, wenn PRIMARY KEY- und UNIQUE-Einschränkungen in der Tabelle definiert sind, die Indizierung reduziert Lese- und Schreibaufgaben auf der Festplatte und verbraucht weniger Systemressourcen.
Syntax:
CREATE INDEX <index_name> ON <table_name> (<column_name>)Index zeigt auf die Position des Datensatzes in der Datenseite, anstatt die Tabelle zu durchsuchen. Einige Funktionen des Index:
- Indizes beschleunigen eine Abfrage, die eine Tabelle verknüpft oder Sortieraufgaben übernimmt.
- Index implementiert die Eindeutigkeit von Zeilen, wenn sie beim Erstellen des Index definiert wird.
- Indizes werden in Vorwärts- und Rückwärtssortierung erstellt und verwaltet.
Das Drehbuch
Beispielsweise gibt es in einem Telefonbuch eine große Datenmenge, die sortiert und häufig aufgerufen wird, die Daten werden in alphabetischer Reihenfolge gespeichert. Wenn die Daten nicht sortiert sind, ist es fast unmöglich, eine bestimmte Telefonnummer schnell zu finden.
In ähnlicher Weise werden in einer Datenbanktabelle, die eine große Anzahl von Datensätzen enthält und häufig abgefragt werden muss, die Daten für eine schnellere Abfrage sortiert. Wenn ein Index für eine Tabelle erstellt wird, sortiert der Index die Datensätze physisch oder logisch. Daher wird das Auffinden des angegebenen Datensatzes schneller und die Belastung der Systemressourcen reduziert.
gruppenweise Zugriffsdaten
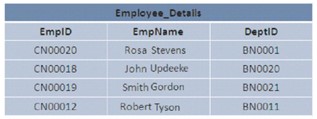
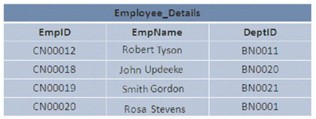
Indizes sind nützlich, wenn auf Daten in Gruppen zugegriffen wird. Sie möchten beispielsweise eine Modifikation erstellen, die die Abteilungen für die HR-Gruppe basierend auf den Abteilungen wechselt, in denen die Mitarbeiter in der Datenbank arbeiten. In dieser Situation ist es möglich, einen Index für die Spalte DepartmentName zu erstellen, bevor auf die Datensätze zugegriffen wird.
Dieser Index generiert logische Datenfragmente und gruppiert Datensätze nach Abteilungen, wodurch die Datenmenge begrenzt wird, die während des Datenabrufs tatsächlich gescannt wird.
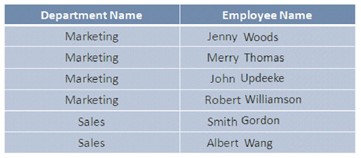
Indexarchitektur
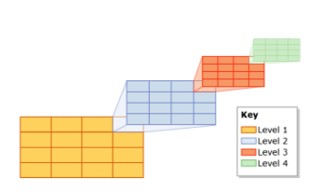
In SQL Server können die Daten in der Datenbank in einer bestimmten oder zufälligen Anordnung gespeichert werden. Wenn die Daten in einer geordneten Weise gespeichert werden, sagt man, dass die Daten in einer geclusterten Struktur dargestellt sind. Wenn die Daten zufällig gespeichert werden, spricht man von einer Heap-Struktur.
Das Bild zeigt 2 Heap- und Clustered-Strukturen:
B-Baum
In SQL Server sind Indizes in einer B-Tree-Struktur organisiert, jede Seite in einem B-Tree-Index wird als Indexknoten bezeichnet. Der höchste Knoten wird Wurzelknoten genannt. Die unterste Note im Index wird Blattknoten genannt. Jede Schicht zwischen dem Wurzelknoten und dem Blattknoten wird als Zwischenknoten bezeichnet.
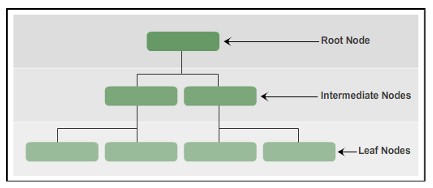
Der B-Tree-Index geht von der Spitze des Knotens nach unten durch einen Zeiger.
B-Tree-Indexstruktur
In der B-Baumstruktur eines Index enthält der Wurzelknoten eine Indexseite. Die Indexseite enthält einen Zeiger und zeigt auf die Indexseite, die die erste Zwischenschicht darstellt. Diese Indexseiten wiederum zeigen auf die Indexseiten, die auf der nächsten Zwischenebene vorhanden sind. In einem B-Tree-Index können mehrere Zwischenebenen vorhanden sein. Der Blattknoten im B-Baum-Index hat eine Datenseite, die Datensatzdaten enthält oder eine Datenseite enthält, die Indexdatensätze speichert, die auf Datensätze in der Tabelle zeigen.
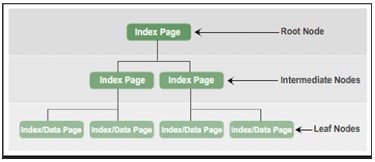
Zusammenfassend entsprechen die Knotentypen im B-Tree-Index:
- Wurzelknoten: enthält eine Indexseite mit einem Zeiger auf die Indexseiten in der Zwischenschicht.
- Zwischenknoten : enthält Indexseiten mit Zeigern auf Indexseiten in der Zwischenschicht oder Index- oder Datenseiten in der Blattschicht.
- Blattknoten: Enthält Datenseiten oder Indexseiten, die auf Datenseiten verweisen.
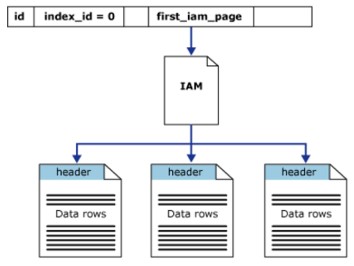
Heap-Struktur
Der Heap ist eine Tabelle ohne Clustered-Index. Das bedeutet, dass in der Heap-Struktur die Datenseiten und Register nicht sortiert sind. Die einzige Verbindung zwischen Datenseiten sind die Informationen, die auf der Seite Index Allocation Map (IAM) aufgezeichnet sind.
Weitere Informationen zum Begriff Heap-Struktur finden Sie in der Datenstruktur: https://en.wikipedia.org/wiki/%C4%90%E1%BB%91ng_(c%E1%BA%A5u_tr%C3%BAc_d%E1 %BB% AF_li%E1%BB%87u)#:~:text=In%20khoa%20h%E1%BB%8Dc%20m%C3%A1y%20t%C3%ADnh,%C4%91%C6%B0% E1%BB %A3c%20g%E1%BB%8Di%20l%C3%A0%20max%2Dheap.
Der Heap hat eine Zeile in sys.partitions, mit index_id = 0 für jede vom Heap verwendete Partition. Standardmäßig hat ein Heap seine eigene Partition, wenn der Heap mehrere Partitionen hat, hat jede Partition eine Heap-Struktur, die die definierten Daten enthält. Wenn der Heap beispielsweise 4 Partitionen hat, gibt es 4 Heap-Strukturen, jede in einer Partition.
Jedem Heap ist mindestens ein IN_ROW_DATA pro Partitionseinheit zugeordnet. Dem Heap ist auch LOB_DATA pro Partitionseinheit zugeordnet, wenn er eine LOB-Spalte (Large Object) enthält. Es hat auch eine ROW_OVERFLOW_DATA-Zuweisung pro Partitionseinheit, wenn es keine Spalten bekannter Länge enthält, beträgt die maximale Größenbeschränkung 8060 Datensätze.
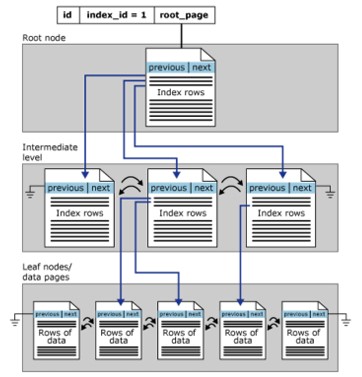
Geclusterte Indexstruktur
Clustered-Indizes sind in einem B-Tree-Format organisiert. Jede Seite im B-Tree-Index wird als Indexknoten bezeichnet. Ähnlich im Konzept ist der oberste Knoten des gruppierten Index auch der Stammknoten und der unterste Knoten ist der Blattknoten.
- Blattknoten enthalten die grundlegenden Datenseiten der Tabelle, die Wurzel- und Zwischenschichten enthalten die Indexseiten, die die Indexzeilen enthalten. Jeder Index enthält einen Schlüsselwert und einen Zeiger auf eine Zwischenseite im B-Baum oder eine Datenzeile in der Blattschicht des Index.
- Standardmäßig hat ein gruppierter Index eine einzelne Partition. Wenn ein gruppierter Index mehrere Partitionen hat, ist jede Partition eine B-Tree-Struktur, die den Wert einer bestimmten Partition enthält.
- Der gruppierte Index hat auch ein LOB_DATA, das jeder Partition zugeordnet ist, wenn es in einer LOB-Spalte (großes Objekt) enthalten ist. Und es hat auch eine ROW_OVERFLOW_DATA-Zuordnung in jeder einzelnen Partition.
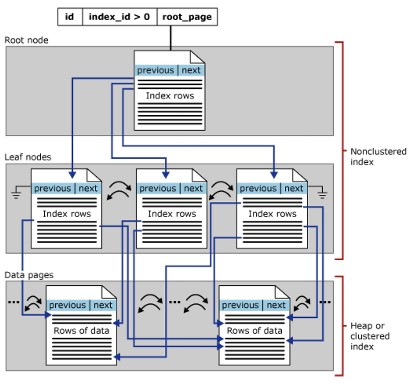
NonClustered-Indexstruktur
Ein Nonclustered-Index hat dieselben B-Tree-Strukturen wie ein Clustered-Index, jedoch mit den folgenden Unterschieden:
- Die Datenzeilen der Tabelle werden physikalisch nicht in der durch ihre undifferenzierten Schlüssel festgelegten Reihenfolge gespeichert.
- In der nicht gruppierten Indexstruktur enthält die Blattschicht Indexzeilen.
- Nonclustered-Indizes sind nützlich, wenn Sie mehrere Möglichkeiten zum Suchen von Daten benötigen.
- Wenn ein gruppierter Index neu erstellt oder die Option DROP_EXISTING verwendet wird, erstellt SQL Server die vorhandenen nicht gruppierten Indizes.
- Eine Tabelle kann bis zu 888 Nonclustered-Indizes haben
- Erstellen Sie einen gruppierten Index, bevor Sie einen nicht gruppierten Index erstellen.
Spaltenspeicherindex (Spaltenspeicherindex)
Der Columnstore-Index ist ein Feature von SQL Server, das darauf abzielt, Daten mithilfe von Spaltendaten, die Columnstore genannt werden, zu speichern, abzurufen und zu verwalten.
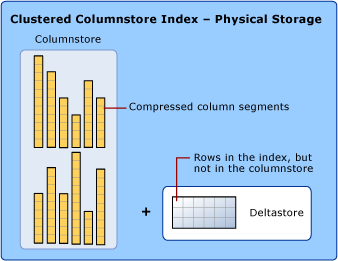
Der Columnstore-Index verwendet zwei Arten der Datenspeicherung: das Rowstore- und das Columnstore-Format.
Der Columstore-Index wird hauptsächlich aus folgenden Gründen verwendet:
- Reduzierte Lagerkosten
- Leistung verbessern
Einzelheiten zu den Formaten Columnstore, Rowstore und Deltastore lauten wie folgt:
- Columnstore : Daten sind logisch in Tabellen organisiert, wobei Zeilen und Spalten physisch im Spaltengruppen-Datenformat gespeichert sind.
- Rowstore : Daten werden logisch als Tabelle mit Zeilen und Spalten organisiert und dann physisch in einem Zeilengruppen-Datenformat gespeichert.
- Deltastore : Es hält die Position von Zeilen, wenn sie zu wenig Daten haben, um sie in Columnstore zu komprimieren. Deltastore speichert Zeilen im Rowstore-Format.
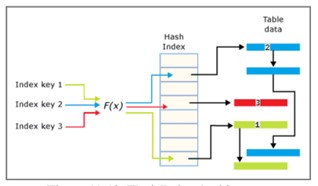
HashIndex
Der Hash-Index besteht aus einem Array von Zeigern und jedes Element im Array wird als Hash-Bucket bezeichnet.
- Jeder Bucket hat eine Größe von 8 Bytes und wird verwendet, um die Speicherstelle des Schlüssels in einer Verbindungslisteneintragsstruktur zu speichern.
- Jeder Eintrag ist ein Wert für den Indexschlüssel, der die entsprechende Adresse der Zeile in der speicheroptimierten Tabelle ist.
- Jeder Eintrag zeigt auf den nächsten Eintrag in einer Verknüpfungsliste, die alle verkettet sind (was als Kettenschloss zum aktuellen Bucket interpretiert werden kann).
Die Anzahl der Buckets muss zum Zeitpunkt der Definition definiert werden und einige der folgenden Eigenschaften haben:
- Short-List-Links werden schneller verarbeitet als Long-List-Links.
- Der Hash-Index kann höchstens 1.073.741.824 Buckets enthalten.
XML-Index
Für Spalten vom Datentyp XML kann ein XML-Index erstellt werden. Sie indizieren Tags, Werte und Pfade innerhalb von XML-Instanzen innerhalb von Spalten und erhöhen die Abfrageleistung. In folgenden Fällen kann Ihre Anwendung mit einem XML-Index im Vorteil sein:
XML-Spaltenabfragen sind in der Workload üblich. Die Ressourcenkosten für die Verwaltung der Index-XML während Datenänderungen müssen berücksichtigt werden.
Wenn XML-Werte relativ groß und die Teile, auf die zugegriffen wird, relativ klein sind, vermeidet die Indexkonstruktion die Notwendigkeit, die gesamten Daten zur Laufzeit zu analysieren, und ist für Indexsuchen für die Abfrageverarbeitung von Vorteil.
Es gibt zwei Arten von XML-Indizes:
- Primärer XML-Index
- Sekundärer XML-Index
Räumlicher Index (räumlicher Index)
In SQL Server verwenden räumliche Indizes B-Strukturen, was bedeutet, dass Indizes in zwei räumlichen Dimensionen in der linearen Anordnung der B-Struktur dargestellt werden müssen. Daher implementiert SQL Server vor dem Lesen der Daten im räumlichen Index ein einheitliches hierarchisches räumliches Schichtungsmodell. Der Indizierungsprozess unterteilt den Raum in eine Gitterhierarchie mit vier Ebenen.
Volltextindex
Das Erstellen und Verwalten eines Volltextindex umfasst die Indizierung mithilfe eines Prozesses, der als Aggregation, auch als Crawling bezeichnet, bekannt ist.
Arten der Informationssammlung:
- Volle Bevölkerung
- Automatische / manuelle Befüllung basierend auf Änderungsverfolgung
- Inkrementelle Bevölkerung heftig auf Zeitstempel
Clustered-Index erstellen
Die Anweisung CREATE CLUSTERED index ermöglicht dem Benutzer, einen CLUSTERED-Index für eine angegebene Spalte und Tabelle zu erstellen.
Syntax:
CREATE CLUSTERED INDEX index_name ON table_name (column1,column2,...);Zum Beispiel:
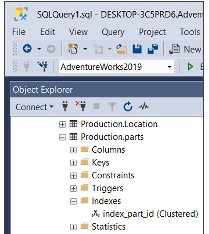
USE AdventureWorks2019 CREATE TABLE Production.Parts( part_id INT NOT NULL, part_name VARCHAR(100) ) CREATE CLUSTERED INDEX ix_parts_id ON Production.parts (part_id);INDEX UMBENENNEN
sp_rename ist eine gespeicherte Systemprozedur, mit der Sie jedes Objekt umbenennen können, das der Benutzer in der aktuellen Datenbank erstellt hat, einschließlich Tabellen, Indizes und Spalten.
Syntax:
EXEC sp_rename index_name,new_index_name, N'INDEX';Zum Beispiel:
EXEC sp_rename N'Production.parts.ix_parts_id', N'index_part_id',N'INDEX';Oder klicken Sie im Objekt-Explorer mit der rechten Maustaste auf den Index und wählen Sie die Option Umbenennen
INDEX DEAKTIVIEREN
Um den Index zu deaktivieren, wird die ALTER INDEX-Anweisung verwendet.
Syntax
ALTER INDEX index_name ON table_name DISABLE;Zum Beispiel:
ALTER INDEX index_part_id ON Production.Parts DISABLE; select * from Production.PartsNach dem Deaktivieren des Index wird beim Abfragen der Daten ein Fehler angezeigt:
The query processor is unable to produce a plan because the index 'index_part_id' on table or view 'Parts' is disabled.INDEX AKTIVIEREN
Um die Indizierung zu aktivieren, wird die ALTER INDEX-Anweisung verwendet.
Syntax:
ALTER INDEX index_name ON table_name REBUILD;Zum Beispiel:
ALTER INDEX index_part_id ON Production.Parts REBUILD;DROP-INDEX
Die DROP INDEX-Anweisung entfernt den Index aus der aktuellen Datenbank.
Syntax:
DROP INDEX [IF EXISTS] index_name ON table_name;Zum Beispiel:
DROP INDEX IF EXISTS index_part_id ON Production.Parts;NonClustered-Index
Ein Noncluster-Index ist eine Datenstruktur, die das Abrufen von Daten aus einer Tabelle beschleunigt. Im Gegensatz zu einem Clustered-Index sortiert und speichert ein Nonclustered-Index Daten stückweise aus Datenzeilen in einer Tabelle.
Syntax:
CREATE [NONCLUSTERED] INDEX index_name ON table_name(column1,column2,...);Zum Beispiel:
CREATE NONCLUSTERED INDEX index_customer_storeid ON Sales.Customer(StoreID);Eindeutiger Index
Der eindeutige Index stellt sicher, dass Indexschlüsselspalten keine doppelten Werte enthalten.
Es kann eine oder mehrere Spalten enthalten, wenn der eindeutige Index eine Spalte hat, ist der Wert der Spalte eindeutig, bei einem eindeutigen Index mit vielen Spalten ist die Kombination dieser Spaltenwerte eindeutig.
Hinweis: Der eindeutige Index kann gruppiert oder nicht gruppiert sein.
Syntax zum Erstellen eines eindeutigen Index:
CREATE UNIQUE INDEX index_name ON table_name(column_list);Zum Beispiel:
CREATE UNIQUE INDEX AK_Customer_rowguid ON Sales.Customer(rowguid);Gefilterter Index
Der gefilterte Index ist ein nicht gruppierter Index, mit dem Sie bestimmen können, welche Zeilen dem Index hinzugefügt werden.
Syntax:
CREATE INDEX index_name ON table_name(column_list) WHERE predicate;Zum Beispiel:
CREATE INDEX index_cust_personID ON sales.Customer(PersonID) WHERE PersonID IS NOT NULL;Partitionierte Tabellen und Indizes
SQL Server unterstützt zwei Arten von Tabellen und Indexpartitionen (Partitionen). Die Daten einer partitionierten und indizierten Tabelle werden in eine optionale Einheit unterteilt, die sich optional über mehrere Dateigruppen in der Datenbank erstrecken kann. Die Daten werden horizontal partitioniert, wodurch die zugeordneten (verbundenen) Zeilen in einer separaten Partition gruppiert werden Alle Partitionen einer einzelnen Tabelle oder eines einzelnen Indexes müssen sich in derselben Datenbank befinden. Die Tabelle oder der Index wird beim Abfragen oder Aktualisieren von Daten als Objekt behandelt.
SQL Seserver 2019 unterstützt standardmäßig bis zu 15.000 Partitionen.
Vorteile der Partitionierung:
- Daten schnell und effizient konvertieren oder abfragen.
- Beim Umgang mit Persistenzaufgaben auf einer oder mehreren Partitionen sind Aufgaben effizienter, da sich ihr Ziel nur auf dem Dataset auf der Partition und nicht auf der gesamten Tabelle befindet.
- Erhöhen Sie die Abfrageleistung, Daten über die Art der Abfragen, die Sie häufig ausführen, und die Hardwarekonfiguration.
Das Beispiel erstellt eine Beispieltabelle mit den folgenden Informationen:
CREATE TABLE testing_table(receipt_id BIGINT, date DATE) Gibt an, wie genau die Tabelle partitioniert wird, in diesem Fall die Datumsspalte, zusammen mit
Bereich von Werten wird in jeder Partition hinzugefügt. In Bezug auf Partitionsgrenzen können Sie LEFT oder RIGHT (linke oder rechte Seite) angeben.
CREATE PARTITION FUNCTION partition_function (int) AS RANGE LEFT FOR VALUES (20200630,20200731,20200831);Das bedeutet, wie folgt in 4 Partitionen unterteilt:
- Partition 1: alle Datensätze mit Datum <= 30.06.2020
- Partition 2: alle Datensätze mit Datum > 30.06.2020 und Datum <= 31.07.2020
- Partition 3: alle Datensätze mit Datum > 31.07.2020 und Datum <= 31.08.2020
- Partition 4: alle Datensätze mit Datum > 31.08.2020
Mit dem folgenden Code können Sie die Region Phana identifizieren, in der jeder Datensatz platziert ist
(SELECT 20200613 date, $PARTITION.partition_function(2020613) AS PartitionNumber) UNION (SELECT 20200713 date, $PARTITION.partition_function(2020713) AS PartitionNumber) UNION (SELECT 20200813 date, $PARTITION.partition_function(20200813) AS PartitionNumber) UNION (SELECT 20200913 date, $PARTITION.partition_function(20200913) AS PartitionNumber)
XML-Index
XML-Daten werden in einem Spaltentyp gespeichert, dessen Datentyp XML ein Datentyp ist, der viel Größe verbraucht, genannt Large Binary Objects (BLOBs).
Zur Darstellung von XML-Daten kann die Datentypgröße bis zu 2 GB betragen.
Der XML-Index wird für eine Spalte erstellt, die XML-Daten enthält, und in einer Tabelle und Datenbank gespeichert.
Zum Beispiel:
CREATE PRIMARY XML INDEX PXML_PRoduct_Model_Catalog_Description ON Production.ProductModel (CatalogDescription);Der primäre XML-Index enthält alle Daten in der XML-Spalte. Um der XML-Abfrage mehr Leistung zu verleihen, können Sie sekundäre Indizes hinzufügen. Sekundäre XML-Indizes verwenden ebenfalls denselben Datensatz, da es sich um den zugrunde liegenden primären Index handelt, erstellen jedoch einen spezifischeren Index, der auf dem primären Index basiert.
Zum Beispiel:
CREATE XML INDEX IXML_ProductModel_CatalogDescription_Path ON Production.ProductModel (CatalogDescription) USING XML INDEX PXML_ProductModel_CatalogDescription FOR PATH;Columnstore-Index
Syntax:
CREATE COLUMNSTORE INDEX IX_SalesOrderDetail_ProductIDOrderQty_ColumnStore ON Sales.SalesOrderDetail (ProductID,OrderQty);Das Erstellen dieses Index verbessert die Gruppierung nach Abfrage bei der Verwendung von Aggregatfunktionen, aber testen Sie es bitte erneut mit Ihrer Umgebung, da in meinem SSMS derzeit dieser Befehlszeitüberschreitungsfehler ausgeführt wird.
SELECT ProductID,SUM(OrderQty) FROM Sales.SalesOrderDetail GROUP BY ProductId;
Bài viết liên quan:


Dịch vụ thiết kế Wesbite

