Pipeline im maschinellen Lernen
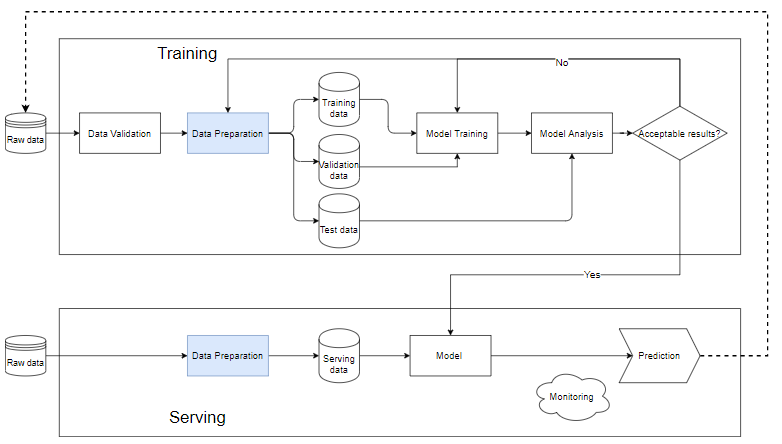
Pipeline in ML ist eine Möglichkeit, den Workflow zum Erstellen eines Modells für maschinelles Lernen zu automatisieren. Fast jedes maschinelle Lernsystem hat Komponenten wie das folgende Diagramm, es ist eine maschinelle Lernpipeline.
Mục lục
Was ist eine Pipeline beim maschinellen Lernen?
Trainingsblock
- Datenvalidierung: Ist der Schritt des Testens von Daten, um festzustellen, ob die neu hinzugefügten Daten mit den Daten in der Datenbank zufrieden sind. Aus diesem Grund werden immer neue Daten hinzugefügt, um den Zug auszuführen.
- Nachdem die Rohdaten für den Datenvorbereitungsschritt bereinigt wurden, werden sie dann in einen Trainingsdatensatz, einen Trainingsdatensatz und einen Validierungsdatensatz aufgeteilt, Testdaten, um die Qualität des Modells nach dem Trainingsprozess zu bestimmen.
- Die Trainingsdaten werden zum Trainieren des Modells in den Block "Modelltraining" eingefügt.
- Nach dem Training führen wir die Analyse im Block „Modellanalyse“ durch, um die Qualität zu analysieren. Überprüfen Sie, ob die Metriken auf dem Test-Set gut sind, die vorhergesagten Ergebnisse und die tatsächlichen Ergebnisse äquivalent sind, die Vorhersagegeschwindigkeit, …
- Wenn die Daten den Modellanalyseblock durchlaufen haben, wird das Modell verwendet, um die eigentlichen Daten im Schritt „Serving“ auszuführen. Andernfalls müssen wir das Modell überprüfen oder die Daten filtern.
Serving .Block
- Wenn das Modell noch Stub ist, sollten wir einen kleinen Datensatz verwenden, den Test ausführen, wenn die Qualität akzeptabel ist, können wir ihn mit den gesamten Daten durchführen.
- Die Datenvorbereitung hilft beim Bereinigen und Erstellen von Daten, die mit dem Modell im Trainingsblock übereinstimmen müssen.
- Jedes unterschiedliche Problem erfordert ein anderes Überwachungs- und Warnsystem. Normalerweise wird das Modell unabhängig von den Eingabedaten immer noch ein vorhersagbares, möglicherweise zufälliges Ergebnis liefern. Wenn diese Ergebnisse nicht sorgfältig überwacht und alarmiert werden, was zu plötzlichen Änderungen der Modellqualität und der Benutzerreaktionen führt, werden der Ruf und die Einnahmen des Unternehmens beeinträchtigt.
Warum Rohrleitungen bauen?
- Systeme für maschinelles Lernen bestehen oft aus vielen kleinen Komponenten wie Datenverarbeitung, Modelltraining, Modellbewertung, Vorhersage mit neuen Daten usw. Ohne den Aufbau einer vollständigen Pipeline mit jeder Komponente getrennt, wird es natürlich viele Probleme geben. Wenn Sie Ihr System Schritt für Schritt trennen und in einer Pipeline wieder zusammenfügen, können Sie Fehler beim Trainieren des Modells leichter finden.
- Der Aufbau einer Pipeline hilft uns auch, als Team besser zusammenzuarbeiten. Wenn es eine große Gruppe gibt, können wir sie in kleine Gruppen aufteilen: eine Gruppe spezialisiert sich auf die Datenbereinigung, eine Gruppe spezialisiert sich auf die Erstellung von Funktionen, eine andere Gruppe erstellt und trainiert das Modell und eine andere Gruppe konzentriert sich auf die Bewertung und überwacht die Aktivität der Modell. Diese Arbeitsblöcke, wenn sie getrennt und spezialisiert sind, helfen den Teams, einen Drilldown durchzuführen, um die Qualität jedes Blocks zu verbessern, ohne sich Gedanken über das Brechen des Codes anderer Teams machen zu müssen.
Einfaches Beispiel
Hier stelle ich eine komplette Pipeline vor, ich gehe nicht auf jede Kommandozeile ein, sondern möchte Ihnen anhand dieses Beispiels einen Überblick über eine Pipeline geben. Den vollständigen Code können Sie hier einsehen
Der erste Schritt besteht darin, die erforderlichen Bibliotheken zu importieren.
from pathlib import Path import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.ensemble import RandomForestClassifier from sklearn.impute import KNNImputer, SimpleImputer from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.pipeline import Pipeline from sklearn.preprocessing import OneHotEncoder, RobustScalerLade Daten
titanic_path = ( "https://github.com/CongSon01/titanic_pipeline/" ) df_train_full = pd.read_csv(titanic_path + "train.csv") df_test = pd.read_csv(titanic_path + "test.csv")
Lassen Sie die fehlenden Daten fallen, bringt das Modell keine Effizienz.
df_train_full.drop(columns=["Cabin"]) df_test.drop(columns=["Cabin"]);Bevor wir mit dem Feature-Erstellungsschritt fortfahren, müssen wir die Trainings-/Testdaten aufteilen. Hier werden die zufälligen 10 % der ursprünglich gekennzeichneten Daten als Validierungsdaten extrahiert, die restlichen 90 % werden als Trainingsdaten aufbewahrt. Die Spalte Survived ist die Beschriftungsspalte, die in eine separate Variable aufgeteilt ist, die die Beschriftung enthält:
df_train, df_val = train_test_split(df_train_full, test_size=0.1) X_train = df_train.copy() y_train = X_train.pop("Survived") X_val = df_val.copy() y_val = X_val.pop("Survived")Verarbeitungsfunktionen mit kategorialen oder numerischen Datentypen haben unterschiedliche Verarbeitungsmethoden. Wir beschäftigen uns zunächst mit kategorialen Daten.
cat_cols = ["Embarked", "Sex", "Pclass"] cat_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="most_frequent")), ("onehot", OneHotEncoder(handle_unknown="ignore", sparse= False )), ] )Als nächstes wenden wir num_transformer auf zwei numerische Features an:
num_cols = ["Age", "Fare"] num_transformer = Pipeline( steps=[("imputer", KNNImputer(n_neighbors=5)), ("scaler", RobustScaler())] )Wenn wir zwei Prozessoren kombinieren, erhalten wir einen vollständigen Prozessor. Die Klasse scikit-learn ColumnTransformer hilft beim Kombinieren von Transformatoren:
preprocessor = ColumnTransformer( transformers=[ ("num", num_transformer, num_cols), ("cat", cat_transformer, cat_cols), ] )Schließlich kombinieren wir den präprozessorspezifischen Prozessor mit einem einfachen Klassifikator, der häufig mit tabellarischen Daten verwendet wird, RandomForestClassifier, um eine full_pp-Pipeline zu erhalten, die sowohl Datenverarbeitung als auch Modelle umfasst. Full_pp wird an die Trainingsdaten (X_train, y_train) angepasst und dann zum Anwenden auf die Testdaten verwendet.
# Full training pipeline full_pp = Pipeline( steps=[("preprocessor", preprocessor), ("classifier", RandomForestClassifier())] ) # training full_pp.fit(X_train, y_train) # training metric y_train_pred = full_pp.predict(X_train) print( f"Accuracy score on train data: { accuracy_score(list(y_train), list(y_train_pred)) : .2f } " ) # validation metric y_pred = full_pp.predict(X_val) print( f"Accuracy score on validation data: { accuracy_score(list(y_val), list(y_pred)) : .2f } " )Genauigkeitswert für Zugdaten: 0,98 Genauigkeitswert der Validierungsdaten: 0,83
Somit liefert das gesamte System eine Genauigkeit von 98 % auf dem Trainingssatz und 83 % auf dem Testsatz. Dieser Unterschied beweist, dass es zu einer Überanpassung gekommen ist (darüber werde ich in den folgenden Artikeln sprechen).
Bài viết liên quan:












Dịch vụ thiết kế Wesbite

