SQL Server SELECT-Anweisung und Datenabfrageklauseln
Viele SQL-Versionen verwenden FROM in ihren Abfragen, aber in allen Versionen seit SQL Server 2005, einschließlich SQL Server 2019, kann man SELECT-Anweisungen verwenden, ohne die FROM-Klausel zu verwenden.
Mục lục
SELECT-Anweisung
Eine Tabelle mit ihren Daten kann mit der SELECT-Anweisung eingesehen werden. Die SELECT-Anweisung in einer Abfrage zeigt die erforderlichen Informationen in einer Tabelle an. Die SELECT-Anweisung ruft die Zeilen und Spalten für eine oder mehrere Tabellen ab. Die Ausgabe der SELECT-Anweisung ist eine weitere Tabelle, die Ergebnismenge genannt wird. Die SELECT-Anweisung verbindet auch zwei Tabellen oder ruft eine Teilmenge von Spalten aus einer oder mehreren Tabellen ab. Die SELECT-Anweisung definiert die für eine Abfrage verwendeten Spalten. Die Syntax der SELECT-Anweisung kann eine Reihe von durch Kommas getrennten Ausdrücken enthalten. Jeder Ausdruck in der Anweisung ist eine Spalte in der Ergebnismenge. Die Spalten erscheinen in derselben Reihenfolge wie der Ausdruck in der SELECT-Anweisung. Die SELECT-Anweisung ruft Zeilen aus der Datenbank ab und ermöglicht die Auswahl einer oder mehrerer Zeilen.
Hinsichtlich der Ausführungsreihenfolge wird die SELECT-Klausel zuletzt ausgeführt, obwohl sie am Anfang des Satzes steht
Syntax:
SELECT <column_name1> [,column_name2] FROM <table_name>Zum Beispiel:
SELECT [BusinessEntityID] ,[PersonType] ,[NameStyle] ,[Title] ,[FirstName] ,[MiddleName] ,[LastName] ,[Suffix] ,[EmailPromotion] ,[AdditionalContactInfo] ,[Demographics] ,[rowguid] ,[ModifiedDate] FROM [AdventureWorks2019].[Person].[Person]Wählen Sie ohne VON
Viele Versionen von SQL verwenden FROM in ihren Abfragen, aber in allen Versionen seit SQL Server 2005, einschließlich SQL Server 2019, kann die SELECT-Anweisung ohne Verwendung der FROM-Klausel verwendet werden.
Zum Beispiel:
SELECT LEFT ('Hello World',5) 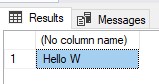
Alle Spalten anzeigen
Das Schlüsselwort Asterisk (*) wird für die SELECT-Anweisung verwendet, um die Daten der gesamten Spalte in der Tabelle abzurufen. Es wird als Abkürzung verwendet, anstatt eine Liste aller Spalten in der Tabelle zu schreiben.
Syntax:
SELECT * FROM <table_name>Zum Beispiel:
SELECT * FROM [AdventureWorks2019].[Person].[Person]Das *-Zeichen ist sehr praktisch, falls es zu viele Spalten gibt und Sie sich nicht an alle Spaltennamen erinnern können oder es zu lang zum Aufschreiben ist. In der Praxis sollten Sie das *-Zeichen jedoch nicht zu sehr missbrauchen, da das System dadurch sehr stark beansprucht wird, da die Daten redundant sind. Wenn Sie beispielsweise eine Funktion erstellen, die Benutzernamen anzeigt, schreiben Sie einfach select username is ok, nicht unbedingt SELECT *, da das Entfernen von mehr Spalten die Leistung verringert und mehr RAM verbraucht.
Andere Ausdrücke als SELECT
Die SELECT-Anweisung ermöglicht es dem Benutzer, verschiedene Ausdrücke anzugeben, um die Ergebnismenge in geordneter Weise anzuzeigen. Diese Ausdrücke weisen Spalten in der Ergebnismenge unterschiedliche Namen zu, berechnen Werte und entfernen doppelte Werte.
Verwenden von Konstanten in Ergebnismengen
Zeichenfolgenkonstanten werden verwendet, wenn Zeichenspalten miteinander verkettet werden. Sie helfen bei der richtigen Formatierung oder Lesbarkeit. Diese Konstanten werden nicht als separate Spalte in der Ergebnismenge angegeben. Für die Anwendung ist es normalerweise effizienter, konstante Werte in die Ergebnisse einzubauen, wenn sie angezeigt werden, anstatt den Server zum Kombinieren der konstanten Werte zu verwenden. Um beispielsweise „:“ und „->“ in die Ergebnismenge aufzunehmen, um den Ländernamen, den Ländercode und die entsprechende Gruppe anzuzeigen, wird die SELECT-Anweisung im folgenden Beispiel gezeigt:
USE AdventureWorks2019 SELECT Name+':'+CountryRegionCode+'->'+[Group] FROM Sales.SalesTerritory 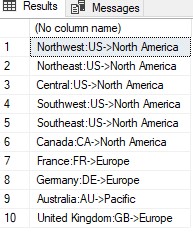
Spalte im Ergebnissatz umbenennen
Die in der Ergebnismenge von Abfragen mit dem entsprechenden Titel angezeigten Spalten können mit der AS-Klausel geändert, umbenannt oder mit einem neuen Namen versehen werden. Durch das Anpassen von Kopfzeilen werden sie verständlicher und semantischer.
Zum Beispiel:
USE AdventureWorks2019 SELECT Name+':'+CountryRegionCode+'->'+[Group] AS NameRegion FROM Sales.SalesTerritory 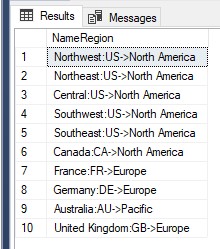
Berechnen Sie den Wert in der Ergebnismenge
Die SELECT-Anweisung kann mathematische Ausdrücke enthalten, indem Operatoren auf eine oder mehrere Spalten angewendet werden. Es ermöglicht eine Ergebnismenge, die Werte enthält, die nicht in der Basistabelle vorhanden sind, sondern aus den in der Basistabelle gespeicherten Werten berechnet werden.
Beispiel-Ergebnissatz mit 15 % Rabatt zur Verwendung für Werbeanzeigen:
USE AdventureWorks2019 SELECT ProductID,StandardCost,StandardCost*0.16 AS Discount FROM Production.ProductCostHistory GO 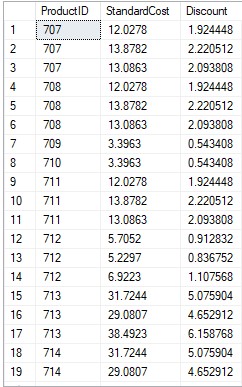
Mit DISTINCT
Das Schlüsselwort DISTINCT verhindert das Abrufen doppelter Datensätze. Es entfernt sich wiederholende Zeilen aus der Ergebnismenge einer SELECT-Anweisung. Wenn beispielsweise die Spalte StandardCost ausgewählt wird, ohne das Schlüsselwort DISTINCT zu verwenden, wird jeder StandardCost-Datensatz nur einmal angezeigt, wie zum Beispiel:
USE AdventureWorks2019 SELECT DISTINCT ProductID,StandardCost,StandardCost*0.16 AS Discount FROM Production.ProductCostHistory GOMit TOP und in SELECT
Das TOP-Schlüsselwort zeigt nur einen Teil der Ergebnismenge. Die Menge der Datensätze wird durch Anzahl oder Prozentsatz (%) begrenzt, TOP-Ausdruck kann auch mit Anweisungen wie INSERT, UPDATE, DELETE verwendet werden.
Syntax:
SELECT [ALL|DISTINCT] [TOP expression [PERCENT] [NUMER]] FROM <table_name>Zum Beispiel:
USE AdventureWorks2019 SELECT TOP 100 ProductID,StandardCost,StandardCost*0.16 AS Discount FROM Production.ProductCostHistory GOSELECT kombiniert mit INTO
Die INTO-Klausel erstellt eine neue Tabelle und fügt die in der SELECT-Anweisung aufgelisteten Zeilen und Spalten darin ein.
Die INTO-Klausel fügt auch vorhandene Zeilen in die neue Tabelle ein. Um diese Klausel mit einer SELECT-Anweisung auszuführen, muss der Benutzer über die CREATE TABLE-Berechtigung in der Zieldatenbank verfügen.
Syntax:
SELECT <column_name1>,[, <column_name2> ...] INTO <new_table> FROM table_listZum Beispiel:
USE AdventureWorks2019 SELECT ProductModelID, Name INTO Production.ProductName FROM production.ProductModel GO 
SELECT kombiniert mit WHERE
Die WHERE-Klausel mit der SELECT-Anweisung wird verwendet, um die von der Abfrage abgerufenen Datensätze bedingt auszuwählen oder einzuschränken (besser verständlich, Datensätze filtern). Die WHERE-Klausel gibt einen booleschen Ausdruck an, um die von der Abfrage zurückgegebenen Zeilen zu untersuchen. Zeilen werden zurückgegeben, wenn der Ausdruck wahr ist, und verworfen, wenn er falsch ist.
Syntax:
SELECT <column_name1> [, <column_name2> ...] FROM <table_name> WHERE <search_condition>Vergleichsoperatoren in SELECT:
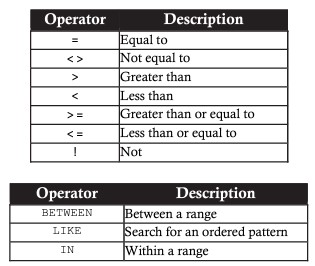
Beispiel für die Verwendung der WHERE-Klausel zum Anzeigen von Daten-Voiws Endate als angegebenes Datum
USE AdventureWorks2019 SELECT * FROM Production.ProductCostHistory WHERE EndDate ='2013-05-29' GO 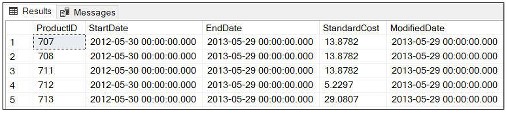
Alle SQL-Abfragen verwenden einfache Anführungszeichen, um Textwerte einzuschließen .
Zum Beispiel:
USE AdventureWorks2019 SELECT * FROM Person.Address WHERE City='Bothell' 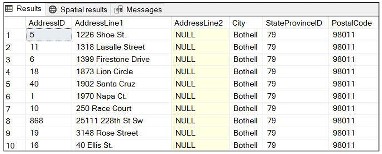
Numerische Werte müssen nicht in einfache Anführungszeichen eingeschlossen werden
Zum Beispiel:
USE AdventureWorks2019 SELECT * FROM HumanResources.Department WHERE DepartmentID < 10 GO 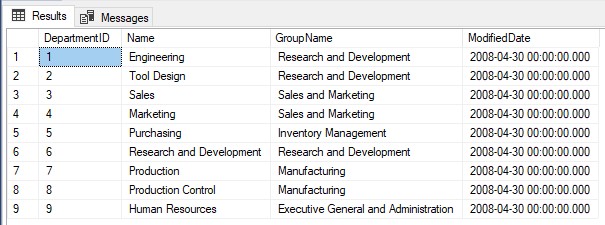
Die WHERE-Klausel kann mit Platzhalterzeichen verwendet werden. Dies ist das Zeichenkonzept, das für das LIKE-Schlüsselwort verwendet wird, um eine exakte und spezifische Abfrageanweisung zu erstellen.
| Platzhalter | Beschreibung _ | Zum Beispiel |
| _ | Stellt ein einzelnes Zeichen dar Dokumente: https://docs.microsoft.com/en-us/sql/t-sql/language-elements/wildcard-match-one-character-transact-sql?view=sql-server-2017 | wählen Sie * aus Person.Contact, wobei Suffix wie 'Jr_' |
| % | Zeichenfolgendarstellung beliebiger Länge Dokumente: https://docs.microsoft.com/en-us/sql/t-sql/language-elements/percent-character-wildcard-character-s-to-match-transact-sql?view=sql-server- 2017 | wählen Sie * aus Person.Contact aus, wobei LastNam wie 'B%' ist |
| [ ] | Stellt ein einzelnes Zeichen innerhalb des von eckigen Klammern eingeschlossenen Bereichs dar Dokumente: https://docs.microsoft.com/en-us/sql/t-sql/language-elements/wildcard-character-s-to-match-transact-sql?view=sql-server-2017 | select * from Sales.CurrencyRate where ToCurrencyCode like 'C[AN][DY]' |
| [^] | Stellt ein einzelnes Zeichen dar, das die Zeichen in eckigen Klammern negiert. Dokumente: https://docs.microsoft.com/en-us/sql/t-sql/language-elements/wildcard-character-s-not-to-match-transact-sql?view=sql-server-2017 | select * from Sales.CurrencyRate where ToCurrencyCode like 'A[^R][^S]' |
Die WHERE-Klausel kann auch mit logischen Operatoren wie AND, OR, NOT verwendet werden. Operatoren, die in Verbindung mit Suchbedingungen in der WHERE .-Klausel verwendet werden
Der UND- Operator kombiniert 2 oder mehr Bedingungen und gibt nur dann WAHR zurück, wenn beide Bedingungen erfüllt sind. Das Ergebnis gibt alle Datensätze zurück, wenn die Bedingung erfüllt ist.
Zum Beispiel:
USE AdventureWorks2019 SELECT * FROM Person.Address WHERE AddressID > 900 AND City='Seattle' GODer OR- Operator gibt TRUE zurück und zeigt Datensätze an, wenn er eine der Bedingungen in der WHERE-Klausel erfüllt.
Zum Beispiel:
USE AdventureWorks2019 SELECT * FROM Person.Address WHERE AddressID > 900 OR City='Seattle' GODer NOT-Operator ist die Negation der Suchbedingung
Zum Beispiel:
USE AdventureWorks2019 SELECT * FROM Person.Address WHERE NOT AddressID = 5GROUP BY .-Klausel
Die GROUP BY-Klausel partitioniert die Ergebnisse in eine oder mehrere Teilmengen. Jede Teilmenge hat gemeinsame Werte und Ausdrücke. Wenn eine Aggregatfunktion in der GROUP BY-Klausel verwendet wird, erzeugt die Ergebnismenge Einzelwerte für jedes Aggregat
Auf das Schlüsselwort GROUP BY folgt eine Liste von Spalten, die als gruppierte Spalte bezeichnet wird. Jede gruppierte Spalte schränkt die Anzahl der Zeilen der Ergebnismenge ein. Für jede gruppierte Spalte gibt es nur eine Zeile.
Die GROUP BY-Klausel kann mehr als eine gruppierte Spalte haben.
SELECT <column_name1>, [, column_name2 , ...] FROM <table_name> GROUP BY <column_name>Zum Beispiel:
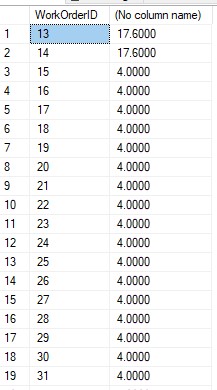
USE AdventureWorks2019 SELECT WorkOrderID,SUM(ActualResourceHrs) FROM Production.WorkOrderRouting GROUP BY WorkOrderID HAVING WorkOrderID < 50 GODas Ergebnis gibt eine WorkOrderID-Gruppentabelle zurück und summiert die ActualResourceHrs-Spalte basierend auf WorkOrderID mit WorkOrderID < 50
ORDER BY Klausel
Es gibt die Sortierreihenfolge der Spalten in einer Ergebnismenge an. Es sortiert die Abfrage nach einer oder mehreren Spalten. Die Sortierung kann in aufsteigender (ASC) oder absteigender (DESC) Reihenfolge erfolgen. Standardmäßig werden Datensätze in ASC-Reihenfolge sortiert. Um in den absteigenden Modus zu wechseln, verwenden Sie das optionale Schlüsselwort DESC. Wenn Sie mehrere Felder verwenden, behandelt SQL Server das Feld ganz links als primäre Sortierebene und die anderen als niedrigere Sortierebene.
Syntax:
SELECT <column_name> FROM <table_name> ORDER BY <column_name> (ASC|DESC)Zum Beispiel:
SELECT * FROM Sales.SalesTerritory ORDER BY SalesLastYear GO 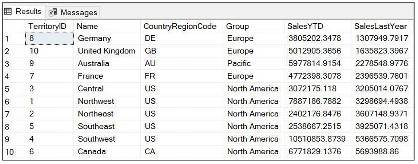
Arbeiten mit XML
Extensible Markup Language (XML) ermöglicht es Entwicklern von Tags, ihre eigenen Bedeutungen zu haben und dass andere Programme die Bedeutung dieser Tags verstehen können (ähnlich wie HTML-Tags, aber zur Datenspeicherung, nicht für Browser). XML ist das bevorzugte Medium für Entwickler, um Daten im Web zu speichern, zu formatieren und zu verwalten. Heutige Anwendungen verfügen über eine Kombination von Technologien wie ASP, .NET-Technologie, XML und SQL-Server, die zusammen arbeiten. In manchen Situationen ist das Speichern von XML-Daten in SQL Server eine vernünftige Lösung.
Die native XML-Datenbank in SQL Server hat mehrere Vorteile:
- Bessere Leistung: Abfragen von gut implementierten XML-Datenbanken sind schneller als Abfragen von Dokumenten, die im Dateisystem gespeichert sind. Außerdem analysiert die Datenbank typischerweise jedes Dokument, wenn es gespeichert wird.
- Einfaches Datenhandling: Große Dokumente können einfach gehandhabt werden (da XML strukturiert ist)
SQL Server unterstützt das native Speichern von XML-Daten mithilfe des xml-Datentyps. Die native XML-Datenbank definiert ein logisches Modell für ein XML-Dokument – als Beschreibung für die Daten in diesem Dokument – und speichert und ruft das Dokument gemäß diesem Modell ab. Das Modell muss mindestens Elemente, Attribute, PCDATA und Dokumentreihenfolge enthalten.
XML-Datentyp
Zusätzlich zu häufig verwendeten Datentypen unterstützt SQL Server 2019 XML-Datentypen. Der XML-Datentyp wird zum Speichern von XML-Dokumenten und -Segmenten in SQL Server-Datenbanken verwendet. Ein XML-Segment ist eine XML-Instanz, in deren Struktur ein Element der obersten Ebene fehlt.
Syntax:
CREATE TABLE <table_name> ([column_list,] <column_name> xml [, column_list])Zum Beispiel:
USE AdventureWorks2019 CREATE TABLE Person.PhoneBilling (Bill_ID int PRIMARY KEY, MobileNumber bigint UNIQUE, CallDetails xml) GOSpalten im XML-Stil können auch zum Zeitpunkt der Erstellung aus einer Tabelle zu einer Tabelle hinzugefügt werden. Spalten des XML-Datentyps unterstützen DEFAULT-Terme sowie die Einschränkung NOT NULL.
Zum Beispiel:
AdventureWorks2019 INSERT INTO Person.PhoneBilling VALUES (100,98326505,'<Info><Call>Local</Call><Times>45 minuetes</Times><Charges>200</Charges></Info>') SELECT CallDetails FROM Person.PhoneBilling GO 
Die DECLARE-Anweisung wird verwendet, um Variablen vom Typ XML zu erstellen. Der Zweck der DECLARE-Anweisung wird verwendet, um eine Variable in SQL Server zu deklarieren.
Syntax:
DECLARE @LOCAL_VẢIABLE datatype [= value]Lokale Variablennamen müssen mit einem @-Zeichen beginnen. Der in der Syntax angegebene value-Parameter ist ein optionaler Parameter, der hilft, der Variablen bei der Deklaration einen Anfangswert zuzuweisen. Wenn Sie keinen Anfangswert angeben, der einer Variablen zugewiesen werden soll, wird sie mit NULL initialisiert
Zum Beispiel:
DECLARE @xmlvar xml SELECT @xmlvar='<Employee name="Toan"/>'Hinweis: Der xml-Datentyp kann nicht als Primärschlüssel, Fremdschlüssel oder UNIQUE-Einschränkung verwendet werden.
Es gibt zwei Möglichkeiten, XML-Dokumente in Spalten mit XML-Datentypen namens typisiertes und nicht typisiertes XML zu speichern. Eine XML-Instanz, der ein Schema zugeordnet ist, wird als formatierte XML-Instanz bezeichnet. Ein Schema ist ein Header für ein XML-Dokument oder eine XML-Version. Es beschreibt die Struktur- und Inhaltseinschränkungen von XML-Dokumenten, indem XML-Schemas Versionen oder empfohlenen XML-Dokumenten zugeordnet werden, da Daten validiert werden können, während sie in der Typspalte xml data gespeichert werden.
SQL Server führt keine Validierung für die in die XML-Spalte eingegebenen Daten durch. Es stellt jedoch sicher, dass die Daten mit einem guten Standard gespeichert werden. Ungestylte XML-Daten können je nach Bedarf und Umfang der Daten erstellt und in Tabellenspalten oder Variablen gespeichert werden.
Der erste Schritt bei der Verwendung von typisiertem XML besteht darin, das Schema zu registrieren. Syntax:
CREATE XML SCHEMA COLLECTION <Schema_Collection_name> AS '[xmldefine]'Zum Beispiel:
CREATE XML SCHEMA COLLECTION OrderSchemaCollection1 AS N'<?xml version="1.0"?> <xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:element name="Customer" /> </xsd:schema>' GOErstellen Sie als Beispiel eine Tabelle vom Datentyp Order:
CREATE TABLE myOrder (orderID int identity not null, orderInfo xml (OrderSchemaCollection))Geben Sie den neu erstellten XML-Typ ein:
insert into myOrder values ('<Customer></Customer>')Darüber hinaus können wir mithilfe der Schema-Collaction eine XML-Variable vollständig erstellen. Zum Beispiel:
use myDB DECLARE @order xml (OrderSchemaCollection1) SET @order = '<Customer></Customer>' select @order GO Bài viết liên quan:


Dịch vụ thiết kế Wesbite

