Create and administer the database, create users in SQL Server
Mục lục
Modify system data
Users are not allowed to directly update information in system database objects, such as system tables, system store procedures, and catalog views (table of contents). ). However, users can take advantage of a complete set of administrative tools that allow them to administer the entire system and manage all users and database objects as follows:
- SSMS Administration ultilities : From SQL Server 2015 onwards, several SQL Server administration utilities are integrated into SSMS. This is the core admin console for a SQL Server installation. It allows complete high-level administrative functions, scheduling routine maintenance tasks, etc.
- SQL Server Management Objects (SQL-SMO) API : includes complete features for administering SQL Server applications
- Transact-SQL scripts and stored procedures : these are system stored procedures and T-SQL DDL statements
User-defined database
In SQL Server, users can create their own databases, called user-defined databases, and work with them. The purpose of these databases is to store user data.
Each SQL Server instance can hold up to 32767 databases, each database holds up to 32767 files. When you create a database in SQL Server there will be at least two files on the operating system, a data file and a log file. Data files contain data and objects such as tables, indexes, stored procedures, and views. Log file records database changes for the purpose of archiving and assisting in returning to the state of the database
Basically SQL Server database we only need to care about those files, all that belongs to a database is encapsulated in these files and you can bring the database from one place to another simply by copying all these files to another machine (of course there are other ways like backup/restore) and attach them to SQL Server on that server.
In summary, SQL Server Database has 2 main types of files:
- .mdf file is called as main database file, contains schema and data
- .ldf file contains logs
- In addition, the database can use the second database file, with the extension .ndf
Create Database by T-SQL (Create database with T-SQL)
Full syntax (note, clauses in [ ] are optional:
CREATE DATABASE DATABASE_NAME [ON [PRIMARY] [<filespec>[,...n] [,<filegroup>[,...n]] [LOGON {<filespec[,...n]}] ] [collate collation_name] [;]Explain:
- DATABASE_NAME: the name of the database to create
- ON: indicates where the file is stored in the hard drive.
- PRIMARY: associated with <filespec> defines primary files
- <filespec> : control of the files . attribute
- <filegroup>: controls of the <filegroup> . attribute
- LOG ON: indicates the archive file for the log files.
- COLLATE : specifies the collation code for the database, Collation defines the rules for comparing and sorting character data based on local and language-specific criteria (usually choosing collation in case of need) database can store unicode data
For example:
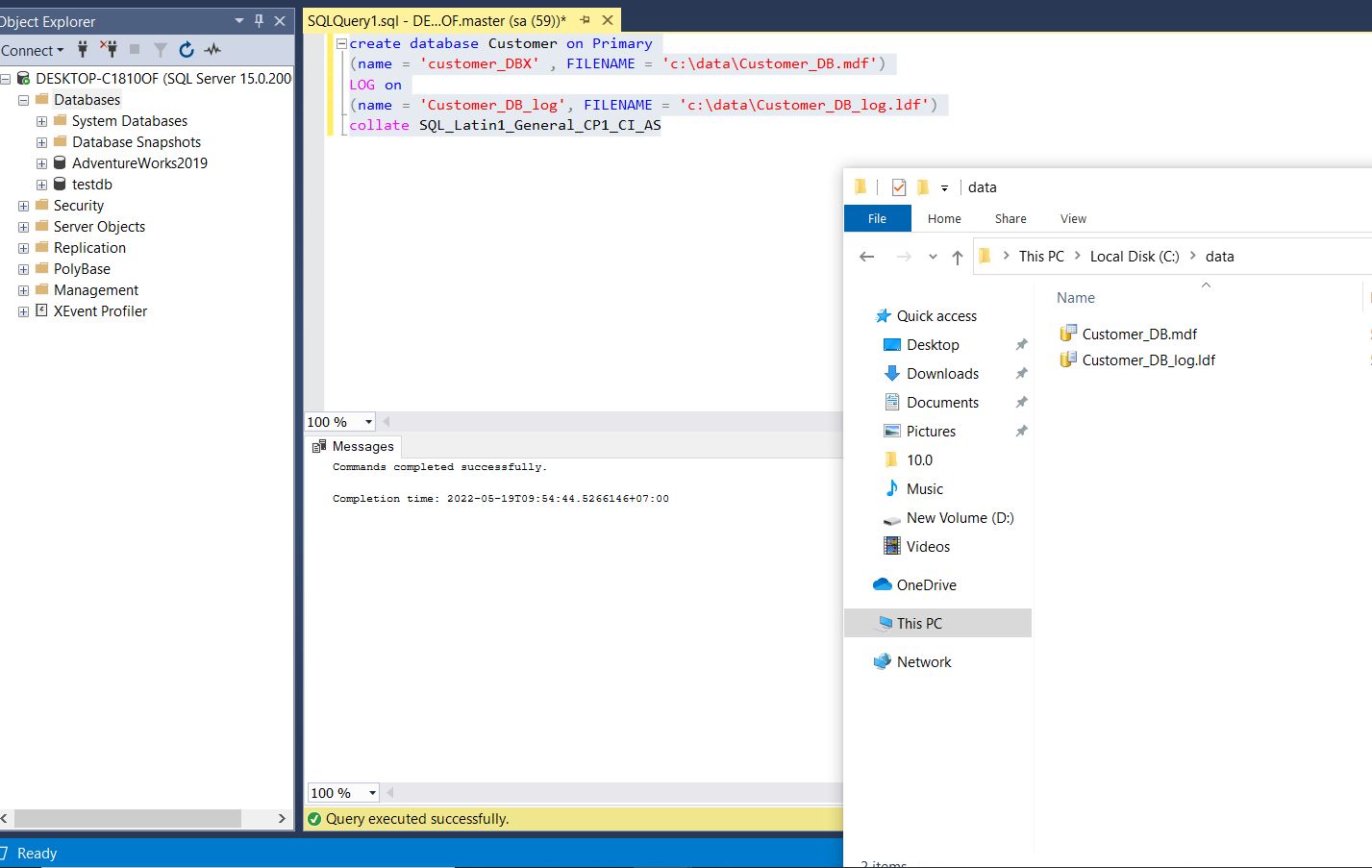
CREATE DATABASE [Customer] ON PRIMARY (NAME = 'Customer_DBX', FILENAME = 'C:DATACustomer_DB.mdf') LOG ON (NAME = 'Customer_DB_log', FILENAME = 'C:DATACustomer_DB_log.ldf') COLLATE SQL_Latin1_General_CP1_CI_ASAfter running the command SQL Server will create a new database with a hard file stored in the path C:data
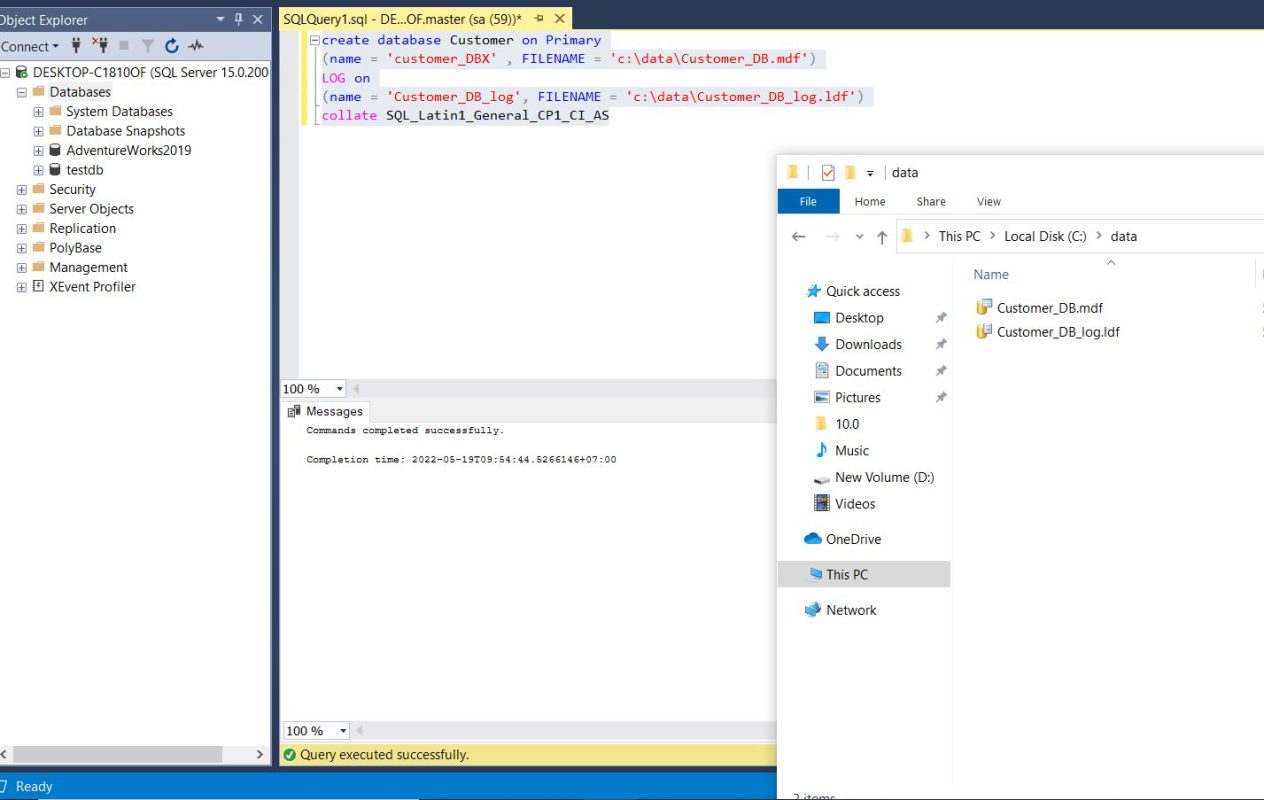
Refresh object Explorer to display the Customer database again
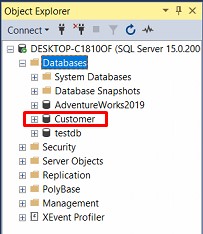
Or more succinctly:
CREATE DATABASE [CustomerDB] -- Voi cach tao nay duong dan file database se do Microsoft SQL dinh nghia
Modify Databases
As the user-defined database grows or decreases, the database size will be expanded or reduced automatically or manually. Based on requirements that change over time, there are some situations where database modifications are required.
ALTER DATABASE database_name {<add_or_modify_files> | <add_or_modify_filegroups> | <set_database_options> | MODIFY NAME = new_database_name | COLLATE collation_name } [;]Explain:
- database_name: db . name
- MODIFY NAME = new_database_name: is the new database name you want to change to
- collate collation_name: collation name of db
- <add_or_modify_files>: add files, delete files or edit files
- <add_or_modify_filegroups>: filegroups can be added, edited or deleted from the database
- <set_database_options>: is a database-level option that affects database properties that can be set for each database. These options are unique to each database and do not affect other databases.
Example to edit database name:
ALTER DATABASE Customer MODIFY NAME = CusDBCreate SQL Server User (create SQL Server user)
For example:
-- Creates the login toanngo92 with password '1234'. CREATE LOGIN toanngo92 WITH PASSWORD = '1234'; GO -- Creates a database user for the login created above. CREATE USER toanngo92 FOR LOGIN toanngo92; GODatabase owner (Database ownership)
In SQL Server, the ownership of the user-defined database can be changed. The ownership of the system database cannot be changed. The system procedure named sp_changedbowner is used to change the ownership of the database.
Syntax:
sp_changedbowner [@loginname=]'login'With login as the existing username.
After sp_changedbowner is executed, a new owner (called dbo) will be selected as the owner of the database. Dbo will have the authority to handle all database actions. Owner of master, model, tempdb (db in system database) cannot change owner.
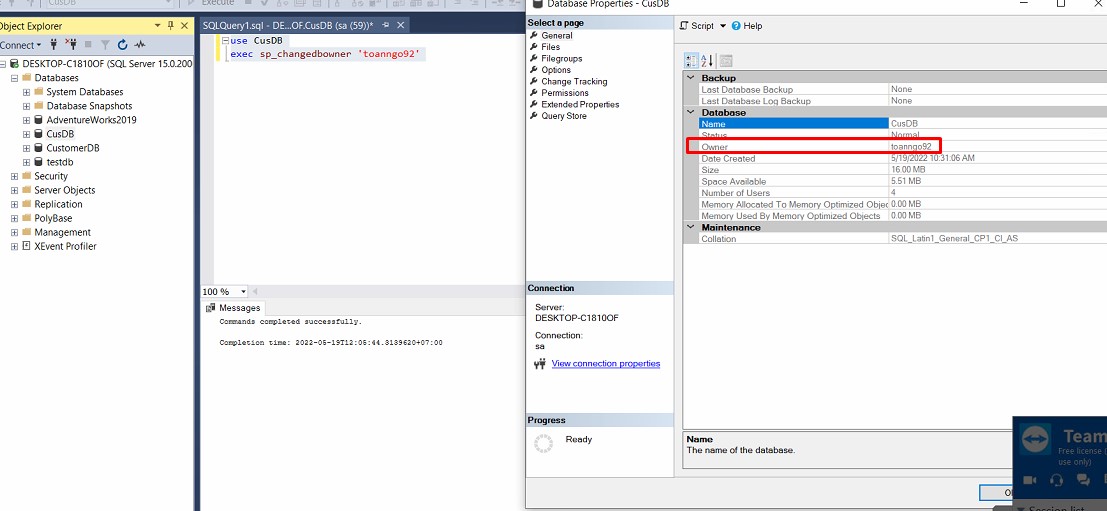
For example:
use 'CusDB' sp_changedbowner 'toanngo92'After running the command, the CusDB database has changed its owner to ‘toanngo92’, then the login account named ‘toanngo92’ can directly manipulate the CusDB database
Setting Database Options
Database-level options specify database properties and can be set for each database. These options are unique to each database, and do not affect other databases. The database options are assigned default values when the database is created, which can then be changed using the SET clause in the ALTER DATABASE statement .
Database options in SQL Server
| Option type | description |
| Automatic options | Control the automatic behavior of the database |
| Cursor options | Cursor behavior control |
| Recovery options | Control the recovery (fallback) model of the database |
| Miscellaneous options | ANSI . Standard Control |
| State options | Control the state of the database, such as online/offline, user connection |
Note: configure database settings via procedure named sp_configure system stored procedure or SQL Management Studio.
Example of executing the AUTO_SHRINK option for the CusDB database to ON. Options when turned on, the database will automatically shrink / shrink to save more memory (but this feature is not recommended)
Docs AUTO_SHRINK: https://docs.microsoft.com/en-us/sql/relational-databases/policy-based-management/set-the-auto-shrink-database-option-to-off?view=sql-server -2017
USE 'CusDB' ALTER DATABASE 'CusDB' SET AUTO_SHRINK ONFilegroups
In SQL Server, the data files in the hard drive are used to store the database. Data files can be further subdivided into file groups to improve performance. Each file group (filegroup_ used to group related files together stores a database object. Every database has a main file group by default. This file group contains data files. The main file group and the data file are automatically generated with default attribute values at the time of administration, data allocation, and location purposes.
For example, there are 3 files named customer_data1.ndf , customer_data2.ndf , customer_data3.ndf , which can be created on 3 corresponding hard drives, they can be assigned to 1 filegroup named customer_fgroup1. a table can then be specifically created on the customer_fgroup1 file group. Then a table can be created specifically on filgroup customer_fgroup1. Queries for data from the table will be spread across three drives thus further improving performance.
Add Filegroups to the current database
Filegroups can be created when the database is first created or can be created after files have been inserted into the database. However, files cannot be moved to another filegroup after the file is included in the database.
File cannot be a member of more than one filegroup at the same time. Only a maximum of 32,767 filegroups are allowed per database. Filegroups can contain only data files. Transaction log file cannot belong to filegroup.
Example of creating a filegroup that puts the filegroup in the database during initialization:
CREATE DATABASE [SalesDB] ON PRIMARY (NAME = 'SalesDB' , FILENAME = 'C:dataSalesDB.mdf' , SIZE = 3072KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB), FILEGROUP [MyFileGroup] (NAME = 'SalesDB_FG', FILENAME='C:dataSalesDB_FG.ndf' , SIZE = 3072KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB) LOG ON (NAME = 'SalesDB_log', FILENAME='C:dataSalesDB_log.ldf', SIZE = 2048KB , MAXSIZE = 2048GB , FILEGROWTH = 10%) COLLATE SQL_Latin1_General_CP1_CI_AS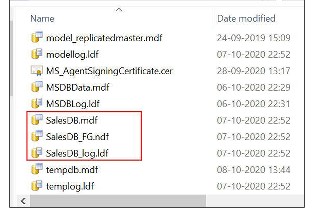
Syntax when putting the filegroup in the current database:
ALTER DATABASE database_name (<add_or_modify_files> |<add_or_modify_filegroups> |<set_database_options> |MODIFY NAME=new_database_name |COLLATE collation_name )[;]For example:
USE 'CusDB' ALTER DATABASE 'CusDB' ADD FILEGROUP FG_ReadonlyAfter the command is executed, SQL Server displays the message ‘Command(s) completed successfully’ and the filegroup FG_Readonly is included in the current database as ‘CusDB’.
Default Filegroup
Objects are assigned to the default file group when they are created in the database. Filegroup PRIMARY is the default filegroup. The default filegroup can be changed using the ALTER DATABASE statement. System and table objects remain in the PRIMARY filegroup, although ALTER still does not enter the new filegroup.
Example how to create a new file, put in filegroup FG_ReadOnly and set FG_ReadOnly as default filegroup
USE 'CusDB' ALTER DATABASE 'CusDB' ADD FILE (NAME = CusDB1, FILENAME = 'C:dataCusDB1.ndf') TO FILEGROUP FG_ReadOnly ALTER DATABASE CusDB MODIFY FILEGROUP FG_Readonly DefaultTransaction Log
Transaction log in SQL Server records all transactions and modifications in the database created by each transaction. Transaction log is an important component in the database. It can be the only solution to access recent data source in case of system failure
Transaction log supports the following operations:
- An incomplete transaction is rolled back or the database engine detects an error. Logs are used to rollback modifications.
- If the server running SQL Server fails, the database may be in an inconsistent state. When an instance of SQL Server is started, it runs a restore of each database.
- The database can be restored to the point of failure after hardware data loss affects the database files.
- Log Reader Agent monitors the transaction log of each configured database to replicate transactions
- Backup server, database mirroring, and log shipping solutions depend on the transaction log.
Working with transaction logs:
SQL Server databases have at least one data file and one transaction log file. Transaction log data and information are stored separately, preferably on separate drives. These files are used by a database.
SQL Server uses the transaction log of each database to roll back transactions. The transaction log is a serial record that stores all the modifications that have occurred in the database as well as the transactions that have made the modifications. This log holds enough information to undo the modifications made in each transaction. The transaction log records the allocation and allocation of pages as well as the commit or rollback of each transaction. This feature allows SQL Server more flexibility in restoring data state.
The rollback of each transaction can be implemented in the following ways:
- Transactions are moved forward when transaction log is applied
- A transaction is rolled back when an incomplete transaction is backed up.
Add Log files to the database
Syntax to edit database and add log files:
ALTER DATABASE database_name ( ... ) [;] <add_or_modify_files>::= {ADD FILE <filespec>[,...n] [TO FILEGROUP {filegroup_name|DEFAULT}] | ADD LOG FILE <filespec>[,...n] | REMOVE FILE logical_file_name | MODIFY FILE <filespec> }Create database using SSMS
Steps to create a database using SSMS:
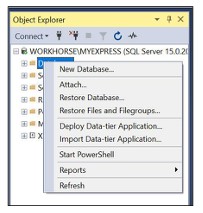
- In Object Explorer, connect to the instance of SQL Server Database Engine, then expand the instance by clicking the ‘+’ icon next to the instance.
- Right-click the database, click New Database as shown in Figure 1.1
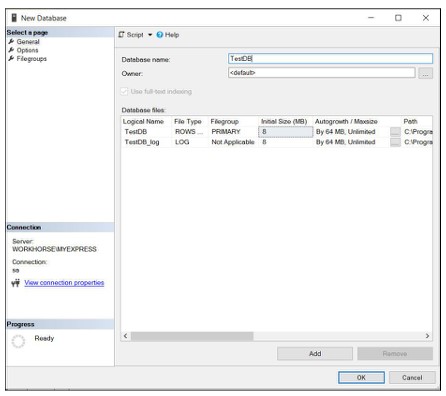
- In the New Database dialog box, enter the name of the database you want to create
- If the database is created with default values, click OK to finish. If not, continue to choose the parameters, configure the database as shown in Figure 1.2
- To change the owner name, click the […] button and select another owner
- To change the default values of primary data and transaction log files, in the Database files table, click on the corresponding cell and enter the value.
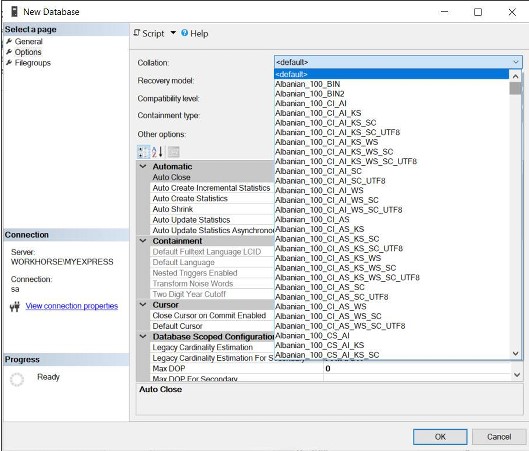
- To change the database collation, click the options tab, then select the collation from the list as shown in Figure 1.3
- To change the recovery model, select the options tab, then select the recovery model from the selectbox as shown in Figure 1.4
- To change other database options, edit the information in the options tab.
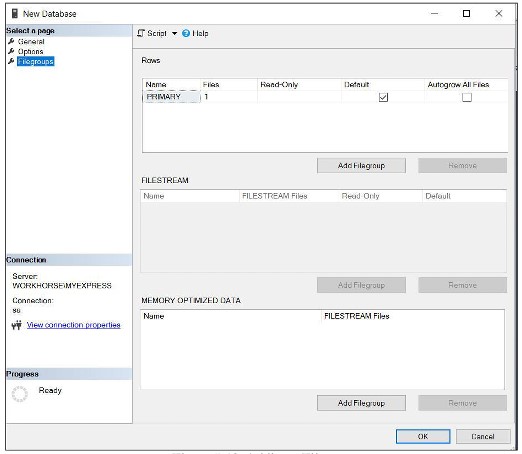
- To add a filegroup moiws, click on the Filegroups tab. The next step is to click the Add button, then enter the lieej filegroup as shown in Figure 1.5
- To add high nanag properties to the database, select the Extended Properties tab
- In the Name column, enter a name for the extend property
- In the Value column, enter a value for the extend property. For example, we can fill in 1.2 lines to describe the database.
- Click OK to create the database
Drop Database (delete database)
Before dropping DATABASE, make sure you keep some recent backups if the database is important, this is the rule in all cases. Deleted database can only be re-created by restoring the backup.
Drop Database syntax:
DROP DATABASE [databasename]To delete the database using SSMS, do the following:
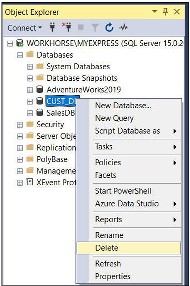
- In Object Explorer, connect to the SQL Seerver Database Engine instance, then expand the instance by pressing the ‘+’ sign.
- After expanding, select database, right click and click Delete
- Make sure the database is selected, click DELETE
Create database Snapshots
Database snapshot is a feature introduced from SQL Server 215. This feature provides readonly, stic view for SQL database. If the user manipulates and runs the wrong command, causing the database to fail, the source database will switch back to the state when the snapshot is created. SSMS does not support creating snapshots but must use T-SQL statements to do this.
Advantages of snapshots:
- Provide convenient and read-only copy version of data
- When queried, no performance degradation
- Snapshot file is light and quick to initialize
Disadvantages of snapshots:
- Unable to create snapshot backup
- Snapshot must exist on the same database server as the source of the database
- New users cannot be assigned data access rights in snapshot
Syntax:
CREATE DATABASE database_snapshot_name ON ( NAME = logical_file_name , FILNAME = 'os_file_name' )[,...n] AS SNAPSHOT OF source_database_name [;]Explain:
- database_snapshot_name: name of database snapshot
- ON (NAME = logical_file_new, FILENAME = ‘os_file_name’): list of files in the source database. For snapshots to work, all data files must be unambiguously identified
- AS SNAPSHOT OF source_database_name: source database named source_database_name
Example of creating a snapshot for the AdventureWorks2019 database:
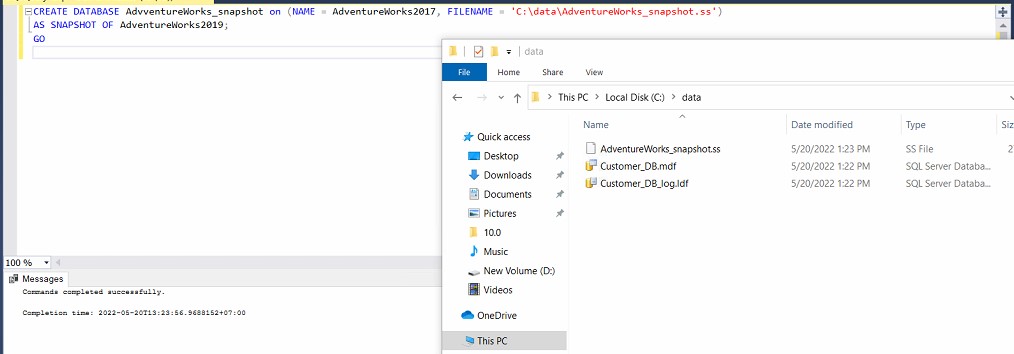
CREATE DATABASE AdvventureWorks_snapshot on (NAME = AdventureWorks2017, FILENAME = 'C:dataAdventureWorks_snapshot.ss') AS SNAPSHOT OF AdventureWorks2019; GOThe reason why the statement on NAME = AdventureWorks2017 and not 2019 is because 2019 will get an error, read this docs:
Result: