Index in SQL Server
architectures
Mục lục
Introduction to index
An index is a special data structure associated with a table or view to speed up queries. In a nutshell, when you index a field in a table, the values of that field will be organized and stored in a structured way, which will help query data more efficiently in terms of performance and speed. The list of common indexes in SQL Server is as follows:
| Index type | Describe |
| Clustered | It sorts and stores data rows of a table or view in order based on keys. Clustered index implemented in B-Tree structure supports getting row data, based on key values indexes |
| Nonclustered | Non-clustered indexes are deleted on a table or view that has data in a clustered structure or on a heap. Each index row in the non-clustered index contains the key value and a row locator. The locator points to the row of data in the clustered index or the heap with the value of key. The rows in the index are stored in the order of the index key values, but the data rows are not guaranteed to be in any particular order unless a clustered index is created on the table. |
| Unique | A unique index ensures that the index key does not contain duplicate values and thus each row in the table or view is in some way unique. Uniqueness can be a property of both clustered and nonclustered indexes. |
| Columnstore | Index Columnstore stores and manages data using in-memory column-based data storage and column-based query processing Index Columnstore works when data storage workloads primarily perform built-in loading and read-only queues. Use index columnstore to achieve up to 10x query performance over traditional row-oriented storage and up to 8x data compression for uncompressed data sizes |
| filtered | Clustered indexes are optimized to include queries that select from a well-defined subset of data. It uses a filter predicate to index part of the table rows. A well-designed filtered index can improve query performance, reduce index maintenance costs, and reduce index storage costs compared to full-table indexes. |
| Spatial | It provides the ability to perform some more efficient operations on spatial objects within a column of geometry data type. |
| XML | Due to the large XML column sizes, search queries in these columns can be slow. You can speed up these queries by creating an XML index per column. The XML index can be a clustered index or a nonclustered index. |
There are also other types of indexes like Hash, Memory optimize nonclustered, index with included column, index on computed column, full text.
SQL Server uses indexes similar to how a book is indexed. For example, considering a situation where we want to find all the “INSERT” keys in a SQL learning book, the immediate approach taken would be to scan each page of the book starting at the start page, then bookmark each time the word “INSERT” is found, up to the end of the book. This approach takes time and effort. The second way used is to use the book’s table of contents and go to the page where the results talk about INSERT and find that page, use it. Method 2 results similar to method one but saves more time and effort.
When SQL Server does not define an index, it will behave like the first way in the example, SQL engine will have to access each record in the database, in database terms, this behavior is called called table scan or just scan.
Table scan is not inefficient, but in some specific situations we will need to use another solution that is to use indexes to increase performance, because as the data table grows larger with the number of records increasing. to millions, scans will be slow and resource-intensive, in this situation, indexes are always recommended.
Data storage overview
A book contains pages, inside are paragraphs and sentences, similar to SQL Server storing data in units called data pages. These pages contain data in rows.
Each page of the book has physical dimensions. Similarly, in SQL Server all data pages have the same size of 8KB. That is, a database contains 128 pages of data per megabyte (MB) of storage space.
A page begins with a 96byte header, which stores system information about the page, which includes:
- Number of pages
- Page Style
- Amount of free space in the page
- The object’s attribution ID for the attributed page
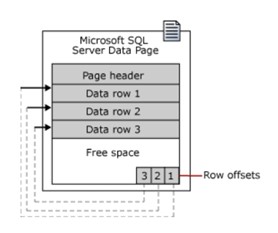
Note: data page is the smallest unit of data storage. An allocation unit is a collection of data pages grouped together based on page type. Grouping will make data governance more efficient.
Data files
All input and output tasks in the database are handled on the page layer. This means that the database engine reads or writes data pages. A set of eight consecutive pages is called an extent .
SQL Server stores data pages in files called data files. The space allocated for the data file is divided into the number of sequentially arranged data pages, the pages start from 0 , geometric representation as shown below.
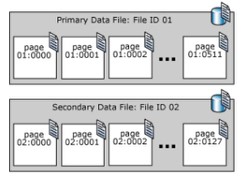
There are 3 types of 3 data files explained as follows:
- Primary: The main file is automatically created at the time of database creation, this file has references to all the remaining files in the database. The recommended and default extension for primary data files is .mdf
- Secondary: are optional user-defined data files. Data can be spread across multiple drives by placing each file on a different drive. The recommended extension for secondary data files is .ndf
- Transaction Log: Log files store information about the history of modifications in the database. This information is useful for backup data recovery such as a sudden power failure or the need to move the database to another server. There is at least one log file in each database. The recommended extension for log files is .ldf
Requirement for indexes
To facilitate quick retrieval of data from a database, SQL Server provides an indexing feature. Similar to a book’s table of contents, an index in a SQL Server database contains information that allows you to search data one at a time. correctly without scanning the entire table.

Index
In a table, the records are stored in the order they were entered, they are stored in the database without being sorted or in other words it is sorted by the input history. When data is retrieved from the table, the entire table will need to be scanned, which slows down the process. To speed up the process, we do something called indexing.
When an index is created in the table, it creates a sorted version of the record, which speeds up locating and retrieving data during a search.
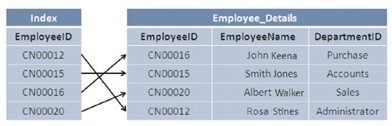
Index is automatically created when PRIMARY KEY and UNIQUE constraints are defined in the table, indexing reduces disk read and write tasks and consumes less system resources.
Syntax:
CREATE INDEX <index_name> ON <table_name> (<column_name>)Index points to the position of the record in the data page instead of searching through the table. Some features of the index:
- Indexes speed up a query that joins a table or handles sorting tasks.
- Index implements the uniqueness of rows if defined when you create the index.
- Indexes are created and maintained in forward and reverse sort.
The script
For example, in a phone book, there will be a large amount of data that is sorted and accessed frequently, the data will be stored in alphabetical order. If the data is not sorted, it is nearly impossible to find a specific phone number quickly.
Similarly, in a database table that has a large number of records and needs to be queried frequently, the data will be sorted for faster querying. When an index is created for a table, the index physically or logically sorts the records. Therefore, finding the specified record becomes faster and reduces the system resource load.
group-wise access data
Indexes are useful when data is accessed in groups. For example, you want to create a modification that switches departments for the HR group based on the departments the personnel are working on in the database. In this situation it is possible to create an index for the DepartmentName column before accessing the records.
This index will generate logical data fragments and group records by departments, which will limit the amount of data that is actually scanned during data retrieval.
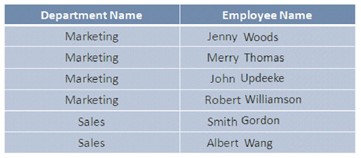
Index architecture
In SQL Server, the data in the database can be stored in a certain or random arrangement. If the data is stored in an ordered manner, the data is said to be represented in a clustered structure. If the data is stored randomly, it is called a heap structure.
The image illustrates 2 Heap and Clustered structures:
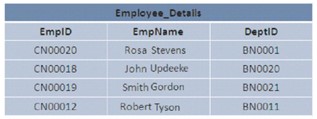
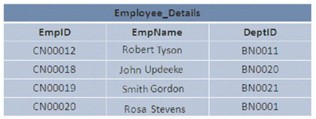
B-Tree
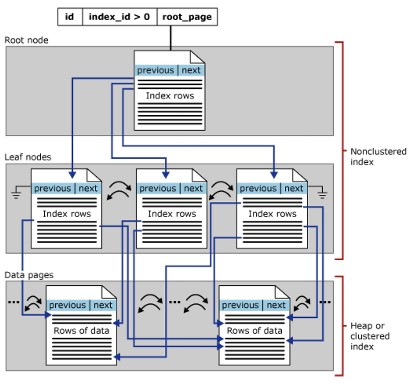
In SQL Server, indexes are organized in a B-Tree structure, each page in a B-tree index is called an index node. The highest node is called the root node. The bottom note in the index is called leaf nodes. Any layer between the root node and the leaf node is called an intermediate node.
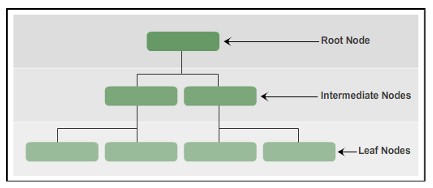
B-Tree index goes from the top of the node to the bottom by pointer.
B-Tree index structure
In the B-Tree structure of an index, the root node includes an index page. The index page contains a pointer and points to the index page representing the first intermitiate layer. These index pages in turn point to the index pages present at the next intermediate level. There can be multiple intermediate tiers in a B-Tree index. The leaf node in the B-Tree index has a data page that contains record data or contains a data page that stores index records that point to data records on the table.
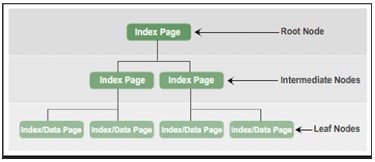
In summary, the node types in the B-tree index comply:
- Root Node: contains an index page with a pointer to the index pages in the intermediate layer.
- Intermediate Nodes : contains index pages with pointers to index pages in the intermediate layer or index or data pages in the leaf layer.
- Leaf Nodes: Contains data pages or index pages that point to data pages.
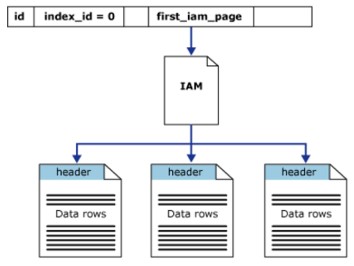
Heap structure
The heap is a table without a clustered index. This means that, in the heap structure, the data pages and registers are not sorted. The only link between data pages is the information recorded in the Index Allocation Map (IAM) page.
See more about the term heap structure in data structure: https://en.wikipedia.org/wiki/%C4%90%E1%BB%91ng_(c%E1%BA%A5u_tr%C3%BAc_d%E1 %BB%AF_li%E1%BB%87u)#:~:text=In%20khoa%20h%E1%BB%8Dc%20m%C3%A1y%20t%C3%ADnh,%C4%91%C6%B0% E1%BB%A3c%20g%E1%BB%8Di%20l%C3%A0%20max%2Dheap.
The heap has a row in sys.partitions, with index_id = 0 for each partition used by the heap. By default, a heap has its own partition, when the heap has multiple partitions, each partition will have a heap structure that holds the defined data. For example, the heap has 4 partitions, there will be 4 heap structures, each in a partition.
At a minimum, each heap will have one IN_ROW_DATA allocated per partition unit. The heap also has LOB_DATA allocated per partition unit, if it contains a large object (LOB) column. It will also have a ROW_OVERFLOW_DATA allocation per partition unit, if it does not contain columns of known length, the maximum size limit is 8060 records.
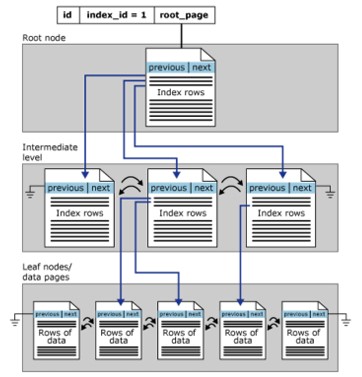
Clustered index structure
Clustered indexes are organized in a B-Tree format. Each page in the B-Tree index is called an index node. Similar in concept, the top node of the clustered index is also the root node and the bottom node is the leaf node,
- Leaf nodes contain the basic data pages of the table, the root and intermediate layers contain the index pages that hold the index rows. Each index contains a key value and pointer to an intermediate page in the B-tree or a data row in the leaf layer of the index.
- By default, a clustered index has a single partition. When a clustered index has multiple partitions, each partition will be a B-Tree structure containing the value of a specified partition.
- The clustered index also has a LOB_DATA allocated to each partition if it is contained within a LOB column (large object). And it also has a ROW_OVERFLOW_DATA allocation in each single partition.
NonClustered Index Structure
A nonclustered index has the same B-Tree structures as a clustered index, but with the following differences:
- The data rows of the table are not physically stored in the order determined by their undifferentiated keys.
- In the nonclustered index structure, the leaf layer will contain index rows.
- Nonclustered indexes are useful when you need multiple ways to find data.
- When a clustered index is recreated or the DROP_EXISTING option is used, SQL Server builds the existing nonclustered indexes,
- A table can have up to 888 nonclustered indexes
- Create a clustered index before creating a nonclustered index.
Column Store Index (Column Store Index)
Columnstore index is a feature of SQL Server that aims to store, retrieve, and manage data using columnar data, which is called columnstore.
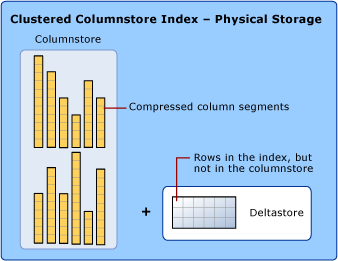
Columnstore index uses two types of data storage: rowstore and columnstore format.
Columstore index is mainly used for the following reasons:
- Reduced storage costs
- Improve performance
Details of the columnstore,rowstore,deltastore formats are as follows:
- Columnstore : data is logically organized in tables with rows and columns physically stored in column group data format.
- Rowstore : Data is logically organized as a table with rows and columns, then physically stored in a rowgroup data format.
- Deltastore : It holds the position of rows when they have too little data to compress into columnstore. Deltastore stores rows in the rowstore format.
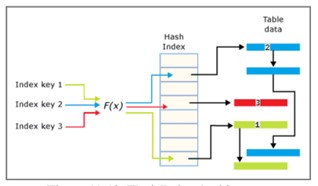
HashIndex
Hash index consists of an array of pointers and each element in the array is called a hash bucket.
- Each bucket is 8 bytes in size, used to store the memory location of the key in a link list entry structure.
- Each entry is a value for the index key, which is the corresponding address of the row in the memory-optimized table.
- Each entry points to the next entry in a link list entries, all of which are chained (which can be interpreted as a chain lock to the current bucket).
The number of buckets will have to be defined at definition time and have some of the following properties:
- Short list links handle faster than long list links.
- There can be at most 1,073,741,824 buckets in the hash index.
XML Index
An XML index can be created for columns of XML data type. They will index tags, values, and paths inside XML instances within columns and increase query performance. Your application may have an advantage with an XML index in the following cases:
XML column queries are common in the workload. The resource cost of maintaining the index xml during data changes must be considered.
When XML values are relatively large and the parts accessed are relatively small, index construction avoids the need to parse the entire data at runtime and is beneficial for index lookups for query processing. effective.
There are two types of XML indexes:
- Primary XML index
- Secondary XML index
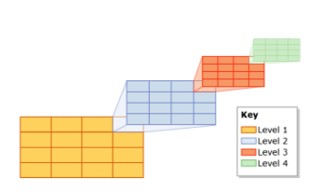
Spatial Index (spatial index)
In SQL Server, spatial indexes use B-trees, which means that indexes must be represented in two spatial dimensions in the linear arrangement of the B-tree. Therefore, before reading the data inside the spatial index, SQL Server implements a uniform hierarchical spatial stratification model. The indexing process separates the space into a four-level grid hierarchy.
Full-text index
Creating and maintaining a full-text index involves indexing using a process known as aggregation also known as crawling.
Types of information collection:
- Full population
- Automatic / manual population based on change tracking
- Incremental population fierce on timestamp
Create Clustered Index
The CREATE CLUSTERED index statement allows the user to create a CLUSTERED index for a specified column and table.
Syntax:
CREATE CLUSTERED INDEX index_name ON table_name (column1,column2,...);For example:
USE AdventureWorks2019 CREATE TABLE Production.Parts( part_id INT NOT NULL, part_name VARCHAR(100) ) CREATE CLUSTERED INDEX ix_parts_id ON Production.parts (part_id);RENAME INDEX
sp_rename is a system stored procedure that allows you to rename any object the user has created in the current database including tables, indexes, columns.
Syntax:
EXEC sp_rename index_name,new_index_name, N'INDEX';For example:
EXEC sp_rename N'Production.parts.ix_parts_id', N'index_part_id',N'INDEX';Or right click the index on the object explorer and select the option rename
DISABLE INDEX
To disable the index, the ALTER INDEX statement is used.
Syntax
ALTER INDEX index_name ON table_name DISABLE;For example:
ALTER INDEX index_part_id ON Production.Parts DISABLE; select * from Production.PartsAfter disabling the index, when querying the data will get an error:
The query processor is unable to produce a plan because the index 'index_part_id' on table or view 'Parts' is disabled.ENABLE INDEX
To enable indexing, the ALTER INDEX statement is used.
Syntax:
ALTER INDEX index_name ON table_name REBUILD;For example:
ALTER INDEX index_part_id ON Production.Parts REBUILD;DROP INDEX
The DROP INDEX statement will remove the index from the current database.
Syntax:
DROP INDEX [IF EXISTS] index_name ON table_name;For example:
DROP INDEX IF EXISTS index_part_id ON Production.Parts;NonClustered Index
A noncluster index is a data structure that increases the speed of retrieving data from a table. Unlike a clustered index, a nonclustered index sorts and stores data piecemeal from data rows in a table.
Syntax:
CREATE [NONCLUSTERED] INDEX index_name ON table_name(column1,column2,...);For example:
CREATE NONCLUSTERED INDEX index_customer_storeid ON Sales.Customer(StoreID);Unique Index
Unique index ensures that indexkey columns do not contain duplicate values.
It can contain one or more columns, if the unique index has one column, the value of the column will be unique, in the case of a unique index with many columns, the combination of these column values is unique.
Note: the unique index can be clustered or non-clustered.
Syntax to create unique index:
CREATE UNIQUE INDEX index_name ON table_name(column_list);For example:
CREATE UNIQUE INDEX AK_Customer_rowguid ON Sales.Customer(rowguid);Filtered Index
Filtered index is a nonclustered index that allows you to determine which rows are added to the index.
Syntax:
CREATE INDEX index_name ON table_name(column_list) WHERE predicate;For example:
CREATE INDEX index_cust_personID ON sales.Customer(PersonID) WHERE PersonID IS NOT NULL;Partitioned Tables and indexes
SQL Server supports two types of tables and index partitions (partitions). The data of a partitioned and indexed table is divided into an optional unit that can optionally span multiple file groups in the database. The data is partitioned horizontally, thus grouping the mapped (joined) rows into a separate partition. All partitions of a single table or index must be on the same database. The table or index is treated as an object when querying or updating data.
SQL Seerver 2019 defaults to support up to 15,000 partitions.
Benefits of partitioning:
- Convert or query data quickly and efficiently.
- Dealing with persistence tasks on one or more partitions, tasks are more efficient because their target is only on the dataset on the partition, rather than the entire table.
- Increase query performance, data on the type of queries you frequently run and hardware configuration.
The example creates a sample table with the following information:
CREATE TABLE testing_table(receipt_id BIGINT, date DATE) Specifies how exactly the table will be partitioned, in this case the date column, along with
range of values will be added in each partition. Regarding partition boundaries, you can specify LEFT or RIGHT (left or right side)
CREATE PARTITION FUNCTION partition_function (int) AS RANGE LEFT FOR VALUES (20200630,20200731,20200831);That means divided into 4 partitions as follows:
- Partition 1: all records with date <= 2020-06-30
- Partition 2: all records with date > 2020-06-30 and date <= 2020-07-31
- Partition 3: all records with date > 2020-07-31 and date <= 2020-08-31
- Partition 4: all records with date > 2020-08-31
The code below will allow you to identify the region phana each record is placed in
(SELECT 20200613 date, $PARTITION.partition_function(2020613) AS PartitionNumber) UNION (SELECT 20200713 date, $PARTITION.partition_function(2020713) AS PartitionNumber) UNION (SELECT 20200813 date, $PARTITION.partition_function(20200813) AS PartitionNumber) UNION (SELECT 20200913 date, $PARTITION.partition_function(20200913) AS PartitionNumber)
XML Index
XML data is stored in a column type whose data type XML is a data type that consumes a lot of size, called Large binary objects (BLOBs).
To represent xml data, data type size can be up to 2GB.
XML index is created on column containing xml data and stored in table and database.
For example:
CREATE PRIMARY XML INDEX PXML_PRoduct_Model_Catalog_Description ON Production.ProductModel (CatalogDescription);Primary XML index contains all the data in the XML column. To provide more performance to the XML query, you can add secondary indexes.Secondary XML indexes also use the same data set since it is the underlying primary index, but it creates a more specific index. , based on the primary index.
For example:
CREATE XML INDEX IXML_ProductModel_CatalogDescription_Path ON Production.ProductModel (CatalogDescription) USING XML INDEX PXML_ProductModel_CatalogDescription FOR PATH;Columnstore Index
Syntax:
CREATE COLUMNSTORE INDEX IX_SalesOrderDetail_ProductIDOrderQty_ColumnStore ON Sales.SalesOrderDetail (ProductID,OrderQty);Creating this index will improve the group by query when using aggregate functions, but please test again with your environment, because in my SSMS currently running this command timeout error.
SELECT ProductID,SUM(OrderQty) FROM Sales.SalesOrderDetail GROUP BY ProductId;