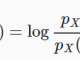SQL Advanced Features in SQL Server 2019
Mục lục
Detailed Truncate Warnings (Verbose Truncation Warnings)
This is one of the new enhanced features in SQL Server 2019 to offer. It saves time when reporting, adding new, updating large amounts of data.
For example:
Step 1 – create Sample DB 2017
USE [master] GO CREATE DATABASE [SampleDB2017] GO ALTER DATABASE [SampleDB2017] SET COMPATIBILITY_LEVEL = 140 GOStep 2 – add a few records table to the above database
USE [SampleDB2017] GO CREATE TABLE [dbo].[tbl_Color]( [ColorID] int IDENTITY not null, [ColorName] varchar(3) NULL ) GO INSERT INTO dbo.tbl_Color (ColorName) values ('Red'), ('Blue'),('Green') GOWith older versions, the error will return as follows:
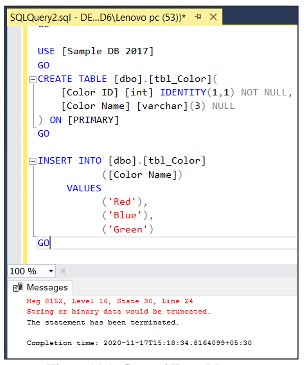
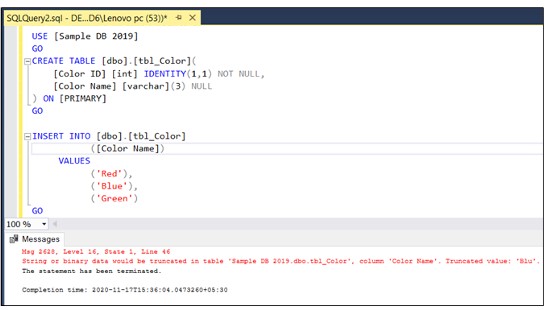
The error occurs when the record ‘Green’ is inserted in the column with nvarchar(3) data even though the error is shown, but if the number of records is large, it will be difficult to determine which error is encountered when inserting which record, in the session version 2019, the error message is fixed and shown in more detail, making it easier to identify errors.
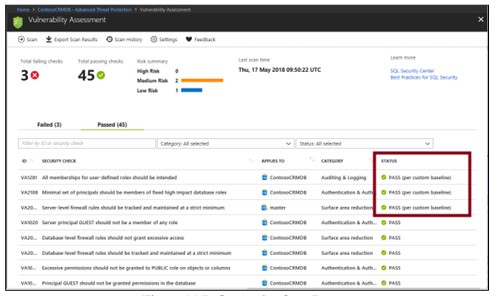
Vulnerability Assessment
It’s an easy-to-configure business that discovers, reverses or reduces database vulnerabilities.
Database admins can use it to proactively develop database security.
Vulnerability Assets are part of Azure Defensive for SQL, which is a unified package for advanced SQL security capabilities. It can be accessed and administered through Azure Defender for the SQL portal.
Note SQL vulnerability used in Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics (SQL Data Warehouse).
SQL Vulnerability Asset includes steps to improve database security, can help you:
- Meet compliance requirements with database scan reporting requirements
- Meet data privacy standards
- Monitor dynamic database environments where changes are difficult to track
The rules are based on Microsoft best practices and focus on security issues that pose the greatest risk to your database and its valuable data. The results of the scan include actionable steps to resolve each issue and provide applicable custom repair scenarios.
You can customize a vulnerability report for the environment by setting a baseline for:
- Configure permissions
- Feature configuration
- Database settings
Steps to deploy vulnerability assessment:
Run scan
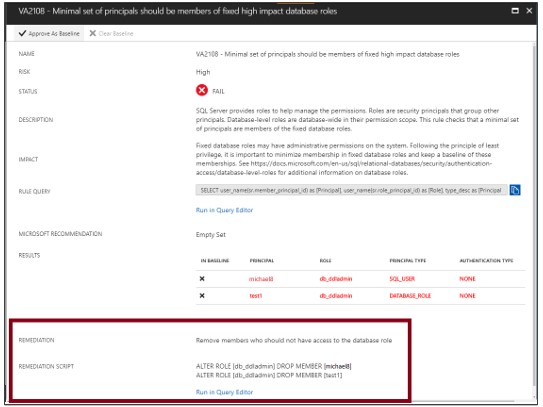
Note: the scanning process is light and safe, it only takes a few seconds and read-only the whole scan process, there will be no changes in your database.
View Report
When the scan is finished, the report will be automatically displayed on the Azure portal
Results include warnings about deviations from best practices and snapshots of your security-related settings, such as database roles and guidelines, and permissions. their relatedness.
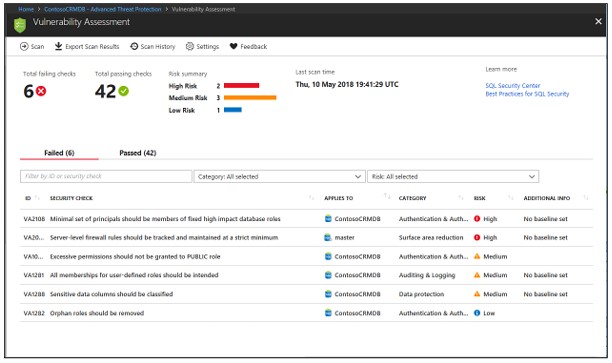
Analyze results and solve problems
Check the results again and identify in the report if there are any issues in your environment.
Dive into each failure result to understand the impact of the detection and why each security check fails.
Use the actionable remediation information provided by the report to resolve the issue.
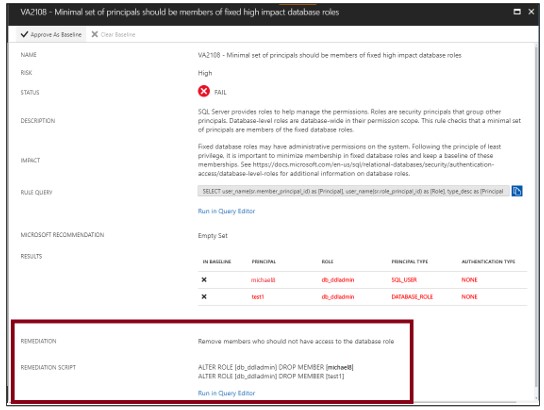
Set baseline
When reviewing your assessment results, you can mark specific results as an acceptable baseline. Results that match the baseline are considered to be pass in subsequent scans. After you have established your baseline security, vulnerability assessment reports only deviations from the baseline.
Results that match the baseline are considered to be pass in subsequent scans. After you have established your security baseline date, vulnerability assessment reports only deviations from the baseline.
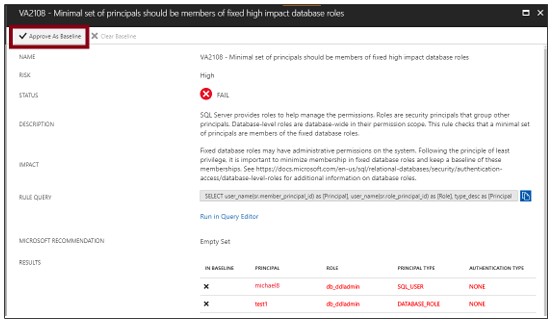
Run a new scan to see your custom tracking reports.
After installing Rule Baselines, run a scan to see custom reports, vulnerability assessment will report only security issues that deviate from your approved baseline.
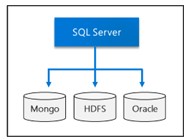
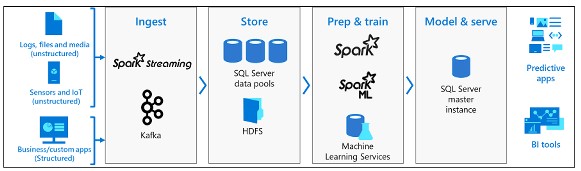
Big Data Clusters
In SQL Server 2019 Big Data Cluster allows to deploy SQL Server, Spark, and Hadoop Distributed File System (HDFS) scalable clusters…
Big Data Cluster is mainly used to:
- Deploy scalable SQL Server, Spark, and HDFS container clusters running on top of Kubernetes.
- Read, write, process big data from T-SQL or Spark SQL.
- Easily combine and analyze big-value relational data with big-value big data.
- Query an external data source.
- Store big data in HDFS managed by SQL Server.
- Query data from multiple external data sources through the cluster.
- Use data for AI, ML or other analytical tasks.
- Deploy and run applications in Big Data Cluster, virtualize data with PolyBase.
- Query data from external SQL Server, Oracle Teradata, MongoDB, ODBC data sources with external tables.
- Provide high availability for major instances of SQL Server and all databases using the Always On availability technology family.
Data Virtualization (data virtualization)
SQL Server Big Data Clusters can query external data sources without moving or copying data.
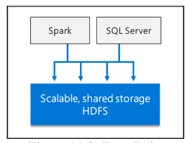
Data Lake
The Data Lake is a container store that holds large amounts of raw data in its native format.
It is a scalable HDFS storate pool.
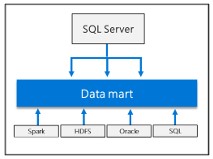
Scale-out data mart
Delivers compute and storage at scale to improve the performance of any data analysis.
Integrating AI and Machine Learning
Allows execution of AI and machine learning tasks with data stored in HDSF storage pools and data pools.
SQL Server big data cluster is a cluster of Linux containers hosted by the Kubernetes platform.
The term Kubernetes
Kubernetes is an open source container orchestration that can scale container deployments on demand. Some important Kubernetes terms:
| Terms | Describe |
| Cluster | Kubernetes cluster is a collection of machines, understood as nodes, one node controls the cluster and designates it as the master node, the remaining nodes are worker nodes. The Kubernetes master is responsible for distributing work among workers and monitoring the health of the cluster. |
| Node | A node that runs the application is contained within the container. It can be a physical machine or a virtual machine. A Kubernetes cluster can contain both physical and virtual machine nodes. |
| Pod | Pods are the atomic implementation of Kubernetes. A bucket is a logical grouping of one or more containers and required related resources |
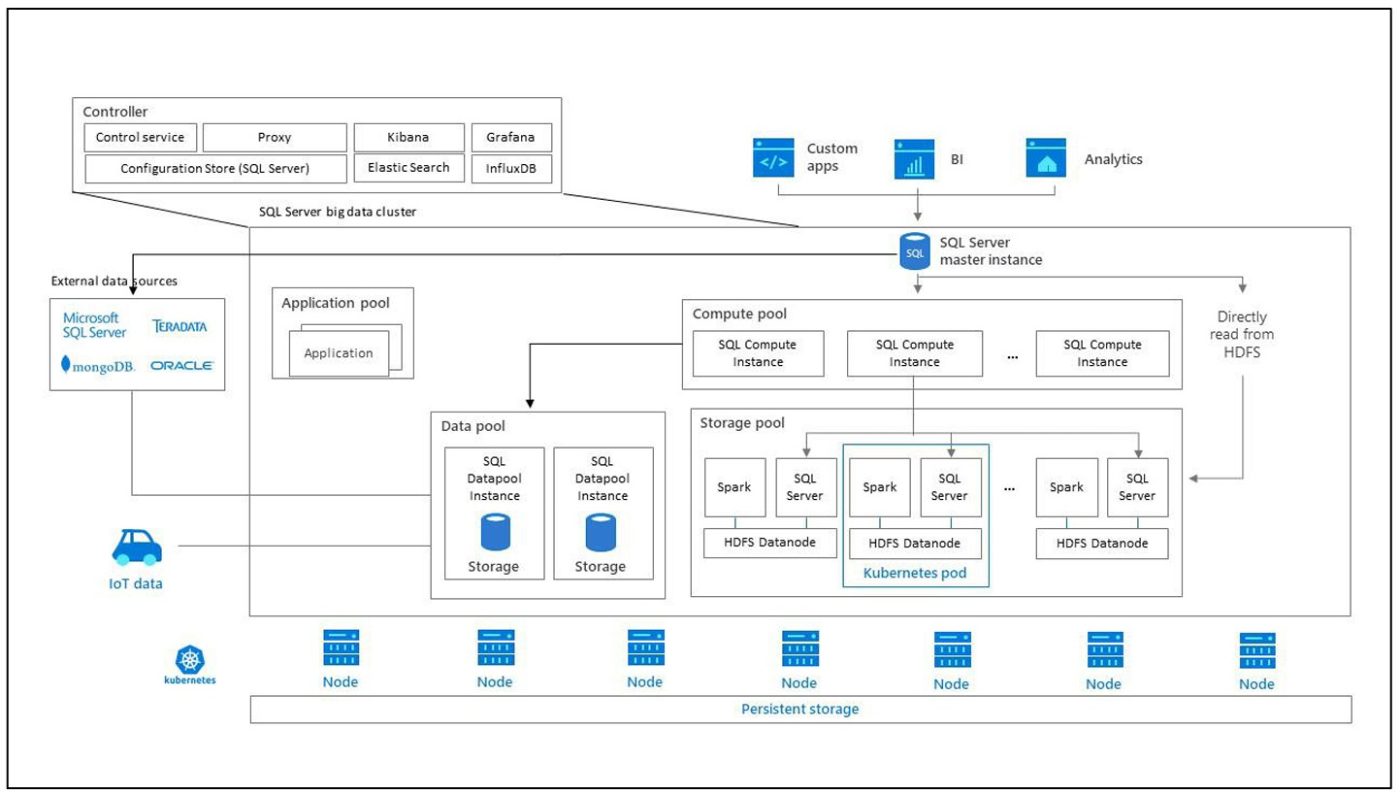
Contronller
The controller provides administration and security for the cluster. It includes control, configuration, and cluster layer services such as Kibana, Grafana, and Elastic Search.
Compute pool
Compute pool provides computing resources for the cluster. It includes SQL Server nodes running on Linux pods. Pods in a computed pool are divided into SQL Compute instances for specific processing operations.
Data Pool
The data pool is used for data persistence and caching. The data pool contains one or more pods running SQL Server on Linux. It is used to get data from SQL or Spark queries. SQL Server big data cluster data marts keep persistence in the data pool.
Storage Pool
Storage pool includes storage pool pods including SQL Server on Linux, Spark, and HDFS. All storage nodes in the SQL Server bigdata cluster are members of the HDFS cluster.