Transaction in SQL Server
Mục lục
About Transaction
There are many situations where users require changes to data in many tables in the database. In many situations, data will lose consistency when executed separately.
Suppose if the first statement is executed correctly but the next statement fails because the data is incorrect.
For example, one particular situation is money transfers in the banking system. The transfer will require one INSERT statement and two UPDATE statements:
- The user needs to reduce the balance in the source account.
- Then it is necessary to increase the balance in the account in the banking system in the destination account record.
The user will need to check that this transaction is committed and whether the same changes are made to the source and destination accounts.
Transaction definition
A reasonable unit of work must exhibit four properties, known as the Atomicity, Consistency, Isolation, and Persistence (ACID) properties, to qualify as a transaction:
Atomicity : If transaction has many operations then all should be committed. If any operation in the group fails, it will be rolled back.
Consistency: The sequence of operations should be appropriate
Isolation: Operations performed must be permanently isolated from other operations on the same server database
Durability: Operations performed on the database must be saved and permanently stored in the database.
Implimenting transaction
SQL Server supports transactions with several modes as follows:
- Autocommit Transactions: (auto-commit) Each single line of command is automatically committed when it succeeds. In this mode, there is no need to write any specific statements to start and end the transaction. This is the default mode of SQL Server
- Expicit Transactions: (explicit) Each explicit transaction begins with a BEGIN TRANSACTION statement and ends with a ROLLBACK or COMMIT transaction.
- Implicit transactions: (implicitly) a transaction is automatically captured when a previous transaction completes and each transaction is completed using the ROLLBACK or COMMIT syntax.
- Batch-scoped transactions: (batch scoped) these transactions are related to the concept of Multiple Active results set (MARS). And each implicit or explicit transaction that begins with a MARS pellet is called a batch-scoped transaction.
- Distributed transactions: (distributed transactions) it is spread over 2 or more servers known as resource managers. Transaction management must be located between the resource manager by a server component called the transaction manager. Each instance in SQL Server can act as a resource manager in distributed transactions, located by a transaction manager, such as the Microsoft Distributed Transaction Coordinator (MS DTC).
Transaction extending batches
Transaction statements determine the success or failure of the block and provide a database that can rollback operations.
Errors caught during execution of a simple batch are likely to be partially successful, which is not the desired outcome when using transactions.
This problem will lead to logical conflicts between the tables in the database.
Users can add error control code to roll back the transaction to the old state in case of an error.
Error-handling code will undo all changes before the error is encountered.
Transaction control
Transactions can be controlled through the application by defining the start and end for a transaction.
Transactions are managed by connection layers by default.
When a transaction initiates a connection, all T-SQL statements are executed on the same connection and are part of the connection until the transaction ends.
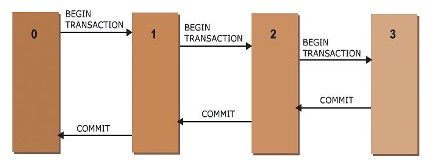
BEGIN TRANSACTION
The BEGIN TRANSACTION statement marks the beginning of an explicit transaction.
For example:
USE AdventureWorks2019; GO DECLARE @TranName VARCHAR(30); SELECT @TranName = 'FirstTransaction'; BEGIN TRANSACTION @TranName; DELETE FROM HumanResources.JobCandidate WHERE JobCandidateID = 13;COMMIT TRANSACTION
The COMMIT TRANSACTION statement marks the endpoint, which is a commit that signals the end of an implicit or explicit transaction.
COMMIT [TRAN | TRANSACTION] [transaction_name | @tran_name_variable]] [;]For example:
BEGIN TRANSACTION; GO DELETE FROM HumanResources.JobCandidate WHERE JobCandidateID = 11; GO COMMIT TRANSACTION; GOCOMMIT WORK
The COMMIT WORK statement marks the transaction endpoint.
Syntax:
COMMIT [WORK] [;]COMMIT TRANSACTION and COMMIT WORK are identical, except that COMMIT TRANSACTION accepts a user-defined transaction name.
Create transaction with commit:
BEGIN TRANSACTION DeleteCandidate WITH MARK N'Deleting a Job Candidate'; GO DELETE FROM HumanResources.JobCandidate WHERE JobCandidateID = 11; GO COMMIT TRANSACTION DeleteCandidate;ROLLBACK TRANSACTION
Transactions can be aborted and reverted to the original point or savepoint in the transaction.
It is used to delete all modified data generated from the start of the transaction or to the savepoint. It also releases the resources held by the transaction.
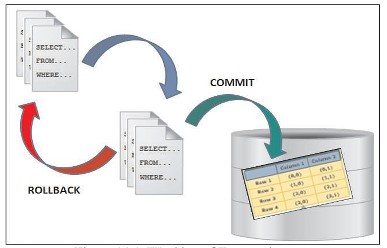
SAVE TRANSACTION
The SAVE TRANSACTION statement will set the savepoint inside the transaction.
Syntax:
SAVE {TRAN | TRANSACTION} {savepoint_name | @savepoint_variable} [;]For example:
CREATE PROCEDURE SaveTranExample @InputCandidateID INT AS DECLARE @TranCounter INT; SET @TranCounter = @@TRANCOUNT; IF @TranCounter > 0 SAVE TRANSACTION ProcedureSave; ELSE BEGIN TRANSACTION; DELETE HumanResources.JobCandidate WHERE JobCandidateID = @InputCandidateID; IF @TranCounter = 0 COMMIT TRANSACTION; IF @tranCounter = 1 ROLLBACK TRANSACTION ProcedureSave; GOIn the above code, the savepoint transaction is created inside the procedure. It will be used to roll back only if data changes are generated by the stored procedure if a valid transaction started before the procedure executes.
@@TRANCOUNT in transaction
@@TRANCOUNT is a system function that returns the numeric value of the transaction statement, occurring in the current connection.
For example:
PRINT @@TRANCOUNT BEGIN TRAN PRINT @@TRANCOUNT BEGIN TRAN PRINT @@TRANCOUNT COMMIT PRINT @@TRANCOUNT COMMIT PRINT @@TRANCOUNTResult:
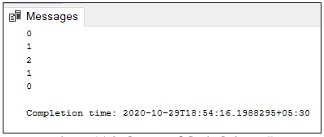
Example using @@TRANCOUNT with ROLLBACK
PRINT @@TRANCOUNT BEGIN TRAN PRINT @@TRANCOUNT BEGIN TRAN PRINT @@TRANCOUNT ROLLBACK PRINT @@TRANCOUNTResult:
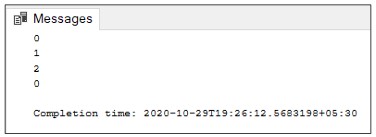
Mark transaction
Transaction marking is useful only when the user is willing to lose recently committed transactions or is checking out the related database.
Marking transactions on a schedule in every single related database creates a common chain of restore points in the database.
Concerns when using Marked Transaction:
A transaction mark will consume physical space, use them only for transactions that are important in the database recovery strategy.
When the marked transaction is committed, the row will be added to the logmarkhistory table on the msdb table.
If the marked transaction spans multiple databases on different servers, or on the same server, marks need to be recorded in the records of all affected databases.
Create Marked Transaction
To create a marked transaction, the user can use the BEGIN TRANSACTION statement syntax with the WITH MARK [DESCRIPTION] clause.
The transaction records the mark description, name, user, database , datetime information, and Log Sequence Number (LSN).
Steps to create a marked transaction in a set of databases:
- The name of the transaction in the BEGIN TRAN statement and using the WITH MARK clause.
- Perform an update on all databases in the set.
For example:
USE AdventureWorks2019; GO BEGIN TRANSACTION ListPriceUpdate WITH MARK 'UPDATE Product List prices'; GO UPDATE Production.Product SET ListPrice = ListPrice * 1.20 WHERE ProductNumber LIKE 'BK-%'; GO COMMIT TRANSACTION ListPriceUpdate; GODifference between Implicit and Explicit Transaction
| Implicit | Explicit |
| Transaction is maintained by SQL Server for each DDL and DML statement | Transaction defined by the compiler |
| DML and DDL statements execute under transaction implicit | Consists of a DML Statement, and executes as a query unit. |
| SQL server will rollback the entire statement | Do not include SELECT statements because they do not modify the data. |
Isolation Level (isolation level)
Transactions define an isolation layer that defines the degree to which a transaction must be isolated from data or resource modifications made by other transactions.
Isolation levels are defined under conditions that allow concurrent effects such as dirty reads.
The transaction isolation level controls the following:
- When the data is read, are there any locks in place and what type of locks are required?
- How long are read locks held?
- If a read operation that references a row is modified by another transaction, one of the following situations occurs:
- Block until the unique locking mechanism on the row is unlocked.
- Retrieve the committed version of the row that existed at the start of the transaction or statement.
- Read uncommitted data
Transactions require a unique key at all times on each data it governs. It then holds that lock until the transaction completes, regardless of the isolation level set for that transaction.
Isolation levels:
| Isolation Level | Dirty Read | NonRepeatable Read |
| Read committed | No | Yes |
| Read uncommitted | Yes | No |
| Snapshot | No | No |
| Repeatable Read | No | No |
| Serializable | No | No |
Range and types of locks
List of common lock types in SQL Ser
| Lock Mode | description |
| Update | Use in update preparation resources |
| Shared | Use to read operation without changing data like SELECT . statement |
| Intend | Used to establish a cascade lock |
| Exclusive | Used for data manipulation operations such as INSERT, UPDATE, DELETE. |
| BULK UPDATE | Used when copying large amounts of data into a table. |
| Schema | Used when the operation depends on the table schema |
Update Locks
These locks avoid deadlock situations. It serializes transactions, the transaction reads the data, acquires a shared lock on the row or page, and modifying the data requires converting the lock to an exclusive lock.
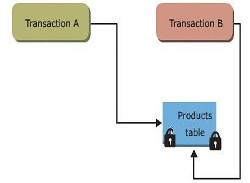
Shared Locks
These locks allow parallel transactions to read a resource under concurrency control.
Shared locks release resources once a read operation is complete, except that the isolation layer is assigned to a repeated read action or higher.
Exclusisve Locks
These locks prevent concurrent access to resources within the transaction.
By using exclusive lock, no transaction can change the data and read operation will be scheduled only through uncommitted isolation layer or NOLOCK mode.
DML statements like INSERT,UPDATE, DELETE are used to modify data.
Intent Locks
The role of the Intend lock:
- Prevents other transactions from changing data on higher-tier resources, in a way that would invalidate lower-level locks.
- to improve the Database engine’s efficiency in identifying key conflicts at a higher granularity.
List of intent lock descriptions:
| Lock Mode | description |
| Intent Shared (IS) | Shared lock protection is required on some lower-tiered resources. |
| Intent exclusive (IX) | Exclusisve lock protection is required in some lower tiered resources. IX is a superset (a set of sets consisting of another set) of IS, which protects the shared locks required at the lower resource layer. |
| Shared with Intent Exclusive (SIX) | Protection of shared locks is required across resources lower in the hierarchy and intent exclusive locks in some lower tier resources. Concurrent IS locks (concurrent IS locks) are enabled on top-level resources. |
| Intent Update (IU) | To protect the required locks in all lower layer resources. IU locks are only used on page resources. IU locks are converted to IX locks if an update operation is performed. |
| Shared intent update (SIU) | Provides a combination of S and IU locks, as a result of obtaining separate locks and holding both locks simultaneously. |
| Update intent exclusive (UIX) | Provides a combination of U and IX locks, as a result of obtaining separate locks and holding both locks simultaneously. |
Bulk Update locks
Bulk update locks are used when a large amount of data is copied to the table. These locks will allow multiple threads to run simultaneously to load bulk data sequentially on a table.
Schema Locks
Schema modification locks are used on the Database Engine while performing DDL operations such as deleting tables or columns.
Schema stability keys are used by the database engine while compiling and executing queries.
Key-Range Locks
This type of locks will protect the list of records represented in the RRset.
Key-range locks prevent phantom reads. new matches the searched condition for transaction A. If A executes the same condition again, it will get a set of data that is not uniform. )
Manage transactions
SQL Server implements transactions with different scopes that guarantee the ACID properties of these transactions.
In practice, that means using locks as the basis for traansactions to query shared database resources and prevent interference between transactions.
Transaction Log
The transaction log is an important component of the database, if the system crashes, the transaction log will ensure the recovery of the data to the proper state.
The transaction log should not be deleted or moved until the user understands its consequences.
Operations supported by the transaction log:
- Individual transactions recovery.
- Unfinished transaction rollback when SQL Server starts.
- Support for transaction replication
- Disaster recovery solution, supporting systems with high performance requirements.
- Restore files, databases, file groups, or forward pages to the point of failure.
Truncate transaction log
Truncation of the ransaction log will free up the memory occupied by the log file to continue logging. Logs will be automatically truncated upon encountering the following events:
- In a simple recovery model after (checkpoint) the checkpoint.
- A model of bulk recovery and full recovery, if checkpoing is encountered since the last backup.
When the logs are active for a long time, the transaction log will be delayed and may fill up the system memory. Log truncations can be slow for a variety of reasons, users can find out if anything is preventing truncation of the trnassaction log by querying the log_reuse_wait_desc and log_reuse_wait columns in the sys.databases catalog view.
Description of 2-column value:
| Log_reuse_wait | Log_reuse_wait_desc | Describe |
| 0 | NOTHING | Specifies that it represents more than one reusable virtual log file |
| first | CHECKPOINT | Determines that no checkpoints have appeared since the last log truncation, or that the log title has not moved outside the virtual log file |
| 2 | LOG_BACKUP | Specify the required log backup before performing log truncation. |
| 3 | ACTIVE_BACKUP_OR_RESTORE | Specifies that a backup or restore is in progress. |
| 4 | ACTIVE_TRANSACTION | Determines the active transaction. |
| 5 | DATABASE_MIRRORING | Determines that database mirroring is paused or in high-perfromance mode, mirror database is behind the main database |