












Giới thiệu
hocvietcode.com là website chia sẻ và cập nhật tin tức công nghệ, chia sẻ kiến thức, kỹ năng. Chúng tôi rất cảm ơn và mong muốn nhận được nhiều phản hồi để có thể phục vụ quý bạn đọc tốt hơn !
Liên hệ quảng cáo: trienkhaiweb@gmail.com
Di recente, ho fatto un piccolo piccolo progetto usando LSTM, ma leggere documenti vietnamiti per capire a fondo il parlare non è molto chiaro, c'è questo articolo https://dominhhai.github.io/vi/2017/10 /what-is-lstm / è tradotto da un sito straniero, che ritengo abbastanza buono. Poi, attraverso il progetto che ho realizzato, vorrei essere qui per condividere alcune cose per tutti e per me stesso in futuro quando non lo uso da molto tempo e poi rileggerlo per pensare.
Mục lục
Prima di spiegare le LSTM, penso che dovrei sapere qualcosa sulle radici delle RNN (Recurrent Neural Networks) illustrate di seguito:
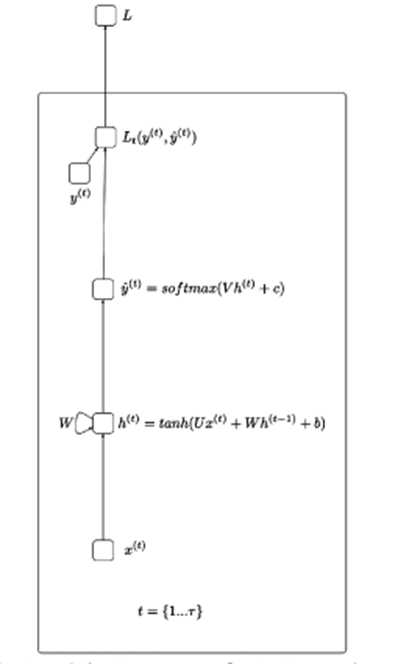
In poche parole, RNN aiuta a elaborare i dati sotto forma di una sequenza sequenziale, come l'elaborazione di discorsi, azioni,… L'idea della figura sopra è che l'input x attraverserà i livelli nascosti e restituirà il valore di output (può essere 1 array) Dall'output che passa attraverso la funzione di perdita sarà y_hat.
X(t): valore di input al passo temporale t
H(t): stato nascosto al passo temporale t
O(t): valore di uscita al passo temporale t
Y_hat: vettore di probabilità normalizzato tramite la funzione softmax al passo temporale t
U, V, W: Le matrici di peso nell'RNN corrispondono alle connessioni nella direzione dall'inizio allo stato nascosto, dallo stato nascosto all'uscita e dallo stato nascosto allo stato nascosto.
B, c: Deviazione (bias)
LSTM aiuta a superare il gradiente di fuga di RNN. Poiché utilizziamo i gradienti per addestrare i neuroni e l'RNN è influenzato dalla memoria a breve termine quando i dati di input sono lunghi, l'RNN potrebbe dimenticare le informazioni importanti trasmesse fin dall'inizio.
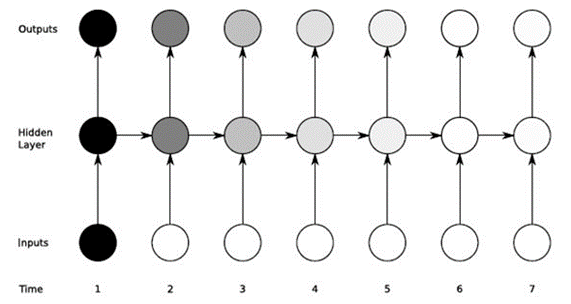
Ad esempio, quando si guarda una serie di film, il nostro cervello salverà le informazioni sul contenuto delle parti precedenti e le combinerà con l'episodio che stiamo guardando per creare una storia.
LSTM aiuta a ridurre i punti dati non necessari avendo i gate installati internamente e avendo uno stato di cella in esecuzione.

Ci sono molti articoli e immagini che spiegano il funzionamento di ogni cancello e le funzioni attive. Quindi qui provo a usare la matematica per spiegare questo ragazzo. Per riassumere rapidamente, LSTM utilizza 1 stato di cella e 3 porte per elaborare i dati di input. La ricetta che ho messo nella foto qui sotto:


Questa è l'operazione dell'LSTM in una fase temporale, il che significa che queste formule verranno ricalcolate in un'altra fase temporale. E i pesi (Wf, Wi, Wo, Wc, Uf, Ui, Uo, Uc) e bias (bf, bi, bo, bc) non cambiano.
Ad esempio, per distribuire LSTM su 10 fasi temporali, puoi eseguire le seguenti operazioni:
sequenza_len = 10
per i nell'intervallo (0,sequence_len):
# se siamo nel passaggio iniziale
# inizializza h(t-1) e c(t-1)
# a caso
se i==0:
ht_1 = casuale()
ct_1 = casuale()
altro:
ht_1 = h_t
ct_1 = c_t
f_t = sigmoide (
matrice_mul(Wf, xt) +
matrice_mul(Uf, ht_1) +
bf
)
i_t = sigmoide (
matrice_mul(Wi, xt) +
matrice_mul(Ui, ht_1) +
bi
)
o_t = sigmoide (
matrice_mul(Wo, xt) +
matrice_mul(Uo, ht_1) +
bo
)
cp_t = tan (
matrice_mul(Wc, xt) +
matrice_mul(Uc, ht_1) +
avanti Cristo
)
c_t = elemento_saggio_mul(f_t, ct_1) +
element_wise_mul(i_t, cp_t)
h_t = element_wise_mul(o_t, tanh(c_t))
Un problema indispensabile nella matematica lineare è la dimensionalità dei dati (questa potrebbe essere la parte che dovrò rileggere in futuro perché è spesso nell'elenco delle domande del colloquio).
Con le formule dell'LSTM in un timestep come segue:
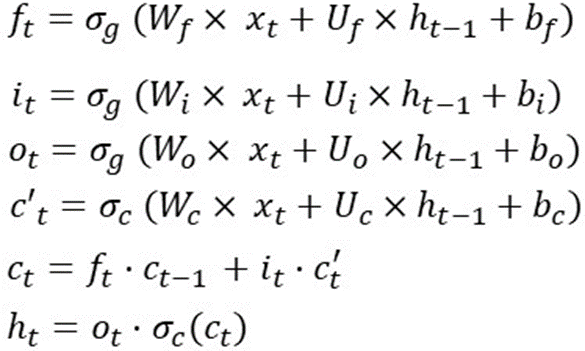
Diciamo che dim(o(t)) è [12×1] => dim(h(t)) e dim(c(t)) è [12×1] perché h(t) è una moltiplicazione elemento per elemento tra o( t) e tanh(c(t)).
E x(t) ha dimensioni di [80×1] => W(f) è [12×80] perché f(t) = [12×1] e x(t)=[80×1]
Bf, bi, bc, bo hanno dimensioni di [12×1]
E Uf, Ui, Uc, Uo hanno dimensioni di [12×12]
Quindi il peso totale dell'LSTM è: 4*[12×80] + 4*[12×12] + 4*[12×1] = 4464.
Osservando il calcolo sopra, si può vedere che gli LSTM sono interessati a due cose: la dimensione dell'input e la dimensionalità dell'output (alcuni blog potrebbero chiamarlo numero di unità LSTM o dimensione nascosta,…).
Riassumendo la dimensione della matrice di peso di LSTM è 4*Output_Dim*(Output_Dim + Input_Dim + 1)
C'è una nota sul parametro che molte persone confondono:

In Keras c'è un parametro che è return_sequence (restituisce true, false) quando return_squence=False (predefinito) è molti a uno e altrimenti True sarà da molti a molti.
Esempio con dati di input X di dimensione [5×126]
I modelli sono i seguenti:
modello = sequenziale()
model.add(LSTM(64, return_sequences=True, activation='relu', input_shape=(5,126)))
model.add(LSTM(128, return_sequences=True, activation='relu'))
model.add(LSTM(64, return_sequences=False, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(actions.shape[0], activation='softmax'))
Può essere visto attraverso il primo livello LSTM con un numero nascosto di 64 => Il numero di parametri dopo aver superato questo livello è:
4*((126+64)*64+64) = 48896 (lo stesso per i seguenti 2 livelli LSTM e il suo output sarà l'input del livello successivo).
Per i livelli densi (è un livello in keras con output_dim che è la dimensione di output di quel livello) quindi il numero di nuovi parametri è uguale a output_dim * output_dim (del livello precedente detto)+1
Esempio con il primo strato denso: il numero di parametri è: 64*(64+1)=4160

Per riassumere in questo articolo, ho cercato di spiegare il funzionamento di LSTM dal punto di vista del calcolo dei parametri, questo è un passaggio piuttosto importante per aiutarti a progettare e accelerare il modello di apprendimento automatico.
hocvietcode.com là website chia sẻ và cập nhật tin tức công nghệ, chia sẻ kiến thức, kỹ năng. Chúng tôi rất cảm ơn và mong muốn nhận được nhiều phản hồi để có thể phục vụ quý bạn đọc tốt hơn !
Liên hệ quảng cáo: trienkhaiweb@gmail.com