


Giới thiệu
hocvietcode.com là website chia sẻ và cập nhật tin tức công nghệ, chia sẻ kiến thức, kỹ năng. Chúng tôi rất cảm ơn và mong muốn nhận được nhiều phản hồi để có thể phục vụ quý bạn đọc tốt hơn !
Liên hệ quảng cáo: trienkhaiweb@gmail.com

Concetto di tabella, istruzioni per creare tabelle, modificare tabelle, eliminare tabelle e gestire tabelle in Microsoft SQL Server

Introduzione al concetto di sistema di gestione di database correlato (Sistema di gestione di database correlato / RDBMS)[| ]
Solitamente, in pratica, siti web, progetti software, organizzazioni - agenzie che operano conservano una grande quantità di dati, che è il risultato della raccolta quotidiana di dati (ad es. utenti/utenti dati, dati residenti governativi, dati studenti scolastici... questi dati utilizzati per essere archiviato fondamentalmente attraverso la carta, al giorno d'oggi, le persone li digitalizzano.Per una conservazione più semplice, le soluzioni di archiviazione più semplici sono di salvare in file (file) dal punto di vista dell'utente, precedentemente file di testo .txt, quindi file word, excel ( .doc, .xls) Come per i programmatori, li archiviamo in file (revisione lettura e scrittura di file di testo e lettura e scrittura di file binari in C). Nella programmazione moderna, quando la quantità di dati è sempre più grande e diventa più difficile da gestire , le persone hanno introdotto il concetto di database (database) per rappresentare un'organizzazione di dati che può contenere uno o più elementi di dati, chiamati record. u è un set di dati che può soddisfare i dati in base a diverse domande. Per esempio:
I dati sono informazioni ed è la componente più importante in qualsiasi tipo di lavoro, meccanismo organizzativo... Nelle attività quotidiane, utilizziamo i dati disponibili. creiamo o aggiorniamo, aggiungiamo nuovi dati generati, i dati vengono raccolti e analizzati e presentate le informazioni a l'utente. Possono essere informazioni su persone, veicoli, prodotti, sport, condizioni meteorologiche, ..... in breve, i dati sono informazioni e sulla base di queste informazioni raccogliamo in un blocco di dati che servono determinati compiti.
Veniamo a un esempio: il governo dispone di un set di dati per archiviare l'intera popolazione dei dati, in base ai dati raccolti, il governo può identificare:
O un esempio: un'azienda che produce componenti per computer prevede di produrre solo un componente che era stato precedentemente importato. Se l'azienda dispone di vecchi dati sui prezzi all'importazione dei componenti negli ultimi 5 anni, le cose saranno più semplici, l'azienda sarà in grado di calcolare il costo totale delle parti importate in base al prezzo all'importazione, alla quantità di importazione, i componenti vengono importati ogni anno e da quei dati, è possibile considerare se il costo dell'investimento in fabbrica, della manodopera e della produzione dei prodotti finiti sia molto diverso da quello delle importazioni...
Sulla base di questo insieme di dati, il governo può utilizzarlo completamente per giudicare, nonché per elaborare politiche ragionevoli in futuro basate sull'orientamento allo sviluppo.
Nelle organizzazioni, nelle aziende... è lo stesso, avere le informazioni consente di prevedere in base ai dati storici e pianificare di conseguenza, e se l'aggregazione è facile, le prestazioni Smart aiuteranno le aziende e le organizzazioni a risparmiare molte risorse e denaro.
Un database è una raccolta di elenchi di dati o può essere inteso come un meccanismo di organizzazione dei dati compatibile per la memorizzazione dei dati. Queste informazioni sono accessibili in modo efficiente e rapido da parte dell'utente.
Per esempio:
La rubrica è un database, in questo database, le informazioni di contatto di ogni persona sono chiamate record, questo record includerà:
Per riassumere, un database è un elenco organizzato di dati, il cui contenuto può essere facilmente accessibile, gestito o aggiornato.
La governance dei dati ha senso quando dobbiamo gestire grandi quantità di informazioni, inclusa l'organizzazione dell'archiviazione delle informazioni e fornire meccanismi per manipolare e lavorare con informazioni o dati. Inoltre, il sistema deve anche garantire la sicurezza delle informazioni archiviate in vari casi, come meccanismi per limitare i diritti degli utenti che possono accedervi, dati che devono essere mantenuti riservati o meccanismi per limitare l'accesso. .
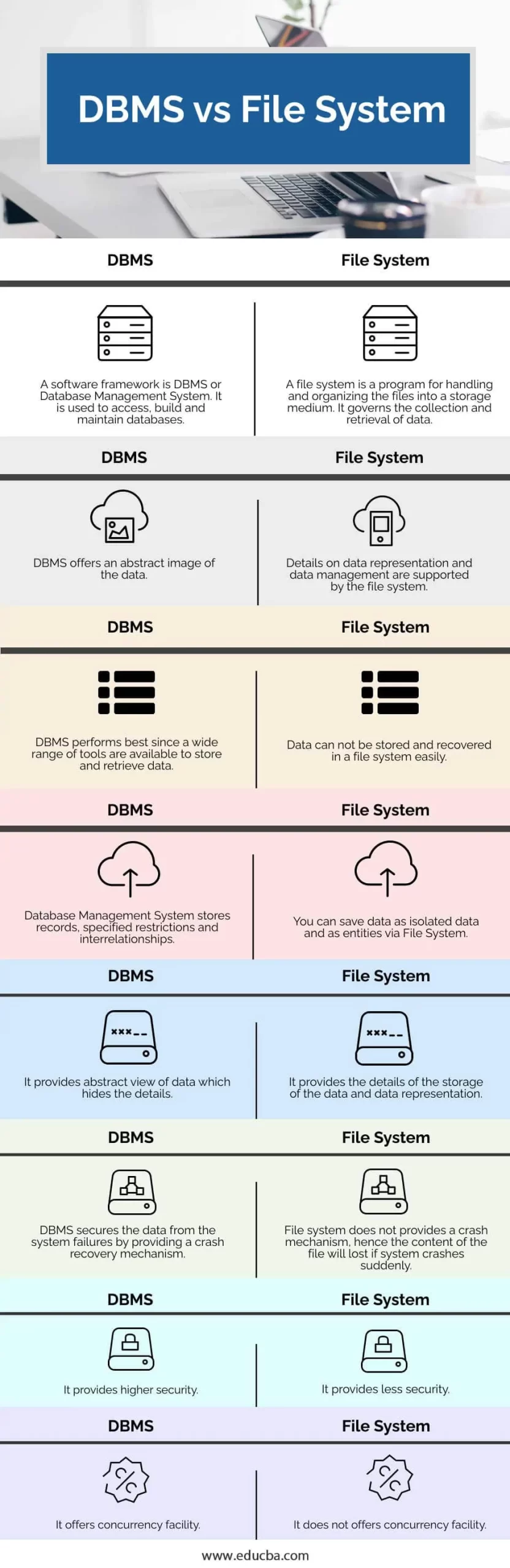
La dimensione dei dati durante l'archiviazione è sempre una grande preoccupazione, in passato le persone utilizzavano il file system (file) per archiviare i dati (puoi vedere di nuovo l'articolo lavorare con FILE in linguaggio C.). In questo sistema, i dati vengono archiviati in diversi file discreti e la raccolta di questi file viene archiviata nel computer. Possono essere interrogati e interagire con i dati del sistema operativo. I file utilizzati per archiviare i dati sono generalmente chiamati tabelle , le righe su questa tabella sono chiamate record e le colonne sono chiamate campi.
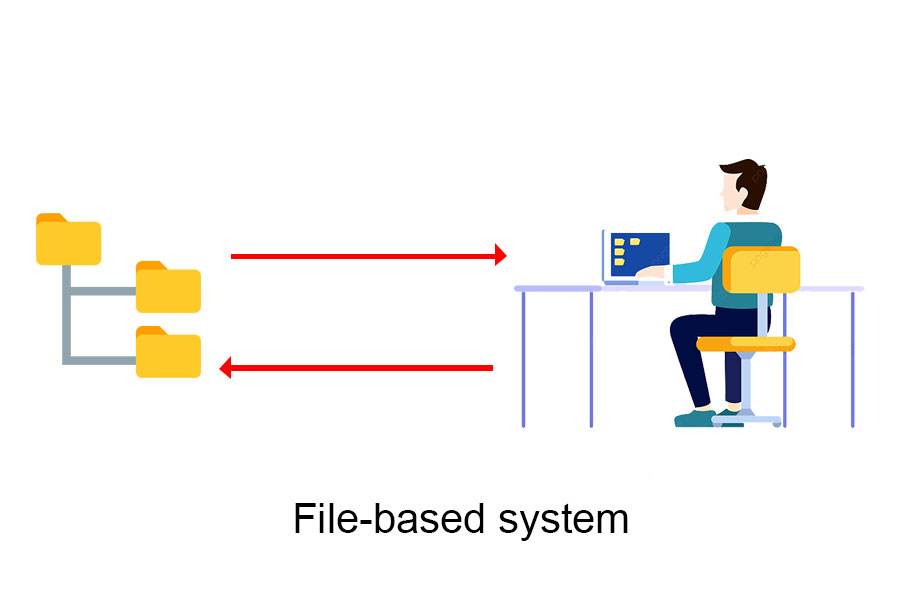
Prima dell'esistenza dei sistemi di gestione dei database, le persone utilizzavano i file per archiviare i dati nelle applicazioni software.
In un sistema basato su file, diversi programmi e funzionalità di un'applicazione interagiscono con file diversi per soddisfare il business, non dispone di un sistema di standardizzazione dei dati o mostra come organizzare la struttura dei dati, la struttura di questi file discreti.
Quando i file vengono suddivisi per memorizzare dati separati, i dati discreti sono facilmente ridondanti e incoerenti. Si consideri ad esempio: una funzionalità che aggiunge/modifica/elimina/ordina gli studenti interagisce con il file memorizzando l'elenco degli studenti, una funzionalità che aggiunge/modifica/elimina/ordina le classi funziona con il file di archivio.class ... , mentre uno studente è un oggetto appartenente alla classe, ad esempio lo studente Nguyen Van A è nella classe 1B -> il problema sorgerà da qui. Dovremo aggiungere un campo nel file di dati dello studente per memorizzare la classe che lo studente ha studiato, in base ai dati disponibili della classe. Alcune situazioni di codice errato, dati non standard (come input errati degli studenti) porteranno anche a situazioni irragionevoli (la classe non è nel database o è stata eliminata, ma lo studente ce l'ha ancora). Il campo rappresenta quella classe. ..
In un sistema basato su file, l'elaborazione di query improvvise o ad hoc può essere molto difficile, soprattutto quando si verificano modifiche al programma. Ad esempio, un banchiere deve creare un elenco di tutti i clienti con un saldo del conto di $ 2000 o più. I banchieri hanno opzioni: ottenere un elenco di tutti i clienti ed estrarre manualmente le informazioni necessarie, oppure assumere un programmatore di sistema per progettare il programma applicativo richiesto. Entrambe le alternative sono insoddisfacenti. Supponiamo che un programma del genere sia stato scritto e, pochi giorni dopo, il dipendente debba tagliare quell'elenco per includere solo i clienti che hanno aperto i loro conti un anno fa. Poiché un tale generatore di elenchi non esiste, è difficile accedere ai dati.
I dati sono sparsi in molti file diversi e il file potrebbe essere in un formato diverso. Sebbene i dati vengano utilizzati da diversi programmi nell'applicazione, ci sono alcune situazioni in cui i dati possono essere correlati, vengono archiviati come file di dati sparsi e non correlati.
In un sistema multiutente, molti utenti possono accedere a file o record contemporaneamente, il che rende più difficile la gestione del sistema basato su file.
Nelle aziende o nelle organizzazioni, anche la sicurezza dei dati è un grosso problema, i dati dovrebbero essere protetti e accessibili solo se autorizzati, i sistemi basati su file non funzionano bene.
In qualsiasi applicazione sono richieste determinate regole di integrità dei dati, che dovrebbero essere mantenute. Possono avere determinate condizioni o vincoli sugli elementi o sui record dei dati. Con un sistema basato su file, questo non può essere fatto sul livello dati perché per natura, i dati sono archiviati solo nei file, queste cose possono essere fatte solo sul livello codice e sono molto complicate da mantenere o modificare. i dati dell'applicazione aumentano.
Il sistema di database è stato sviluppato negli anni '60 per risolvere i problemi di sviluppo di applicazioni quando si ha a che fare con i big data ed è più ad alta intensità di dati. E anche per risolvere i problemi derivanti dagli svantaggi dei sistemi basati su file.
Il database viene utilizzato per archiviare i dati in modo efficiente e organizzato. Un database consente la gestione dei dati in modo semplice e veloce. Ad esempio, un'azienda deve conservare i dati sulle informazioni sul personale in un database, in qualsiasi momento i dati dovrebbero essere facilmente consultati, aggiunti o cercati...
Se solo in termini di archiviazione, anche utilizzando semplici file manuali i dati possono essere soddisfatti, ad esempio, l'università deve mantenere le informazioni su docenti, studenti, materie, queste informazioni possono essere mantenute e archiviate in file separati, tuttavia, nel tempo i dati i file diventeranno spazzatura, consumando molto spazio di archiviazione, gestire più modifiche ed eliminazioni è molto difficile, quindi non è adatto per l'archiviazione a lungo termine per molti anni.
Invece, se si utilizzano quei dati archiviati in un sistema di database, i dati possono essere archiviati per molto tempo, più facili da interrogare e aggiornare.
I dati o le informazioni vengono archiviati a lungo termine secondo standard e digitalizzati utilizzando un sistema di database. Il sistema di database presenta molti vantaggi perché fornisce una soluzione di archiviazione dati centralizzata.
All'interno di un'organizzazione o di un'agenzia, i dati dei dipartimenti hanno spesso la stessa struttura. La combinazione di un database centralizzato consente a più reparti di accedere ai dati corrispondenti agli stessi standard, riducendo al minimo la duplicazione o la ridondanza dei dati.
Quando i dati vengono duplicati in diversi reparti utilizzando un sistema basato su file, qualsiasi modifica ai dati influirà sui dati correlati, portando talvolta a incongruenze nei dati. data perché l'aggiornamento dei dati verrà eseguito a livello di codice, quando i dati e il il codice sorgente diventa complesso, quindi si verificheranno problemi. In un sistema di database centralizzato o nel database di cui stiamo parlando, è completamente possibile aggiornare i dati regolarmente, in questo caso è possibile aggiornare un solo record e ridurre il problema delle incongruenze dei dati.
Il database può trovarsi in un server e dispone di un meccanismo per condividere con utenti diversi quando concesso, in questo modo gli utenti possono accedere e aggiornare i dati in qualsiasi momento.
La governance centralizzata garantisce che gli standard dei dati così come sono rappresentati possano essere stabiliti e rispettati. Ad esempio, è comune rappresentare il nome completo di un utente per includere Mr. Toan Ngo Vinh (Nome completo), quindi sarà diviso in 3 componenti:
L'uso del database garantirà questo formato durante la memorizzazione secondo l'intenzione del progettista del database.
L'integrità dei dati influisce sull'accuratezza del database. Ad esempio, un dipendente si dimette da un'organizzazione, quindi il database del personale dovrà essere aggiornato, le informazioni del dipendente che si è appena licenziato e i relativi dati dovrebbero essere eliminati dal database o archiviati in un'altra posizione per salvare la cronologia del personale, i dati sul lavoro relativo a questo dipendente devono essere trasferiti a un altro dipendente affinché il lavoro possa continuare.
Un database ospitato centralmente aiuta a evitare questi errori. Con il meccanismo del database, i dati verranno definitivamente cancellati dalla tabella e anche i collegamenti con questo record verranno cancellati o aggiornati secondo l'intenzione del progettista.
In un sistema di database centralizzato, i privilegi per aggiornare i dati devono essere autorizzati. Il meccanismo corretto è che solo una persona avrà il controllo completo sull'intero database. Questa persona è chiamata amministratore del database (DBA). Il DBA può implementare un meccanismo di sicurezza ponendo restrizioni sui dati. In base all'autorizzazione del DBA, agli utenti autorizzati possono essere assegnate le autorizzazioni per aggiungere, modificare, eliminare ed eseguire query sui dati.
Il DBMS può definire un elenco di record correlati e un insieme di programmi che possono eseguire query e lavorare con questi record. DBMS consente agli utenti di accedere, archiviare e gestire i dati. Il problema principale con i precedenti DBMS era che i dati venivano scritti in filem, quindi le informazioni sui diversi oggetti venivano mantenute in diversi file fisici. Pertanto, l'associazione tra oggetti rimane in file separati, portando così a una situazione in cui sono presenti troppi file e molte funzioni per integrarli in un unico sistema.
La soluzione a questi problemi è normalizzare i dati in un sistema di database centralizzato. Il database è archiviato in un unico luogo, gli utenti possono accedere ai dati memorizzati sul server attraverso i propri dispositivi.
In poche parole, un database è una raccolta di elenchi di dati correlati e un DBMS è un sistema costituito da un insieme di programmi utilizzati per aggiungere, modificare ed eliminare questi dati. Comprensibilmente, un DBMS è un software che include un insieme di funzionalità che aiutano a definire un database, creare e interagire con i dati e lavorare con i dati.
DBMS fornisce un ambiente comodo ed efficiente per lavorare con set di dati di grandi dimensioni e operazioni di aggiornamento interattive. DBMS può ospitare da un piccolo sistema in esecuzione su un personal computer a un grande sistema informatico.
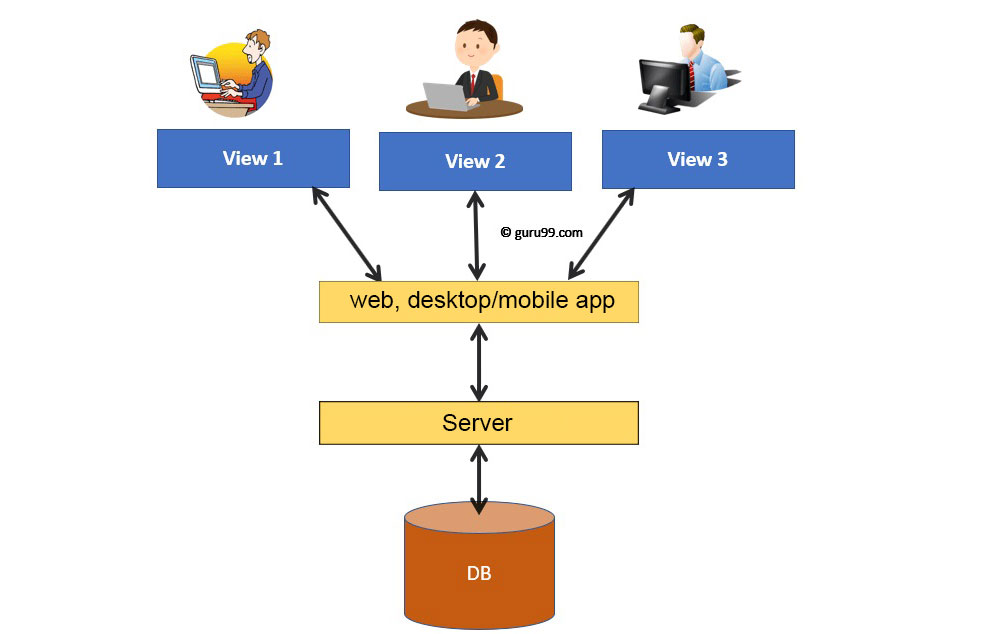
Ecco alcuni esempi di cosa possono fare in pratica le applicazioni DBMS:
Da un punto di vista tecnico, i prodotti DBMS presentano molte differenze. DBMS supporta diversi linguaggi di query, ma in generale hanno ancora alcuni punti in comune per aiutare i programmatori ad accedere facilmente e convertire DBMS come desiderato, le persone chiamano questo linguaggio: Structured Query Language (SQL)
Il linguaggio per la gestione dei sistemi di database è chiamato Fourth Generation Language (4GL). Le informazioni dal database possono essere presentate in una varietà di formati. La maggior parte dei DBMS include un programma di scrittura di report che consente agli utenti di esportare i dati in un formato di report. Molti DBMS includono anche informazioni grafiche sotto forma di grafici e diagrammi.
Non è necessario utilizzare un DBMS generico per distribuire un database. Gli utenti possono scrivere il proprio set di programmi per creare e mantenere database, creando così database e DBMS che possono essere utilizzati per interrogare, interagire con i dati, ecc.. a seconda dello scopo del programmatore. Database e software insieme sono chiamati sistema di database.
Gli utenti finali accedono al sistema del database attraverso l'interfaccia grafica di applicazioni che interrogano direttamente il database. Un DBMS consente agli utenti di eseguire query e recuperare dati dal database tramite il codice sorgente dietro il software e i programmi che restituiscono i risultati all'utente finale.
Il DBMS è responsabile dell'elaborazione dei dati e della loro conversione in informazioni. A tale scopo, il database deve essere manipolato, inclusa l'esecuzione di query sul database per recuperare dati specifici, l'aggiornamento del database e la generazione di report.
I report includono informazioni, ovvero dati elaborati. Il DBMS è anche responsabile di garantire la sicurezza e l'integrità dei dati.
Alcuni dei vantaggi dell'utilizzo di un DBMS:
Solitamente la maggior parte dei programmi deve essere progettata per poter archiviare i dati, questo problema viene gestito dal DBMS, che viene eseguito creando strutture dati complesse e questo processo è chiamato gestione dei dati.
Il DBMS fornisce funzionalità per definire la struttura dei dati nell'applicazione. Questi includono la definizione e la modifica della struttura dei record, i tipi di dati e le dimensioni dei campi e i vincoli e le condizioni che ciascun campo deve soddisfare.
Una volta definita la struttura dei dati, i dati devono poter essere aggiunti, aggiornati ed eliminati. Queste funzionalità fanno parte del DBMS. Queste funzioni possono gestire richieste di manipolazione dei dati pianificate e non pianificate. Le query pianificate sono quelle della funzionalità dell'applicazione dell'applicazione. Le query non pianificate sono query ad hoc, eseguite come e quando richiesto.
La sicurezza dei dati è una delle funzionalità più importanti quando il database viene utilizzato in un ambiente multiutente. Sono richiesti controlli di accesso ai dati dell'utente. Il database determina le regole, quali utenti possono accedere al database, a quali elementi di dati può accedere l'utente o le operazioni con i dati che l'utente può eseguire.
I dati nel database dovrebbero contenere il minor numero di errori possibile. Ad esempio, l'ID studente dovrebbe essere sempre valido, non vuoto. I numeri di telefono devono contenere solo numeri... questi possono essere verificati tramite il DBMS.
Il recupero dei dati in caso di guasto del sistema e l'accesso simultaneo ai record da parte di più utenti possono essere facilmente gestiti dal DBMS
L'ottimizzazione delle prestazioni delle query è una delle caratteristiche importanti di un DBMS. Pertanto, DBMS ha una serie di programmi per aiutare a standardizzare, ottimizzare le prestazioni, in breve, DBMS indovinerà diverse implementazioni di query e sceglierà la soluzione più ottimale da utilizzare.
In un dato momento, più utenti possono accedere agli stessi dati di trene DB, il DBMS sarà responsabile della condivisione dei dati tra utenti diversi, contribuendo a mantenere l'integrità dei dati.
Il linguaggio di query DBMS implementa la soluzione di accesso ai dati. SQL è il linguaggio di query più comunemente utilizzato. Un linguaggio di query è un linguaggio non procedurale , il che significa che l'utente interroga ciò che desidera e non deve specificare come farlo.
Esempio: prendi una lista dei 10 studenti con i punteggi più alti nel database degli studenti, con SQL, per non parlare della prospettiva della sintassi, il significato dell'affermazione sarebbe semplicemente quello di farmi ordinare i 10 studenti con i punteggi più alti dall'alto a basso, ma per i linguaggi procedurali, per farlo dobbiamo farlo in sequenza: estrarre l'array studente, ordinare per ciclo dall'alto verso il basso, quindi estrarre i primi 10 elementi.
I database possono essere differenziati in base a funzioni e modelli di dati. Il modello di dati descrive un contenitore per la memorizzazione dei dati e il processo per la memorizzazione e il recupero dei dati da tale contenitore. L'analisi e la progettazione di modelli di dati è alla base dello sviluppo delle banche dati.
In questo modello, il database contiene solo una tabella o un file. Questo modello viene utilizzato per database semplici. Ad esempio, desideri memorizzare numero di rotolo, nome, materia e voto di un gruppo di studenti. Questo modello non può gestire dati complessi. Questo modello può essere la causa della ridondanza dei dati, quando i dati vengono ripetuti più di una volta.

In un modello di dati gerarchico, record diversi sono correlati tramite una struttura gerarchica o ad albero. In questo modello, la relazione avviene attraverso termini o strutture genitore-figlio. Ma la struttura figlio ha un solo genitore. Per cercare i dati in questo modello, è fondamentale che gli utenti comprendano la struttura gerarchica dei dati.
Il registro di Windows è un esempio di database a livelli, utilizzato per memorizzare la configurazione e le preferenze del sistema operativo Windows.
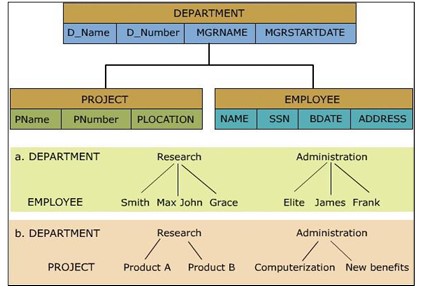
Questo modello è estremamente efficace quando il database contiene una grande quantità di dati.
Questo modello è simile al modello stratificato. Il modello stratificato è essenzialmente un sottoinsieme del modello di rete. Tuttavia, invece di utilizzare alberi gerarchici genitore-figlio, il modello di rete utilizza la teoria degli insiemi per fornire un modello gerarchico con l'eccezione che la tabella figlio consentirà più di un genitore.
Nel modello di rete, i dati vengono archiviati in aggregazioni, anziché in un formato a strati. Questo risolve il problema della ridondanza. Quindi i record vengono caricati sul collegamento fisico tramite elenchi collegati.
Alcune aziende sviluppano modelli di dati di rete:
https://en.wikipedia.org/wiki/IDMS
Il modello di rete e il modello di dati gerarchico erano i principali modelli di dati per l'implementazione di molti DBMS commerciali. I costrutti del modello di rete e i costrutti del linguaggio sono stati definiti dal Comitato della Conferenza/ Comitato sui linguaggi dei sistemi di dati (CODASYL) sui linguaggi dei sistemi di dati.
Per ogni database vengono archiviati la definizione del nome del database, il tipo di record per ciascun record ei componenti che costituiscono questi record, chiamati schema di rete. La parte del database che viene vista dal programma applicativo è in realtà costituita dalle informazioni desiderate dal contenitore di dati nel database chiamato sottoschema. Consente ai programmi applicativi di accedere ai dati richiesti dal database.
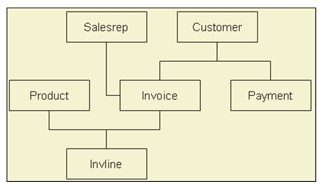
In questo modello possiamo accedere facilmente ai dati e l'applicazione può anche accedere ai record del proprietario e ai record dei membri in un set. Il modello di rete non consente ai membri di esistere senza un proprietario, il che garantisce l'integrità dei dati.
Il design o la struttura di questo modello non è facile da usare . Questo modello non ha alcun ambito di ottimizzazione automatica delle query, le prestazioni delle query dipendono fortemente dall'abilità, dall'esperienza e dall'algoritmo del programmatore. Questo modello non raggiunge l'indipendenza strutturale sebbene il modello di database di rete sia in grado di raggiungere l'indipendenza dei dati.
A causa della crescente necessità di lavorare con le informazioni e della crescente complessità dello sviluppo di applicazioni che funzionano con i database, la progettazione, la gestione e l'interazione con i dati diventa sempre più ingombrante. La mancanza di funzionalità di query ha richiesto molto tempo ai programmatori per generare anche i report più semplici, il che ha portato allo sviluppo del concetto noto come database del modello relazionale.
Il termine "relazione" deriva dalla teoria matematica degli insiemi. In questo modello, a differenza dei modelli gerarchici e di rete, non esiste alcuna connessione fisica (il modello ad albero genitore-figlio è inteso come associazione). Tutti i dati vengono archiviati in un modello di tabella composto da righe e colonne. I dati nelle due tabelle sono collegati tra loro tramite colonne comuni anziché collegamenti fisici (genitore e figlio). Il programmatore utilizza la sintassi o l'interfaccia software fornita per lavorare con le righe o i record nella tabella.
Famosi database relazionali includono: Oracle (Mysql) , Sybase, DB2, Posgres, Microsoft SQL Server ...
Questo modello rappresenta il database come una raccolta di relazioni. In questo termine del modello, le righe possono anche essere chiamate tuple (non tradotte, vedi wiki: https://en.wikipedia.org/wiki/tuple , le colonne sono attributi), le tabelle sono chiamate relazioni (relazione) L'elenco dei valori applicati ai campi si chiama dominio, il numero di attributi della relazione si chiama grado della relazione Il numero di tuple (valori) di campi) determina la natura della relazione.
Questa è la teoria, fratelli, ricordate questo per una facile comprensione:
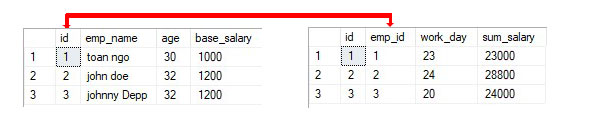
Ad esempio, 2 tabelle da utilizzare per rappresentare un semplice calcolo delle risorse umane:
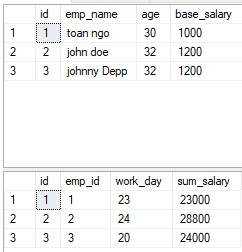
Il modello di database relazionale offre ai programmatori il tempo di concentrarsi sulla vista logica del database piuttosto che preoccuparsi della vista fisica. Uno dei motivi della flessibilità. La maggior parte dei database relazionali utilizza il linguaggio di query strutturato (SQL). L'RDBMS utilizza SQL per tradurre la query dell'utente nel codice tecnico necessario per recuperare i dati richiesti. Il modello relazionale è così facile da gestire che anche i meno esperti possono generare facilmente query e report pratici, senza i numerosi requisiti richiesti per progettare un database adeguato.
Il modello relazionale è un tentativo di semplificare la struttura del database. Risponde a tutti i dati nel database come semplici tabelle di valori di dati a colori di riga. Un RDBMS è un programma software che crea, mantiene e manipola database relazionali. Un database relazionale è un database suddiviso in unità logiche denominate tabelle, in cui le tabelle sono correlate tra loro nel database.
La tabella è correlata in un database relazionale, consentendo di recuperare i dati completi in un'unica query (sostituire i dati desiderati che possono esistere in più tabelle). Avendo chiavi o campi comuni, tra tabelle di database relazionali, i dati di più tabelle possono essere combinati da un set di risultati di grandi dimensioni
Quindi, un database relazionale è un database strutturato sul modello relazionale, la caratteristica fondamentale di un modello relazionale è che in un modello reale i dati vengono memorizzati nelle relazioni.
| Regole | Significativo |
| Relazione | asse |
| Tupla | riga o record nella tabella |
| Attributo | Campo o colonna in una tabella |
| Cardinalità di una relazione | Numero di record nella tabella |
| Grado di relazioni | Numero di attributi della tabella |
| Dominio di un attributo | insieme di tutti i possibili valori utilizzati dall'attributo |
| Chiave primaria di una relazione | Un attributo o una combinazione di attributi che identifica in modo univoco ogni tupla in una relazione (tabella) |
| Chiave esterna (chiave straniera) | Un attributo o una combinazione di attributi che definisce la relazione tra le tabelle |
L'obiettivo principale di un sistema di database è fornire un ambiente per il recupero delle informazioni dal database e la memorizzazione di nuove informazioni nel database.
Per un piccolo database personale, una persona di solito definisce le strutture e le operazioni con il database
Tuttavia, RDBMS fornisce funzionalità che aiutano più utenti a partecipare alla progettazione, all'uso e alla manutenzione di un database di grandi dimensioni.
Essere in grado di visualizzarli come oggetti della vita reale come persone, luoghi, cose, oggetti o semplicemente un'idea, sarà chiaramente identificato. Ad esempio, le entità in una scuola possono essere studenti, insegnanti, personale di formazione, soggetti...
Ogni entità ha caratteristiche uniche chiamate attributi. Ad esempio, l'entità studente può includere attributi come ID studente, nome, punteggio e così via. Ciascun attributo ha un nome appropriato da descrivere.
Un gruppo di entità correlate è chiamato insieme di entità. Ogni entità ha un nome univoco, il nome dell'entità rifletterà il contenuto, i dati che memorizza. Quindi le proprietà di tutti gli studenti della scuola sono archiviate nell'oggetto chiamato studente
L'accesso e la manipolazione dei dati è facilitato dalla creazione di relazioni di dati basate su una struttura chiamata tabella. La tabella contiene gruppi di entità correlate, ovvero l'insieme di entità. Le persone usano le tabelle come nomi per sostituire le entità. Le tabelle sono relazioni, le righe sono tuple, le colonne sono attributi.
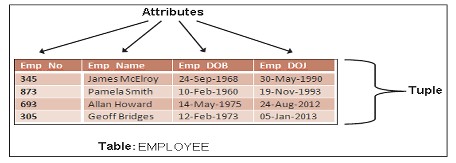
Le caratteristiche della tabella sono soggette ai seguenti criteri:
| DBMS | RDBMS |
| Non sono richiesti dati in una struttura tabulare, né sono richieste relazioni tabulari tra elementi di dati. | In un RDBMS, la struttura delle tabelle è un must e le relazioni tra tabelle consentono agli utenti di applicare e gestire le regole aziendali e di ridurre il lavoro e la complessità della scrittura del codice. |
| I dati possono essere archiviati e recuperati in dimensioni ridotte | I dati possono essere archiviati e recuperati di grandi dimensioni |
| Meno sicurezza | Maggiore sicurezza |
| Sistema monoutente | Sistema multiutente |
| La maggior parte dei DBMS non supporta l'architettura client/server | Supporto architettura client/server |
In un RDBMS, viene data maggiore importanza a una relazione. Di conseguenza, le tabelle nell'RDBMS dipendente e l'utente possono impostare diversi vincoli di integrità su queste tabelle in modo che i dati finali consumati dall'utente rimangano corretti. Nel caso di un DBMS, agli oggetti viene data maggiore importanza e non esiste una relazione stabile tra queste entità.
In questo articolo, spero che tu capisca la differenza e la cronologia di sviluppo del database fino ai giorni nostri. Se l'articolo contiene errori, commenta di seguito per consentire al team di aggiornare e non esitare a porre domande, buona fortuna per i tuoi studi!
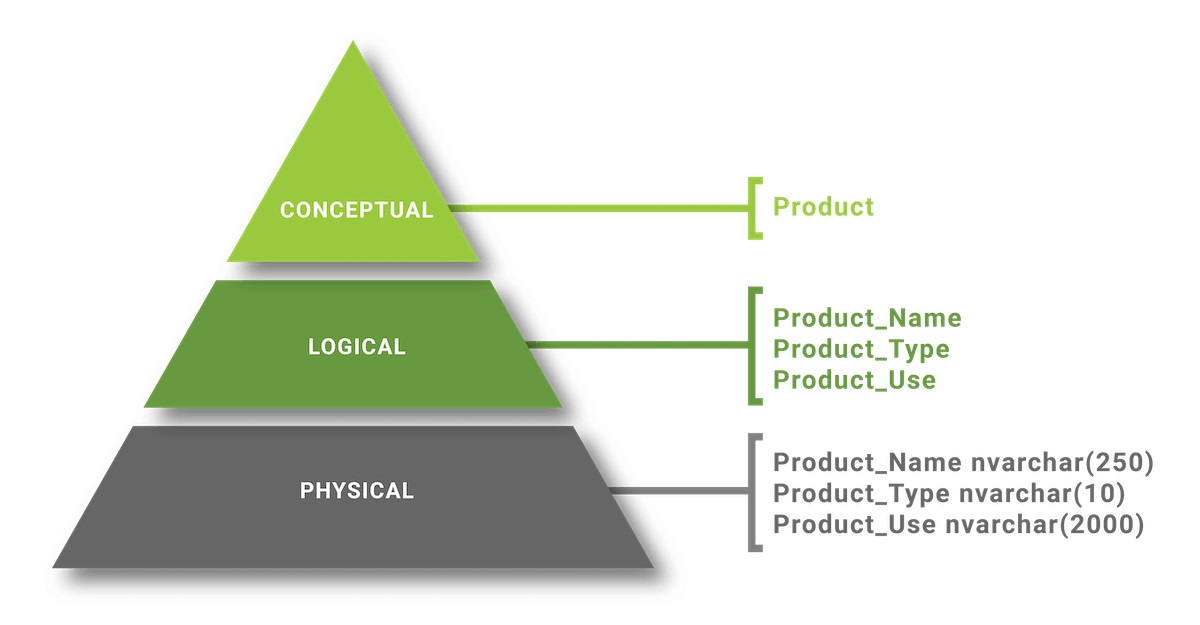
Un modello di dati è un gruppo di strumenti concettuali utilizzati per descrivere i dati, le loro relazioni e i loro significati. Includono anche vincoli di coerenza che i dati dovrebbero seguire. Nel modello Entità – Relazione, la relazione di rete o il modello gerarchico sono tutti esempi di modelli di dati, vedere l'articolo Introduzione […]
hocvietcode.com là website chia sẻ và cập nhật tin tức công nghệ, chia sẻ kiến thức, kỹ năng. Chúng tôi rất cảm ơn và mong muốn nhận được nhiều phản hồi để có thể phục vụ quý bạn đọc tốt hơn !
Liên hệ quảng cáo: trienkhaiweb@gmail.com