Indice in SQL Server
Mục lục
Introduzione all’indice
Un indice è una struttura dati speciale associata a una tabella o vista per velocizzare le query. In poche parole, quando indicizzi un campo in una tabella, i valori di quel campo verranno organizzati e archiviati in modo strutturato, il che aiuterà a interrogare i dati in modo più efficiente in termini di prestazioni e velocità. L’elenco degli indici comuni in SQL Server è il seguente:
| Tipo di indice | Descrivere |
| Raggruppato | Ordina e memorizza le righe di dati di una tabella o di una visualizzazione in ordine in base alle chiavi. L’indice cluster implementato nella struttura B-Tree supporta l’acquisizione di dati di riga, in base agli indici dei valori chiave |
| Non raggruppato | Gli indici non in cluster vengono eliminati in una tabella o vista che contiene dati in una struttura cluster o in un heap. Ogni riga dell’indice nell’indice non cluster contiene il valore della chiave e un localizzatore di riga. Il localizzatore punta alla riga di dati nell’indice cluster o nell’heap con il valore di chiave. Le righe nell’indice vengono archiviate nell’ordine dei valori della chiave dell’indice, ma non è garantito che le righe di dati siano in un ordine particolare a meno che non venga creato un indice cluster nella tabella. |
| Unico | Un indice univoco garantisce che la chiave dell’indice non contenga valori duplicati e quindi ogni riga nella tabella o nella vista è in qualche modo univoca. L’unicità può essere una proprietà di indici cluster e non cluster. |
| Columnstore | Index Columnstore archivia e gestisce i dati utilizzando l’archiviazione dei dati in memoria basata su colonne e l’elaborazione di query basata su colonne Index Columnstore funziona quando i carichi di lavoro di archiviazione dati eseguono principalmente il caricamento integrato e le code di sola lettura. Utilizza index columnstore per ottenere prestazioni di query fino a 10 volte superiori rispetto allo storage tradizionale orientato alle righe e una compressione dei dati fino a 8 volte per dimensioni dei dati non compressi |
| filtrato | Gli indici cluster sono ottimizzati per includere query che selezionano da un sottoinsieme di dati ben definito. Utilizza un predicato di filtro per indicizzare parte delle righe della tabella. Un indice filtrato ben progettato può migliorare le prestazioni delle query, ridurre i costi di manutenzione dell’indice e ridurre i costi di archiviazione dell’indice rispetto agli indici a tabella intera. |
| Spaziale | Fornisce la possibilità di eseguire alcune operazioni più efficienti su oggetti spaziali all’interno di una colonna di tipo di dati geometrici. |
| XML | A causa delle grandi dimensioni delle colonne XML, le query di ricerca in queste colonne possono essere lente. Puoi velocizzare queste query creando un indice XML per colonna. L’indice XML può essere un indice cluster o un indice non cluster. |
Esistono anche altri tipi di indici come Hash, Ottimizzazione della memoria non cluster, indice con colonna inclusa, indice su colonna calcolata, testo completo.
SQL Server utilizza indici simili a come viene indicizzato un libro. Ad esempio, per una situazione in cui vogliamo trovare tutte le chiavi “INSERT” in un libro di apprendimento SQL, l’approccio immediato adottato sarebbe quello di scansionare ogni pagina del libro partendo dalla pagina iniziale, quindi aggiungere ogni volta ai segnalibri la parola “INSERT ” si trova, fino alla fine del libro. Questo approccio richiede tempo e fatica. Il secondo modo utilizzato è utilizzare il sommario del libro e andare alla pagina in cui i risultati parlano di INSERT e trovare quella pagina, usarla. Il metodo 2 risulta simile al metodo uno ma consente di risparmiare più tempo e fatica.
Quando SQL Server non definisce un indice, si comporterà come il primo modo nell’esempio, il motore SQL dovrà accedere a ogni record nel database, in termini di database, questo comportamento è chiamato scansione tabella o semplicemente scansione.
La scansione della tabella non è inefficiente, ma in alcune situazioni specifiche dovremo utilizzare un’altra soluzione che consiste nell’utilizzare gli indici per aumentare le prestazioni, perché man mano che la tabella dei dati cresce con il numero di record che aumenta fino a milioni, le scansioni saranno lente e le risorse -intensivo, in questa situazione, gli indici sono sempre consigliati.
Panoramica sull’archiviazione dei dati
Un libro contiene pagine, all’interno ci sono paragrafi e frasi, simili a SQL Server che archivia i dati in unità chiamate pagine di dati. Queste pagine contengono dati in righe.
Ogni pagina del libro ha dimensioni fisiche. Allo stesso modo, in SQL Server tutte le pagine di dati hanno la stessa dimensione di 8 KB. Ovvero, un database contiene 128 pagine di dati per megabyte (MB) di spazio di archiviazione.
Una pagina inizia con un’intestazione di 96 byte, che memorizza le informazioni di sistema sulla pagina, che includono:
- Numero di pagine
- Stile pagina
- Quantità di spazio libero nella pagina
- L’ID di attribuzione dell’oggetto per la pagina attribuita
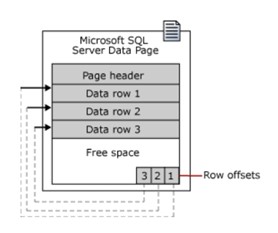
Nota: la pagina dati è l’unità di archiviazione dati più piccola. Un’unità di allocazione è una raccolta di pagine di dati raggruppate in base al tipo di pagina. Il raggruppamento renderà la governance dei dati più efficiente.
File di dati
Tutte le attività di input e output nel database vengono gestite a livello di pagina. Ciò significa che il motore di database legge o scrive pagine di dati. Un insieme di otto pagine consecutive è chiamato extent .
SQL Server archivia le pagine di dati in file chiamati file di dati. Lo spazio allocato per il file di dati è suddiviso nel numero di pagine di dati disposte in sequenza, le pagine iniziano da 0 , rappresentazione geometrica come mostrato di seguito.
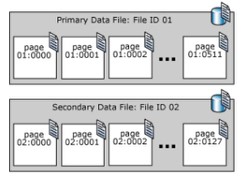
Esistono 3 tipi di 3 file di dati spiegati come segue:
- Primario: il file principale viene creato automaticamente al momento della creazione del database, questo file ha riferimenti a tutti i file rimanenti nel database. L’estensione consigliata e predefinita per i file di dati primari è .mdf
- Secondari: sono file di dati definiti dall’utente facoltativi. I dati possono essere distribuiti su più unità posizionando ciascun file su un’unità diversa. L’estensione consigliata per i file di dati secondari è .ndf
- Registro delle transazioni: i file di registro memorizzano le informazioni sulla cronologia delle modifiche nel database. Queste informazioni sono utili per il ripristino dei dati di backup come un’improvvisa interruzione di corrente o la necessità di spostare il database su un altro server. C’è almeno un file di registro in ogni database. L’estensione consigliata per i file di registro è .ldf
Requisiti per gli indici
Per facilitare il recupero rapido dei dati da un database, SQL Server fornisce una funzionalità di indicizzazione, simile al sommario di un libro, l’indice in un database di SQL Server contiene informazioni che consentono di cercare i dati uno alla volta correttamente senza eseguire la scansione dell’intero tavolo.

Indice
In una tabella, i record sono archiviati nell’ordine in cui sono stati inseriti, sono archiviati nel database senza essere ordinati o in altre parole è ordinato in base alla cronologia degli input. Quando i dati vengono recuperati dalla tabella, sarà necessario scansionare l’intera tabella, il che rallenta il processo. Per accelerare il processo, facciamo qualcosa chiamato indicizzazione.
Quando viene creato un indice nella tabella, viene creata una versione ordinata del record, che accelera l’individuazione e il recupero dei dati durante una ricerca.
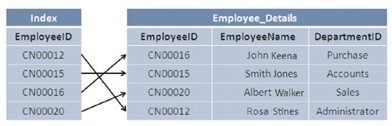
L’indice viene creato automaticamente quando i vincoli PRIMARY KEY e UNIQUE sono definiti nella tabella, l’indicizzazione riduce le attività di lettura e scrittura del disco e consuma meno risorse di sistema.
Sintassi:
CREATE INDEX <index_name> ON <table_name> (<column_name>)L’indice punta alla posizione del record nella pagina dei dati invece di cercare nella tabella. Alcune caratteristiche dell’indice:
- Gli indici velocizzano una query che si unisce a una tabella o gestisce le attività di ordinamento.
- Index implementa l’univocità delle righe se definite al momento della creazione dell’indice.
- Gli indici vengono creati e mantenuti nell’ordinamento in avanti e all’indietro.
Il copione
Ad esempio, in una rubrica ci sarà una grande quantità di dati ordinati e consultati frequentemente, i dati verranno memorizzati in ordine alfabetico. Se i dati non sono ordinati, è quasi impossibile trovare rapidamente un numero di telefono specifico.
Allo stesso modo, in una tabella di database che ha un numero elevato di record e deve essere interrogata frequentemente, i dati verranno ordinati per un’esecuzione più rapida. Quando viene creato un indice per una tabella, l’indice ordina fisicamente o logicamente i record. Pertanto, la ricerca del record specificato diventa più veloce e riduce il carico di risorse di sistema.
dati di accesso a livello di gruppo
Gli indici sono utili quando si accede ai dati in gruppi. Ad esempio, si desidera creare una modifica che cambi reparti per il gruppo Risorse umane in base ai reparti su cui lavora il personale nel database. In questa situazione è possibile creare un indice per la colonna DepartmentName prima di accedere ai record.
Questo indice creerà frammenti di dati logici e raggrupperà i record nei reparti, limitando la quantità di dati effettivamente scansionati durante il recupero dei dati.
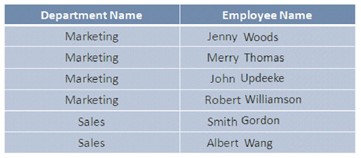
Architettura dell’indice
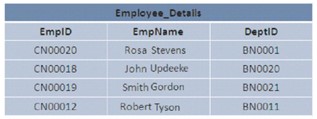
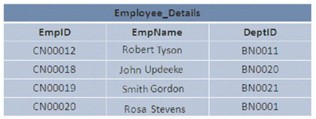
In SQL Server, i dati nel database possono essere archiviati in una disposizione determinata o casuale. Se i dati vengono archiviati in modo ordinato, si dice che i dati siano rappresentati in una struttura a grappoli. Se i dati vengono archiviati in modo casuale, viene chiamata struttura heap.
L’immagine illustra 2 strutture Heap e Cluster:
B-albero
In SQL Server, gli indici sono organizzati in una struttura B-Tree, ogni pagina in un indice B-tree è chiamata nodo dell’indice. Il nodo più alto è chiamato nodo radice. La nota in basso nell’indice è chiamata nodi foglia. Qualsiasi livello tra il nodo radice e il nodo foglia è chiamato nodo intermedio.
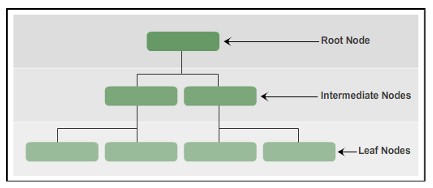
L’indice B-Tree va dalla parte superiore del nodo alla parte inferiore tramite un puntatore.
Struttura dell’indice B-Tree
Nella struttura B-Tree di un indice, il nodo radice include una pagina di indice. La pagina dell’indice contiene un puntatore e punta alla pagina dell’indice che rappresenta il primo livello intermedio. Queste pagine indice a loro volta puntano alle pagine indice presenti al livello intermedio successivo. Possono esserci più livelli intermedi in un indice B-Tree. Il nodo foglia nell’indice B-Tree ha una pagina dati che contiene dati di record o contiene una pagina dati che archivia record di indice che puntano a record di dati sulla tabella.
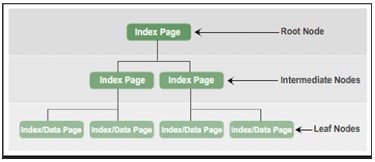
In sintesi, i tipi di nodo nell’indice B-tree sono conformi:
- Nodo principale: contiene una pagina di indice con un puntatore alle pagine di indice nel livello intermedio.
- Nodi intermedi : contiene pagine indice con puntatori a pagine indice nel livello intermedio o pagine indice o dati nel livello foglia.
- Nodi foglia: contiene pagine di dati o pagine di indice che puntano a pagine di dati.
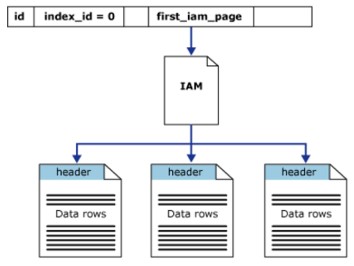
Struttura a cumulo
L’heap è una tabella senza un indice cluster. Ciò significa che, nella struttura dell’heap, le pagine di dati ei registri non sono ordinati. L’unico collegamento tra le pagine di dati sono le informazioni registrate nella pagina Index Allocation Map (IAM).
Ulteriori informazioni sulla struttura dell’heap dei termini nella struttura dei dati: https://en.wikipedia.org/wiki/%C4%90%E1%BB%91ng_(c%E1%BA%A5u_tr%C3%BAc_d%E1 %BB% AF_li%E1%BB%87u)#:~:text=In%20khoa%20h%E1%BB%8Dc%20m%C3%A1y%20t%C3%ADnh,%C4%91%C6%B0% E1%BB %A3c%20g%E1%BB%8Di%20l%C3%A0%20max%2Dheap.
L’heap ha una riga in sys.partitions, con index_id = 0 per ogni partizione utilizzata dall’heap. Per impostazione predefinita, un heap ha una propria partizione, quando l’heap ha più partizioni, ogni partizione avrà una struttura heap che contiene i dati definiti. Ad esempio, l’heap ha 4 partizioni, ci saranno 4 strutture di heap, ciascuna in una partizione.
Come minimo, ogni heap avrà un IN_ROW_DATA allocato per unità di partizione. L’heap ha anche LOB_DATA allocato per unità di partizione, se contiene una colonna LOB (large object). Avrà anche un’allocazione ROW_OVERFLOW_DATA per unità di partizione, se non contiene colonne di lunghezza nota, il limite di dimensione massima è 8060 record.
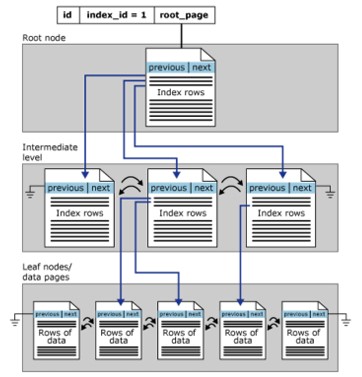
Struttura dell’indice a grappolo
Gli indici raggruppati sono organizzati in un formato B-Tree. Ogni pagina nell’indice B-Tree è chiamata nodo dell’indice. Simile nel concetto, il nodo superiore dell’indice cluster è anche il nodo radice e il nodo inferiore è il nodo foglia,
- I nodi foglia contengono le pagine di dati di base della tabella, i livelli radice e intermedio contengono le pagine di indice che contengono le righe di indice. Ciascun indice contiene un valore chiave e un puntatore a una pagina intermedia nell’albero B o a una riga di dati nel livello foglia dell’indice.
- Per impostazione predefinita, un indice cluster ha una singola partizione. Quando un indice cluster ha più partizioni, ciascuna partizione sarà una struttura B-Tree contenente il valore di una partizione specificata.
- L’indice cluster ha anche un LOB_DATA allocato a ciascuna partizione se è contenuto in una colonna LOB (oggetto grande). E ha anche un’allocazione ROW_OVERFLOW_DATA in ogni singola partizione.
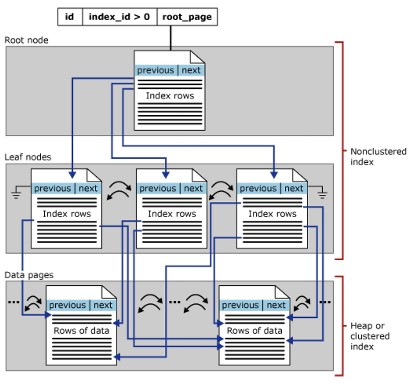
Struttura dell’indice non cluster
Un indice non cluster ha le stesse strutture B-Tree di un indice cluster, ma con le seguenti differenze:
- Le righe di dati della tabella non vengono archiviate fisicamente nell’ordine determinato dalle loro chiavi indifferenziate.
- Nella struttura dell’indice non cluster, il livello foglia conterrà le righe dell’indice.
- Gli indici non cluster sono utili quando sono necessari più modi per trovare i dati.
- Quando viene ricreato un indice cluster o viene utilizzata l’opzione DROP_EXISTING, SQL Server crea gli indici non cluster esistenti,
- Una tabella può avere fino a 888 indici non cluster
- Creare un indice cluster prima di creare un indice non cluster.
Indice archivio colonne (indice archivio colonne)
L’indice Columnstore è una funzionalità di SQL Server che mira a archiviare, recuperare e gestire i dati utilizzando i dati colonnari , chiamati columnstore.
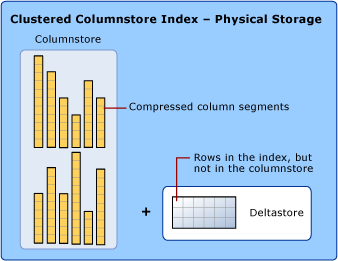
L’indice Columnstore utilizza due tipi di archiviazione dati: il formato rowstore e columnstore.
L’indice Columstore viene utilizzato principalmente per i seguenti motivi:
- Costi di stoccaggio ridotti
- Migliorare la prestazione
I dettagli dei formati columnstore,rowstore,deltastore sono i seguenti:
- Columnstore : i dati sono organizzati logicamente in tabelle con righe e colonne archiviate fisicamente nel formato dati del gruppo di colonne.
- Rowstore : i dati sono organizzati logicamente come una tabella con righe e colonne, quindi archiviati fisicamente in un formato di dati del gruppo di righe.
- Deltastore : mantiene la posizione delle righe quando hanno troppo pochi dati da comprimere in columnstore. Deltastore memorizza le righe nel formato rowstore.
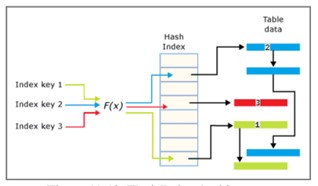
HashIndex
L’indice hash è costituito da un array di puntatori e ogni elemento nell’array è chiamato hash bucket.
- Ogni bucket ha una dimensione di 8 byte, utilizzato per memorizzare la posizione di memoria della chiave in una struttura di voci di elenco di collegamenti.
- Ogni voce è un valore per la chiave dell’indice, che è l’indirizzo corrispondente della riga nella tabella ottimizzata per la memoria.
- Ciascuna voce punta alla voce successiva in un elenco di collegamenti voci, tutte concatenate (che possono essere interpretate come un blocco a catena al bucket corrente).
Il numero di bucket dovrà essere definito al momento della definizione e avere alcune delle seguenti proprietà:
- I collegamenti a elenchi brevi vengono gestiti più velocemente dei collegamenti a elenchi lunghi.
- Possono esserci al massimo 1.073.741.824 bucket nell’indice hash.
Indice XML
È possibile creare un indice XML per colonne di tipo di dati XML. Indicizzeranno tag, valori e percorsi all’interno di istanze XML all’interno di colonne e aumenteranno le prestazioni delle query. La tua applicazione potrebbe avere un vantaggio con un indice XML nei seguenti casi:
Le query delle colonne XML sono comuni nel carico di lavoro. È necessario considerare il costo delle risorse per la gestione dell’indice xml durante le modifiche ai dati.
Quando i valori XML sono relativamente grandi e le parti a cui si accede sono relativamente piccole, la costruzione dell’indice evita di dover analizzare tutti i dati in fase di esecuzione ed è vantaggiosa per le ricerche nell’indice per l’elaborazione delle query.
Esistono due tipi di indici XML:
- Indice XML primario
- Indice XML secondario
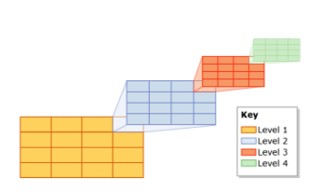
Indice spaziale (indice spaziale)
In SQL Server, gli indici spaziali utilizzano B-tree, il che significa che gli indici devono essere rappresentati in due dimensioni spaziali nella disposizione lineare dell’albero B. Pertanto, prima di leggere i dati all’interno dell’indice spaziale, SQL Server implementa un modello di stratificazione spaziale gerarchico uniforme. Il processo di indicizzazione separa lo spazio in una gerarchia di griglia a quattro livelli.
Indice full-text
La creazione e la gestione di un indice full-text implica l’indicizzazione mediante un processo noto come aggregazione noto anche come ricerca per indicizzazione.
Tipi di raccolta delle informazioni:
- Piena popolazione
- Popolamento automatico/manuale basato sul rilevamento delle modifiche
- Popolazione incrementale feroce sul timestamp
Crea indice raggruppato
L’istruzione di indice CREATE CLUSTERED consente all’utente di creare un indice CLUSTERED per una colonna e una tabella specificate.
Sintassi:
CREATE CLUSTERED INDEX index_name ON table_name (column1,column2,...);Per esempio:
USE AdventureWorks2019 CREATE TABLE Production.Parts( part_id INT NOT NULL, part_name VARCHAR(100) ) CREATE CLUSTERED INDEX ix_parts_id ON Production.parts (part_id);RINOMINA INDICE
sp_rename è una procedura memorizzata di sistema che consente di rinominare qualsiasi oggetto creato dall’utente nel database corrente, inclusi tabelle, indici e colonne.
Sintassi:
EXEC sp_rename index_name,new_index_name, N'INDEX';Per esempio:
EXEC sp_rename N'Production.parts.ix_parts_id', N'index_part_id',N'INDEX';Oppure fai clic con il pulsante destro del mouse sull’indice in Esplora oggetti e seleziona l’opzione rinomina
DISATTIVA INDICE
Per disabilitare l’indice, viene utilizzata l’ istruzione ALTER INDEX .
Sintassi
ALTER INDEX index_name ON table_name DISABLE;Per esempio:
ALTER INDEX index_part_id ON Production.Parts DISABLE; select * from Production.PartsDopo aver disabilitato l’indice, durante la query dei dati verrà visualizzato un errore:
The query processor is unable to produce a plan because the index 'index_part_id' on table or view 'Parts' is disabled.ABILITA INDICE
Per abilitare l’indicizzazione, viene utilizzata l’ istruzione ALTER INDEX .
Sintassi:
ALTER INDEX index_name ON table_name REBUILD;Per esempio:
ALTER INDEX index_part_id ON Production.Parts REBUILD;INDICE DI CADUTA
L’istruzione DROP INDEX rimuoverà l’indice dal database corrente.
Sintassi:
DROP INDEX [IF EXISTS] index_name ON table_name;Per esempio:
DROP INDEX IF EXISTS index_part_id ON Production.Parts;Indice non cluster
Un indice non cluster è una struttura di dati che aumenta la velocità di recupero dei dati da una tabella. A differenza di un indice cluster, un indice non cluster ordina e archivia i dati in modo frammentario dalle righe di dati in una tabella.
Sintassi:
CREATE [NONCLUSTERED] INDEX index_name ON table_name(column1,column2,...);Per esempio:
CREATE NONCLUSTERED INDEX index_customer_storeid ON Sales.Customer(StoreID);Indice unico
L’indice univoco garantisce che le colonne indexkey non contengano valori duplicati.
Può contenere una o più colonne, se l’indice univoco ha una colonna, il valore della colonna sarà univoco, nel caso di un indice univoco con molte colonne, la combinazione di questi valori di colonna è unica.
Nota: l’indice univoco può essere raggruppato o non raggruppato.
Sintassi per creare un indice univoco:
CREATE UNIQUE INDEX index_name ON table_name(column_list);Per esempio:
CREATE UNIQUE INDEX AK_Customer_rowguid ON Sales.Customer(rowguid);Indice filtrato
L’indice filtrato è un indice non cluster che consente di determinare quali righe vengono aggiunte all’indice.
Sintassi:
CREATE INDEX index_name ON table_name(column_list) WHERE predicate;Per esempio:
CREATE INDEX index_cust_personID ON sales.Customer(PersonID) WHERE PersonID IS NOT NULL;Tabelle e indici partizionati
SQL Server supporta due tipi di tabelle e partizioni di indice (partizioni). I dati di una tabella partizionata e indicizzata sono divisi in un’unità facoltativa che può estendersi facoltativamente su più gruppi di file nel database. I dati vengono partizionati orizzontalmente, raggruppando così le righe mappate (unite) in una partizione separata.Tutte le partizioni di una singola tabella o indice devono trovarsi sullo stesso database. La tabella o l’indice viene trattato come un oggetto durante l’esecuzione di query o l’aggiornamento dei dati.
Per impostazione predefinita SQL Server 2019 supporta fino a 15.000 partizioni.
Vantaggi del partizionamento:
- Converti o interroga i dati in modo rapido ed efficiente.
- Trattando le attività di persistenza su una o più partizioni, le attività sono più efficienti perché la loro destinazione è solo sul set di dati sulla partizione, piuttosto che sull’intera tabella.
- Aumenta le prestazioni delle query, i dati sul tipo di query eseguite di frequente e la configurazione hardware.
L’esempio crea una tabella di esempio con le seguenti informazioni:
CREATE TABLE testing_table(receipt_id BIGINT, date DATE) Specifica come verrà partizionata esattamente la tabella, in questo caso la colonna della data, insieme a
l’intervallo di valori verrà aggiunto in ciascuna partizione. Per quanto riguarda i limiti delle partizioni, puoi specificare SINISTRA o DESTRA (lato sinistro o destro)
CREATE PARTITION FUNCTION partition_function (int) AS RANGE LEFT FOR VALUES (20200630,20200731,20200831);Ciò significa diviso in 4 partizioni come segue:
- Partizione 1: tutti i record con data <= 30-06-2020
- Partizione 2: tutti i record con data > 30-06-2020 e data <= 31-07-2020
- Partizione 3: tutti i record con data > 31-07-2020 e data <= 31-08-2020
- Partizione 4: tutti i record con data > 31-08-2020
Il codice seguente ti consentirà di identificare la regione phana in cui è inserito ogni record
(SELECT 20200613 date, $PARTITION.partition_function(2020613) AS PartitionNumber) UNION (SELECT 20200713 date, $PARTITION.partition_function(2020713) AS PartitionNumber) UNION (SELECT 20200813 date, $PARTITION.partition_function(20200813) AS PartitionNumber) UNION (SELECT 20200913 date, $PARTITION.partition_function(20200913) AS PartitionNumber)
Indice XML
I dati XML vengono archiviati in un tipo di colonna il cui tipo di dati XML è un tipo di dati che consuma molte dimensioni, chiamato Large Binary Objects (BLOB).
Per rappresentare i dati xml, la dimensione del tipo di dati può arrivare fino a 2 GB.
L’indice XML viene creato su una colonna contenente dati XML e archiviato nella tabella e nel database.
Per esempio:
CREATE PRIMARY XML INDEX PXML_PRoduct_Model_Catalog_Description ON Production.ProductModel (CatalogDescription);L’indice XML primario contiene tutti i dati nella colonna XML. Per fornire maggiori prestazioni alla query XML, puoi aggiungere indici secondari. Anche gli indici XML secondari utilizzano lo stesso set di dati poiché è l’indice primario sottostante, ma crea un indice più specifico. , basato sull’indice primario.
Per esempio:
CREATE XML INDEX IXML_ProductModel_CatalogDescription_Path ON Production.ProductModel (CatalogDescription) USING XML INDEX PXML_ProductModel_CatalogDescription FOR PATH;Indice Columnstore
Sintassi:
CREATE COLUMNSTORE INDEX IX_SalesOrderDetail_ProductIDOrderQty_ColumnStore ON Sales.SalesOrderDetail (ProductID,OrderQty);La creazione di questo indice migliorerà il gruppo per query quando si utilizzano funzioni aggregate, ma eseguire nuovamente il test con il proprio ambiente, poiché nel proprio SSMS è attualmente in esecuzione questo errore di timeout del comando.
SELECT ProductID,SUM(OrderQty) FROM Sales.SalesOrderDetail GROUP BY ProductId;