
Introduzione all'apprendimento automatico
Mục lục
Perché imparare l'apprendimento automatico?
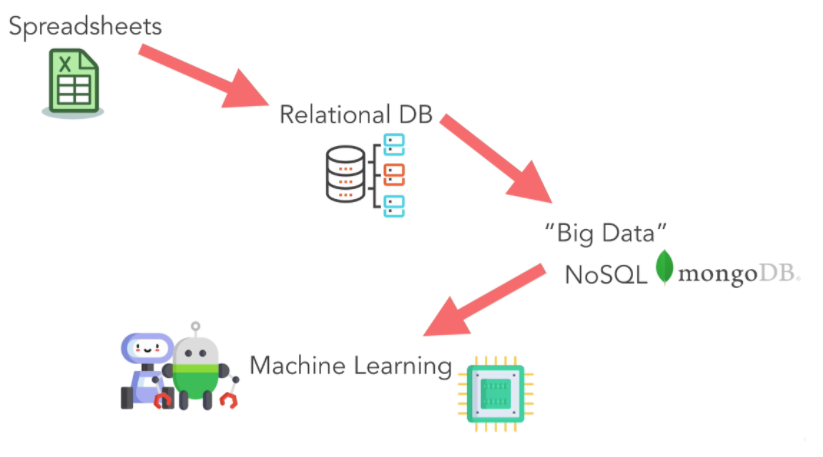
- Fogli di calcolo (Excel, CSV): come luogo in cui archiviare i dati aziendali necessari, è uno degli strumenti più utili oggi disponibili. Ci aiuta ad analizzare e rappresentare i dati di cui un'azienda ha bisogno.
- DB relazionale (MySQL): è un luogo di archiviazione dei dati migliore rispetto ai fogli di calcolo e viene eseguito tramite istruzioni di query, da cui l'azienda può utilizzare le istruzioni per cercare ed elaborare i dati.
- Big Data (NoSQL): FB, Amazon, Shopee, … a causa dei dati utente di grandi dimensioni, si chiama big data e qui i dati non sono strettamente organizzati, quindi è necessario utilizzare l'apprendimento automatico al posto dei bambini decisori.
Diverse aree sono legate all'apprendimento automatico.
Intelligenza artificiale AI?
L'intelligenza artificiale o intelligenza artificiale (AI) è una branca dell'informatica. Un'intelligenza creata dagli esseri umani con l'obiettivo di aiutare i computer ad automatizzare comportamenti intelligenti come gli esseri umani.
Apprendimento automatico
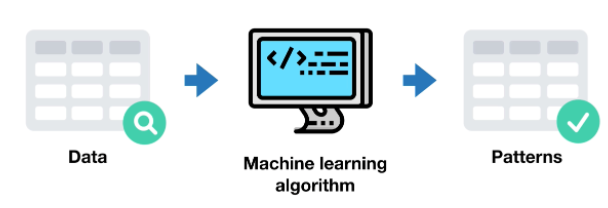
Come sottoramo dell'intelligenza artificiale, l'apprendimento automatico utilizza algoritmi ( algoritmi ) o programmi per computer per apprendere dati diversi e quindi utilizza l'algoritmo e ciò che ha appreso in precedenza per fare una previsione, indovinare o riclassificare sulla base di dati simili.
Esempio: categorizzazione o analisi del prodotto.
Differenza tra Machine Learning e algoritmi normali
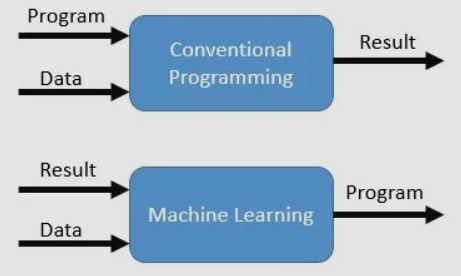
- Algoritmo normale: usa input + algoritmo -> risultato (output).
- Algoritmo macchina: inizia con input e output -> da lì determina la relazione tra I/P e O/P.
Alcuni problemi nell'apprendimento automatico

Supervisionato: dati contenenti etichette
es: come i dati di cani e gatti,…
Non supervisionato: dati senza etichetta come un file excel senza intestazioni di colonna.
- Clustering: ci aiuta a raggruppare i gruppi. es: raggruppamento dei clienti in base alle preferenze del cliente.
- Apprendimento delle regole di associazione: associazione di più attributi per prevedere il comportamento dei clienti. es. Cosa comprare in futuro.
Rinforzo: insegna alla Macchina a provare e a fallire, così ci saranno ricompense per il suo miglioramento la prossima volta. es: applicato in alpha go – macchina per scacchi famosa in tutto il mondo.
Apprendimento approfondito
Il Deep Learning è un sottoinsieme del Machine Learning, in grado di essere diverso per alcuni aspetti importanti dal tradizionale Machine Learning superficiale, consentendo ai computer di risolvere un'ampia gamma di problemi complessi irrisolvibili.
Scienza dei dati
Analisi dei dati: analizza i dati da lì per creare i rapporti necessari.
Data Science: esegui test sui set di dati per trovare informazioni utili su tali dati.
Come funziona l'apprendimento automatico

Passaggio 1 : identificare il problema: convertire la frase del cliente nel problema dell'apprendimento automatico.
È necessario determinare quale sia il problema che deve essere risolto?
- Supervisionato
- Senza supervisione
- Classificazione
- Regressione
Passaggio 2 : Dati: qual è il tipo di dati esistente?
Passaggio 3 : valutazione
- Determina quando l'algoritmo è corretto.
- Gli indicatori che richiedono attenzione ci aiutano a valutare il progetto.
Passaggio 4: funzionalità dei dati (funzionalità)
- Quali caratteristiche hanno i tuoi dati e quali caratteristiche devi usare per costruire il modello? Da lì trasforma le caratteristiche in modelli.
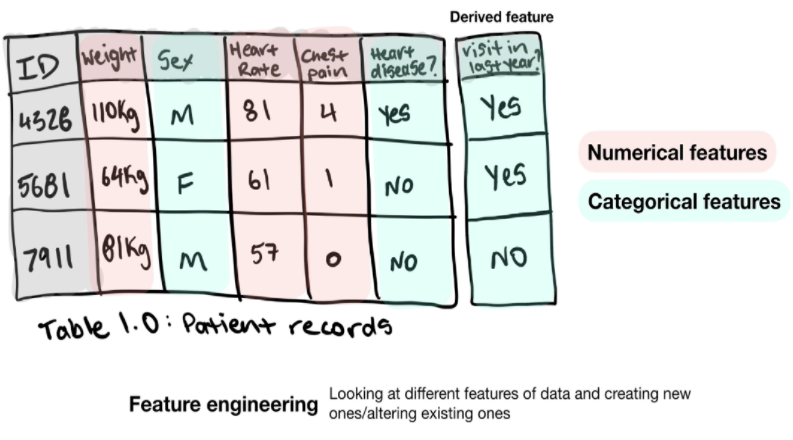
- Esistono 3 tipi principali di funzionalità:
- Caratteristiche categoriali: possono essere di genere o sì/no.
- Funzionalità continue (o numeriche): un valore numerico come l'intervallo del messaggio o il numero di volte in cui viene eseguita un'azione.
- Funzionalità derivate (il tipo di funzionalità create dai dati): spesso chiamate ingegneria delle funzionalità. Ad esempio, quando ottieni velocità e tempo dai tuoi dati iniziali, puoi creare una funzione derivata che è la distanza percorsa.
Passaggio 5 : modelli
Al giorno d'oggi, ci sono molte librerie che ti aiutano a risolvere i problemi, è importante determinare quando usare quale modello?
- Apprendimento supervisionato: (Input & Output) Dati + Etichetta → Classificazioni, Modello di regressione,…
- Apprendimento non supervisionato: solo input) Dati → Clustering,…
- Apprendimento per rinforzo: completamento e gratificazione: è necessario trovare un modo per aggiornare i punteggi ML.
Passaggio 6 : testare, valutare.
Si prega di rivedere il modello e utilizzare metodi di valutazione algoritmici per vedere se il modello è corretto e quanto è accurato?
| Classificazione | Regressione | Raccomandazione |
|---|---|---|
| Precisione | Errore assoluto medio (MAE) | Precisione in KY |
| Precisione | Errore quadratico medio (MSE) | |
| Richiamare | Errore quadratico medio della radice (RMSE) |
Alcuni problemi comuni nell'elaborazione dell'apprendimento automatico.

Sovraccarico
Quando il set di dati di addestramento è buono e i dati di test sono buoni, il tuo modello generale non è buono.
Soluzione : prova a utilizzare un modello più semplice e assicurati che i dati del test abbiano lo stesso tipo dei dati di addestramento.
Inadeguato
Le prestazioni dei dati di allenamento sono scarse, quindi i tuoi dati non sono stati appresi correttamente in primo luogo. Porta all'insufficienza.
Soluzione: provare a dividere nuovamente l'addestramento dei dati e il test dei dati e provare a regolare i parametri dei dati.












