Istruzione SELECT di SQL Server e clausole di query dei dati
Molte versioni di sql utilizzano FROM nelle query, ma in tutte le versioni da SQL Server 2005, incluso SQL Server 2019, è possibile utilizzare le istruzioni SELECT senza utilizzare la clausola FROM.
Mục lục
Istruzione SELEZIONA
Una tabella con i suoi dati può essere visualizzata utilizzando l'istruzione SELECT. L'istruzione SELECT in una query visualizza le informazioni richieste in una tabella. L'istruzione SELECT recupera le righe e le colonne per una o più tabelle. L'output dell'istruzione SELECT è un'altra tabella denominata set di risultati. L'istruzione SELECT unisce anche due tabelle o recupera un sottoinsieme di colonne da una o più tabelle. L'istruzione SELECT definisce le colonne utilizzate per una query. La sintassi dell'istruzione SELECT può includere una serie di espressioni separate da virgole. Ogni espressione nell'istruzione è una colonna nel set di risultati. Le colonne vengono visualizzate nello stesso ordine dell'espressione nell'istruzione SELETt. L'istruzione SELECT recupera le righe dal database e consente di selezionare una o più righe.
Per quanto riguarda la sequenza di esecuzione, la clausola SELECT verrà eseguita per ultima, anche se è scritta all'inizio della frase
Sintassi:
SELECT <column_name1> [,column_name2] FROM <table_name>Per esempio:
SELECT [BusinessEntityID] ,[PersonType] ,[NameStyle] ,[Title] ,[FirstName] ,[MiddleName] ,[LastName] ,[Suffix] ,[EmailPromotion] ,[AdditionalContactInfo] ,[Demographics] ,[rowguid] ,[ModifiedDate] FROM [AdventureWorks2019].[Person].[Person]Selezionare senza DA
Molte versioni di SQL utilizzano FROM nelle query, ma in tutte le versioni da SQL Server 2005, incluso SQL Server2019, l'istruzione SELECT può essere usata senza usare la clausola FROM.
Per esempio:
SELECT LEFT ('Hello World',5) 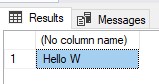
Mostra tutte le colonne
La parola chiave asterisco (*) viene utilizzata per l'istruzione SELECT per recuperare i dati dell'intera colonna nella tabella. Viene utilizzato come abbreviazione invece di scrivere un elenco di tutte le colonne della tabella.
Sintassi:
SELECT * FROM <table_name>Per esempio:
SELECT * FROM [AdventureWorks2019].[Person].[Person]Il segno * è molto comodo nel caso in cui ci siano troppe colonne e non riesci a ricordare tutti i nomi delle colonne, o è troppo lungo da scrivere. Tuttavia, in pratica, non dovresti abusare troppo del segno * perché in questo modo il sistema funzionerà molto duramente perché i dati saranno ridondanti. Ad esempio, se crei una funzione che mostra i nomi utente, scrivi semplicemente select username is ok, non necessariamente SELECT * perché l'eliminazione di più colonne ridurrà le prestazioni e consumerà più ram.
Espressioni diverse da SELECT
L'istruzione SELECT consente all'utente di specificare diverse espressioni per visualizzare il set di risultati in modo ordinato. Queste espressioni assegnano nomi diversi alle colonne nel set di risultati, calcolano i valori e rimuovono i valori duplicati.
Utilizzo di costanti negli insiemi di risultati
Le costanti stringa vengono utilizzate quando le colonne di caratteri vengono concatenate insieme. Aiutano con una corretta formattazione o leggibilità. Queste costanti non sono specificate come una colonna separata nel set di risultati. Di solito è più efficiente per l'applicazione creare valori costanti nei risultati mentre vengono visualizzati piuttosto che utilizzare il server per combinare i valori costanti. Ad esempio, per includere ":" e "->" nel set di risultati per visualizzare il nome del paese, il prefisso del paese e il gruppo corrispondente, l'istruzione SELECT viene mostrata nell'esempio seguente:
USE AdventureWorks2019 SELECT Name+':'+CountryRegionCode+'->'+[Group] FROM Sales.SalesTerritory 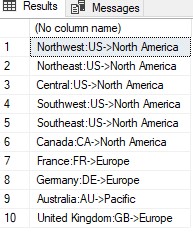
Rinomina la colonna nel set di risultati
Le colonne visualizzate nel set di risultati delle query con il titolo corrispondente possono essere modificate, rinominate o assegnate a un nuovo nome utilizzando la clausola AS. Personalizzando le intestazioni, diventano più comprensibili e semantiche.
Per esempio:
USE AdventureWorks2019 SELECT Name+':'+CountryRegionCode+'->'+[Group] AS NameRegion FROM Sales.SalesTerritory 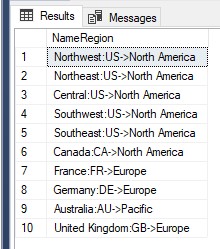
Calcola il valore nel set di risultati
L'istruzione SELECT può contenere espressioni matematiche applicando operatori a una o più colonne. Consente un set di risultati contenente valori che non esistono nella tabella di base, ma vengono calcolati dai valori memorizzati nella tabella di base.
Esempio 15% di sconto sul set di risultati da utilizzare per la visualizzazione promozionale:
USE AdventureWorks2019 SELECT ProductID,StandardCost,StandardCost*0.16 AS Discount FROM Production.ProductCostHistory GO 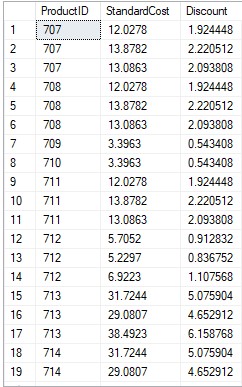
Usando DISTINCT
La parola chiave DISTINCT impedisce il recupero di record duplicati. Rimuove le righe ripetute dal set di risultati di un'istruzione SELECT. Ad esempio, se la colonna StandardCost è selezionata senza utilizzare la parola chiave DISTINCT, visualizzerà ogni record StandardCost solo una volta, come ad esempio:
USE AdventureWorks2019 SELECT DISTINCT ProductID,StandardCost,StandardCost*0.16 AS Discount FROM Production.ProductCostHistory GOUsando TOP e in SELECT
La parola chiave TOP mostrerà solo una parte del set di risultati. L'insieme di record sarà limitato dal numero o dalla percentuale (%), l'espressione TOP può essere utilizzata anche con istruzioni come INSERT, UPDATE, DELETE.
Sintassi:
SELECT [ALL|DISTINCT] [TOP expression [PERCENT] [NUMER]] FROM <table_name>Per esempio:
USE AdventureWorks2019 SELECT TOP 100 ProductID,StandardCost,StandardCost*0.16 AS Discount FROM Production.ProductCostHistory GOSELECT combinato con INTO
La clausola INTO crea una nuova tabella e vi inserisce le righe e le colonne elencate nell'istruzione SELECT.
La clausola INTO inserisce anche le righe esistenti nella nuova tabella. Per eseguire questa clausola con un'istruzione SELECT, l'utente deve disporre dell'autorizzazione CREATE TABLE nel database di destinazione.
Sintassi:
SELECT <column_name1>,[, <column_name2> ...] INTO <new_table> FROM table_listPer esempio:
USE AdventureWorks2019 SELECT ProductModelID, Name INTO Production.ProductName FROM production.ProductModel GO 
SELEZIONA combinato con DOVE
La clausola WHERE con un'istruzione SELECT viene utilizzata per selezionare condizionalmente o limitare (più comprensibile, filtrare i record) i record recuperati dalla query. La clausola WHERE specifica un'espressione booleana per esaminare le righe restituite dalla query. Le righe vengono restituite se l'espressione è vera e scartate se false.
Sintassi:
SELECT <column_name1> [, <column_name2> ...] FROM <table_name> WHERE <search_condition>Operatori relazionali in SELECT:
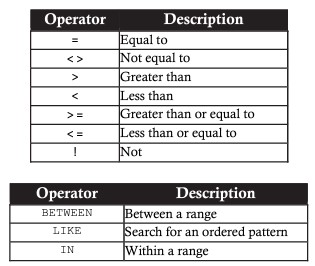
Esempio utilizzando la clausola WHERE per visualizzare i dati Voci Endate come data specificata
USE AdventureWorks2019 SELECT * FROM Production.ProductCostHistory WHERE EndDate ='2013-05-29' GO 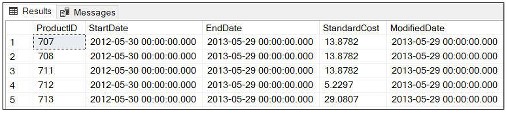
Tutte le query SQL utilizzano virgolette singole per racchiudere i valori di testo .
Per esempio:
USE AdventureWorks2019 SELECT * FROM Person.Address WHERE City='Bothell' 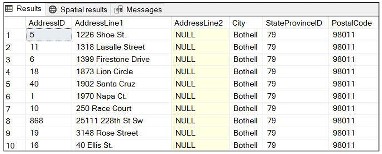
I valori numerici non devono utilizzare virgolette singole per racchiudere
Per esempio:
USE AdventureWorks2019 SELECT * FROM HumanResources.Department WHERE DepartmentID < 10 GO 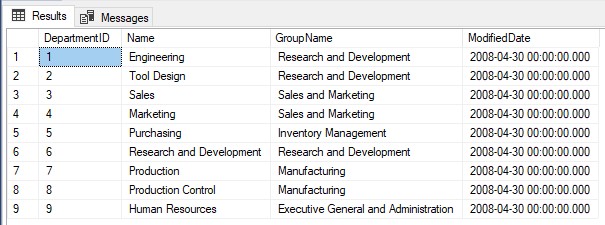
La clausola WHERE può essere utilizzata con caratteri jolly , che è il concetto di carattere utilizzato per la parola chiave LIKE per creare un'istruzione di query esatta e specifica.
| Carta jolly | Descrizione _ | Per esempio |
| _ | Rappresentazione di un singolo personaggio Documenti: https://docs.microsoft.com/en-us/sql/t-sql/language-elements/wildcard-match-one-character-transact-sql?view=sql-server-2017 | seleziona * da Person.Contact dove Suffisso come 'Jr_' |
| % | Rappresentazione di stringhe di qualsiasi lunghezza Documenti: https://docs.microsoft.com/en-us/sql/t-sql/language-elements/percent-character-wildcard-character-s-to-match-transact-sql?view=sql-server- 2017 | seleziona * da Person.Contact dove LastNam piace 'B%' |
| [ ] | Rappresenta un singolo carattere all'interno dell'area racchiusa tra parentesi quadre Documenti: https://docs.microsoft.com/en-us/sql/t-sql/language-elements/wildcard-character-s-to-match-transact-sql?view=sql-server-2017 | seleziona * da Sales.CurrencyRate dove ToCurrencyCode piace 'C[AN][DY]' |
| [^] | Rappresenta un singolo carattere che nega i caratteri racchiusi tra parentesi quadre. Documenti: https://docs.microsoft.com/en-us/sql/t-sql/language-elements/wildcard-character-s-not-to-match-transact-sql?view=sql-server-2017 | seleziona * da Sales.CurrencyRate dove ToCurrencyCode come 'A[^R][^S]' |
La clausola WHERE può essere utilizzata anche con operatori logici come AND, OR, NOT . Operatori utilizzati insieme alle condizioni di ricerca nella clausola WHERE
L'operatore AND combina 2 o più condizioni e restituisce TRUE solo se entrambe le condizioni sono soddisfatte, il risultato restituirà tutti i record se la condizione è soddisfatta.
Per esempio:
USE AdventureWorks2019 SELECT * FROM Person.Address WHERE AddressID > 900 AND City='Seattle' GOL'operatore OR restituisce TRUE e visualizza i record se soddisfa una delle condizioni nella clausola WHERE.
Per esempio:
USE AdventureWorks2019 SELECT * FROM Person.Address WHERE AddressID > 900 OR City='Seattle' GOL' operatore NOT è la negazione della condizione di ricerca
Per esempio:
USE AdventureWorks2019 SELECT * FROM Person.Address WHERE NOT AddressID = 5GROUP BY clausola
La clausola GROUP BY suddivide i risultati in uno o più sottoinsiemi. Ogni sottoinsieme ha valori ed espressioni comuni. Se viene utilizzata una funzione di aggregazione nella clausola GROUP BY, il set di risultati produrrà valori singoli per ogni aggregato
La parola chiave GROUP BY è seguita da un elenco di colonne, chiamato colonna raggruppata. Ciascuna colonna raggruppata limita il numero di righe del set di risultati. Per ogni colonna raggruppata è presente una sola riga.
La clausola GROUP BY può avere più di una colonna raggruppata.
SELECT <column_name1>, [, column_name2 , ...] FROM <table_name> GROUP BY <column_name>Per esempio:
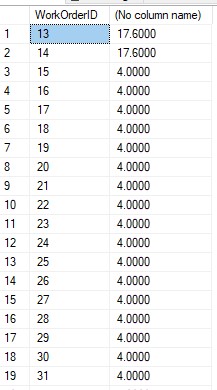
USE AdventureWorks2019 SELECT WorkOrderID,SUM(ActualResourceHrs) FROM Production.WorkOrderRouting GROUP BY WorkOrderID HAVING WorkOrderID < 50 GOIl risultato restituirà una tabella di gruppo WorkOrderID e somma la colonna ActualResourceHrs in base a WorkOrderID con WorkOrderID < 50
ORDINA PER clausola
Specifica l'ordinamento delle colonne in un set di risultati. Ordina la query in base a una o più colonne. L'ordinamento può essere crescente (ASC) o decrescente (DESC). Per impostazione predefinita, i record sono ordinati in ordine ASC. Per passare alla modalità decrescente, utilizzare la parola chiave facoltativa DESC. Quando si utilizzano più campi, SQL Server considera il campo più a sinistra come livello di ordinamento primario e gli altri come livello di ordinamento inferiore.
Sintassi:
SELECT <column_name> FROM <table_name> ORDER BY <column_name> (ASC|DESC)Per esempio:
SELECT * FROM Sales.SalesTerritory ORDER BY SalesLastYear GO 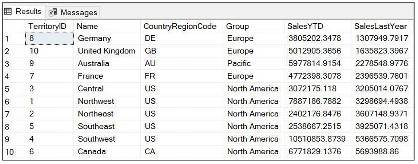
Lavorare con XML
Extensible Markup Language (XML) consente agli sviluppatori di tag di avere i propri significati e che altri programmi possono comprendere il significato di questi tag (simile ai tag HTML ma per l'archiviazione dei dati, non per i browser). leggi). XML è il mezzo preferito dagli sviluppatori per archiviare, formattare e gestire i dati sul Web. Le applicazioni odierne hanno una combinazione di tecnologie come ASP, tecnologia .NET, XML, server SQL che lavorano in tandem. In alcune situazioni, l'archiviazione di dati XML in SQL Server è una soluzione ragionevole.
Il database XML nativo in SQL Server presenta diversi vantaggi come segue:
- Prestazioni migliori: le query da database XML ben implementati sono più veloci delle query su documenti archiviati nel file system. Inoltre, il database in genere analizza ogni documento durante l'archiviazione.
- Facile gestione dei dati: i documenti di grandi dimensioni possono essere gestiti facilmente (perché XML è strutturato)
SQL Server supporta l'archiviazione dei dati XML in modo nativo utilizzando il tipo di dati xml. Il database XML nativo definisce un modello logico per un documento XML, come descrizione dei dati in quel documento, e archivia e recupera il documento in base a quel modello. Come minimo, il modello deve includere elementi, attributi, PCDATA e ordinamento dei documenti.
Tipo di dati XML
Oltre ai tipi di dati comunemente usati, SQL Server 2019 supporta i tipi di dati XML. Il tipo di dati XML viene utilizzato per archiviare documenti e segmenti XML nei database di SQL Server. Un segmento XML è un'istanza XML con un elemento di primo livello mancante nella sua struttura.
Sintassi:
CREATE TABLE <table_name> ([column_list,] <column_name> xml [, column_list])Per esempio:
USE AdventureWorks2019 CREATE TABLE Person.PhoneBilling (Bill_ID int PRIMARY KEY, MobileNumber bigint UNIQUE, CallDetails xml) GOLe colonne in stile XML possono anche essere aggiunte da una tabella a una tabella al momento della creazione. Le colonne del tipo di dati XML supportano i termini DEFAULT e i vincoli NOT NULL.
Per esempio:
AdventureWorks2019 INSERT INTO Person.PhoneBilling VALUES (100,98326505,'<Info><Call>Local</Call><Times>45 minuetes</Times><Charges>200</Charges></Info>') SELECT CallDetails FROM Person.PhoneBilling GO 
L' istruzione DECLARE viene utilizzata per creare variabili di tipo XML. Lo scopo dell'istruzione DECLARE viene utilizzato per dichiarare una variabile in SQL Server.
Sintassi:
DECLARE @LOCAL_VẢIABLE datatype [= value]I nomi delle variabili locali devono iniziare con un segno @. Il parametro value specificato nella sintassi è un parametro facoltativo che assegna un valore iniziale alla variabile durante la dichiarazione. Se non si specifica alcun valore iniziale da assegnare a una variabile, verrà inizializzata come NULL
Per esempio:
DECLARE @xmlvar xml SELECT @xmlvar='<Employee name="Toan"/>'Nota: il tipo di dati xml non può essere utilizzato come chiave primaria, chiave esterna o utilizzare il vincolo UNIQUE.
Esistono 2 modi per archiviare documenti XML in colonne con tipo di dati xml denominato XML tipizzato (con stile) e non tipizzato (senza stile). Un'istanza XML a cui è associato uno schema è chiamata istanza XML con stile. Uno schema è un'intestazione per un documento o una versione XML. Descrive le limitazioni della struttura e del contenuto dei documenti XML associando gli schemi XML alle versioni o ai documenti XML consigliati poiché i dati possono essere convalidati mentre vengono archiviati nella colonna tipo.xml data.
SQL Server non esegue alcuna convalida per i dati immessi nella colonna xml. Tuttavia, garantisce che i dati siano archiviati con un buon standard. I dati XML senza stile possono essere creati e archiviati in colonne di tabella o variabili a seconda delle esigenze e dell'ambito dei dati.
Il primo passaggio quando si utilizza XML tipizzato consiste nel registrare lo schema. Sintassi:
CREATE XML SCHEMA COLLECTION <Schema_Collection_name> AS '[xmldefine]'Per esempio:
CREATE XML SCHEMA COLLECTION OrderSchemaCollection1 AS N'<?xml version="1.0"?> <xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:element name="Customer" /> </xsd:schema>' GOCreare una tabella di tipo di dati Ordine come esempio:
CREATE TABLE myOrder (orderID int identity not null, orderInfo xml (OrderSchemaCollection))Inserisci il tipo XML appena creato:
insert into myOrder values ('<Customer></Customer>')Inoltre, possiamo creare completamente una variabile XML utilizzando Schema Collaction. Per esempio:
use myDB DECLARE @order xml (OrderSchemaCollection1) SET @order = '<Customer></Customer>' select @order GO 











