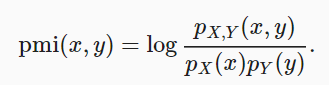
Metodo di selezione delle funzionalità in Machine Learning.
Infatti non tutti i dati sono chiari, le funzionalità sono utili per il modello. Ad esempio, quando si vuole prevedere il prezzo di una casa, non importa se il padrone di casa è un maschio o una femmina. Pertanto, è molto importante scegliere funzionalità utili al modello, che aiutano a ridurre il numero di dimensioni dei dati di input.
Fondamentalmente, utilizzeremo la probabilità per calcolare la relazione tra ciascuna caratteristica e il campo obiettivo da prevedere. Ma l'idea è che, usare qualsiasi formula o misura per determinare che la caratteristica non è buona è ancora una grande saggezza. In questo articolo, tu ed io impareremo attraverso alcune formule e calcoli!
Mục lục
Metodo di selezione delle funzioni
Gli algoritmi di selezione delle funzionalità possono essere suddivisi in tre categorie: metodi di filtro, metodi wrapper e metodi incorporati.
Filtro
Questo ragazzo ha le seguenti caratteristiche:
- Dipende dalle caratteristiche dei dati
- Fornirà prestazioni inferiori rispetto ai metodi wrapper o ai metodi incorporati.
- Metodi: Varianza , Correlazione , Selezione univariata, Selezione multivariata .
Informazioni sulle caratteristiche costanti, quasi costanti, duplicate.
Caratteristiche costanti : visualizza un solo valore per tutte le osservazioni nel set di dati.
Il metodo più semplice per gestire le funzionalità costanti. Imposteremo una soglia (soglia) per la varianza, le caratteristiche che non soddisfano tale soglia verranno scartate. (Può usare sklearn per elaborare)
da sklearn.feature_selection import VarianceThreshold sel = Soglia varianza(soglia=0) # fit trova le caratteristiche con varianza zero. sel.fit(X_treno) # Il metodo get_support() restituisce quali funzionalità vengono mantenute. caratteristiche_ritenute = sel.get_support()
Restituirà una sequenza bool, dobbiamo solo esaminarla per sapere quali caratteristiche non soddisfano la condizione.
Funzionalità quasi costanti : in modo simile alle funzionalità costanti sopra, è solo che possiamo regolare la soglia per rendere la condizione più rigorosa (ad esempio, soglia = 0,01, la funzionalità verrà eliminata quando ha un valore del 99%. allo stesso modo).
Funzionalità duplicate : sono funzionalità simili, ad esempio, una funzionalità originale e un'altra funzionalità è il codificatore di etichette della funzionalità originale, quindi queste due funzionalità sono equivalenti, possiamo eliminare una funzionalità. O più righe identiche.
Metodo:
- Per piccoli set di dati: nei panda c'è una funzione per valutare se un dataframe contiene righe duplicate. Per quanto riguarda il controllo delle colonne, utilizziamo ancora la funzione duplicated(), basta trasporre la matrice.
- Con grande set di dati: se l'utilizzo della trasposizione con dati di grandi dimensioni richiede molto memoria e non è fattibile. Quindi possiamo usare loop per trovare colonne duplicate o usare la libreria numpy.
for_, idx = np.unique(df.to_numpy(), axis=1, return_index=True) df_uniq = df.iloc[:, np.sort(idx)]
Correlazione
L'uso della correlazione tra due o più variabili è anche un buon modo per rimuovere le caratteristiche con una bassa correlazione. La rimozione di caratteristiche altamente correlate aiuta il modello lineare a funzionare meglio, evitando distorsioni tra le caratteristiche.
- Possiamo testare la funzione con un target di correlazione bassa, possiamo eliminare la funzione.
- Oppure controlla la correlazione tra funzionalità e funzionalità se due funzionalità hanno un'elevata correlazione tra loro, forse queste due funzionalità hanno le stesse informazioni e possiamo eliminare 1 funzionalità per ridurre la dimensionalità dei dati di input.
Come determinare il coefficiente di correlazione .
Coefficiente di correlazione di Pearson
sum((x1 -x1.mean) * (x2 - x2.mean) * (xn - xn.mean)) / var(x1) * var(x2) * var(xn)
- Il coefficiente di Pearson ha un valore nell'intervallo [-1,1]
- L'idea è di calcolare la correlazione tra le caratteristiche, se 2 caratteristiche hanno una correlazione maggiore della soglia che ho impostato, eliminerò una di queste 2 caratteristiche.
corrmat = X_train.corr()
# complotto
fig, ax = plt.subplots()
fig.set_size_inches(11,11)
sns.heatmap(corrmat)
def correlazione(df, soglia):
col_corr = set()
corrmat = df.corr()
for i in range(len(corrmat.columns)):
per j nell'intervallo(i):
# interessato ai valori del coefficiente abs
if abs(corrmat.iloc[i, j]) > soglia:
col_corr.add(corrmat.columns[i])
restituisce col_corr
corr_feats = correlazione(X_train, 0.8)
X_train.drop(labels=corr_feats, axis=1, inplace=True)Misure statistiche
Esistono alcuni metodi e criteri per selezionare le caratteristiche in base a metodi statistici come segue:
- Guadagno di informazioni
- ROC-AUC/RMSE univariato
Per ciascuno dei metodi di cui sopra, ci saranno 2 passaggi come segue:
- Valutare le caratteristiche secondo un determinato criterio: ogni caratteristica avrà una valutazione indipendente delle altre caratteristiche quando si considera la sua relazione con l'obiettivo.
- Selezione di fetures di alto rango: possiamo applicare modelli di classificazione o regressione per valutare una caratteristica di alto rango?. E, naturalmente, quanto sapere se la classifica è alta o bassa dipende da te.
Alcuni avvertimenti: possiamo applicare funzionalità duplicate o correlate prima di eseguire questo passaggio. E questo metodo ha anche un grande svantaggio che possono esserci 2 funzionalità combinate insieme, influirà sul target e se applichiamo questo metodo solo a ciascuna funzionalità in termini di tagert, può portare a errori. Pertanto, è necessario applicare più metodi per valutare tra caratteristiche e target.
Informazioni reciproche (guadagno di informazioni)
Questo metodo confronta la probabilità che xey si verifichino simultaneamente attraverso la distribuzione e si combina con il caso in cui le due distribuzioni sono indipendenti.
informazione reciproca = somma{i,y} P(xi, yj) * log(P(xi,yj)/P(xi)*P(yj))Se xey sono indipendenti, l'informazione reciproca sarà 0.
Possiamo usare la libreria di Python per selezionare le funzionalità:
- Utilizzare
sklearn.feature_selection.mutual_info_regressionsul modello di regressione. - E
mutual_info_classifda selezionare con la classificazione del modello.
Eseguire il calcolo reciproco delle informazioni tra variabili e target. Restituisce le informazioni reciproche di ciascuna funzione. Minore è il valore, minori sono le informazioni su quella caratteristica con il target. (Si consiglia la preelaborazione prima di applicare questo metodo).
ROC-AUC/RMSE univariato
L'idea è calcolare il ROC-AUC di ciascuna funzionalità e quindi utilizzare il modello di apprendimento automatico per prevedere l'obiettivo. Qui possiamo utilizzare l'albero decisionale e valutare secondo ROC-AUC o RMSE. Da lì, selezioneremo funzionalità con metriche elevate.
# usa il set di dati bnp-paribas roc_vals = [] per feat in X_train.columns: clf = DecisionTreeClassifier() clf.fit(X_train[feat].fillna(0).to_frame(), y_train) y_scored = clf.predict_proba(X_test[feat].fillna(0).to_frame()) roc_vals.append(roc_auc_score(y_test, y_score[:,1]))
rocvals = pd.Series(roc_vals) rocvals.index = X_train.columns rocvals.sort_values(ascending=False) # numero di funzioni mostra un valore roc-auc superiore a random. len(rocvals[rocvals>0.5])
Riepilogo:
Attraverso questo studio, tu ed io abbiamo appreso alcuni metodi di selezione delle caratteristiche, riducendo il numero di dimensioni di input per rendere più semplice il modello di addestramento.












