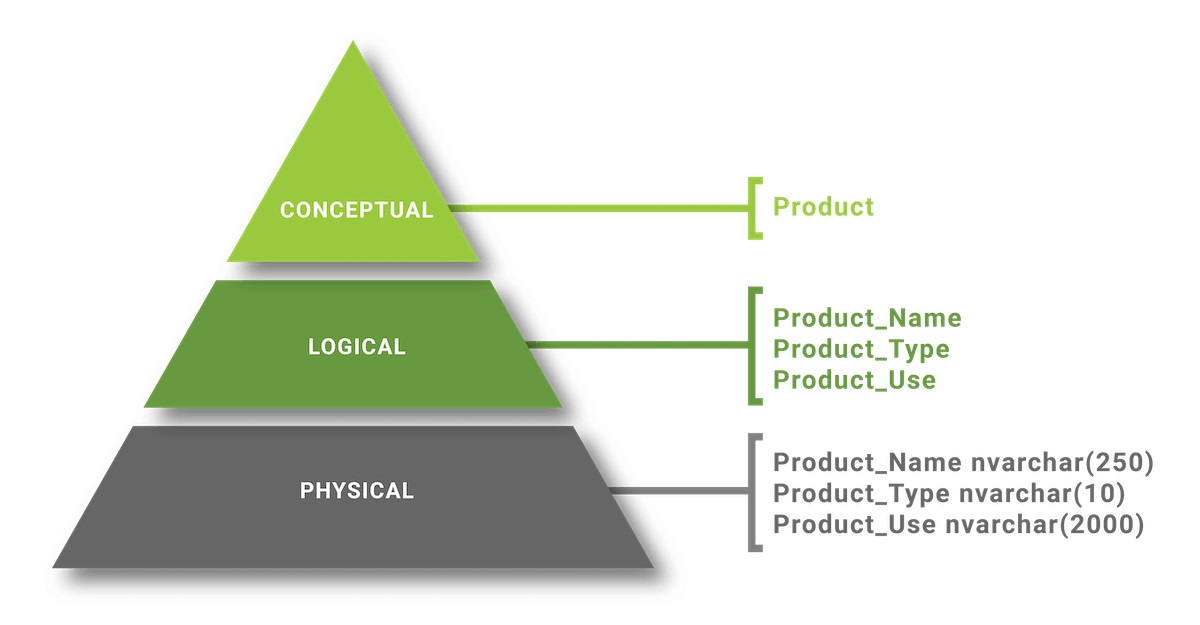
Modello entità-relazionale (modello ER) e normalizzazione dei dati (normalizzazione)
Un modello di dati è un gruppo di strumenti concettuali utilizzati per descrivere i dati, le loro relazioni e i loro significati. Includono anche vincoli di coerenza che i dati dovrebbero seguire. Nel modello Entità – Relazione, la relazione di rete o il modello gerarchico sono tutti esempi di modelli di dati, vedere l'articolo Introduzione ai modelli di database. , introdurre il concetto RDBMS (Sistema di gestione di database correlati) per comprendere meglio. Lo sviluppo di ogni database inizia con i passaggi di base dell'analisi dei dati per trovare il modello di dati più adatto per rappresentare i dati.
Mục lục
Modellazione dei dati
Il processo di applicazione di un modello di dati appropriato ai dati, al fine di organizzarli e strutturarli, è noto come modellazione dei dati .
La modellazione dei dati è essenziale anche per lo sviluppo di database, nonché per la pianificazione e la progettazione di qualsiasi progetto. Costruire un database senza un modello di dati è come sviluppare un progetto senza un piano o un design. Il modello di dati aiuta gli sviluppatori di database a definire le relazioni di tabelle, chiave primaria, chiave esterna , stored procedure , trigger , trigger di eventi) … nel database.
Le fasi di modellazione dei dati sono le seguenti:
- Modellazione concettuale dei dati : i dati sono modellati dalle relazioni nei dati di livello superiore. Lo scopo di questo modello è di organizzare, delimitare e definire concetti, regole e processi aziendali . Una volta creato il modello di dati concettuale, può essere adattato e trasformato in un modello di dati logico.
- Modellazione logica dei dati : i dati modellati descrivono i dati e le loro relazioni in dettaglio. I dati modellati creano modelli logici del database. Lo scopo principale del modello è quello di sviluppare una mappa tecnica delle regole e delle strutture dei dati. Il modello dati logico servirà come base per la creazione di un modello dati fisico.
- Modellazione fisica dei dati : questo modello descrive come verrà implementato il sistema utilizzando un particolare sistema di gestione del database. Questo modello viene spesso creato da amministratori di dati e sviluppatori con lo scopo principale di implementare il database vero e proprio.
Modello Entità-Relazione – Modello ER
I modelli di dati possono essere classificati in 3 diversi gruppi:
- Modello logico basato sugli oggetti
- Modello logico basato sui record
- Modello fisico
I modelli Entity-Relationship (ER) appartengono alla prima categoria: modelli logici basati su oggetti .
Il modello si basa su una semplice idea di contatto con la realtà. I dati possono essere pensati come oggetti del mondo reale chiamati oggetti e le relazioni che esistono tra di loro. Ad esempio, i dati sui dipendenti che lavorano per un'organizzazione possono essere considerati come una raccolta di dipendenti e una raccolta di diversi dipartimenti (dipartimenti) che compongono l'organizzazione. Sia i dipendenti che i reparti sono oggetti del mondo reale. Un impiegato di un dipartimento. Pertanto, una relazione di "appartenenza" associa un dipendente a un determinato dipartimento.

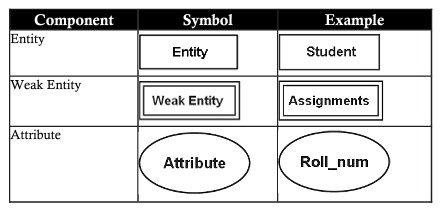
Un modello ER contiene cinque componenti di base come segue:
| Entità (entità) | Un'entità è un oggetto del mondo reale che esiste fisicamente ed è distinguibile da altri oggetti. Ad esempio: il personale, i dipartimenti, gli studenti, i clienti, i conti ….. possono essere chiamati entità |
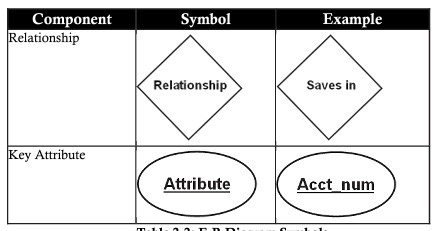
| Relazione (relazione) | Una relazione è un'associazione o un'associazione esistente tra una o più entità. Ad esempio: appartenere, possedere, lavorare, risparmiare, acquistato…. |
| Attributi (attributi) | Un attributo è una caratteristica di un'entità Gli attributi aiutano a distinguere ogni entità da un'altra. Esempio per 2 attributi studente e cliente, la stessa persona ma con attributi diversi quando rappresentati nel database: – L'entità studente ha attributi student_id, nome, età, voto. – Il cliente dell'entità ha attributi customer_id, nome, età, telefono, indirizzo |
| Insieme di entità (insieme di entità) | Un insieme di entità è un elenco (insieme) di oggetti simili. Ad esempio, l'elenco degli studenti in una scuola (secondo uno standard comune con gli stessi attributi) è chiamato insieme di entità studente. |
| Insieme di relazioni | Un elenco (insieme) di relazioni tra due o più insiemi di entità è chiamato insieme di relazioni. Ad esempio, gli studenti studiano molte materie diverse, l'insieme di tutte le relazioni di "apprendimento per soggetto" che esistono tra 2 entità studente e soggetto può essere chiamato insieme di relazioni di "apprendimento". |
Una relazione di associazione tra una o più entità e può avere 3 tipi di relazioni come segue:
Auto-relazioni
La relazione tra un'entità e oggetti simili è chiamata relazione con il sé . Ad esempio, un manager e un membro di un team sono entrambi personale e appartengono allo stesso insieme di entità. I membri del team lavorano per la gestione, quindi esiste una relazione "lavora per" tra 2 diverse entità HR, ma questo personale si trova nello stesso insieme di entità.
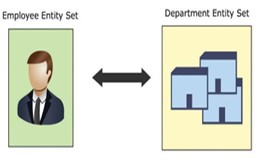
Relazioni binarie
La relazione che esiste tra entità che si trovano in 2 diversi insiemi di entità è chiamata relazione binaria . Ad esempio, un dipendente appartiene a un dipartimento. Esiste una relazione tra due entità situate in due diversi insiemi di entità. L'entità delle risorse umane è nell'insieme di entità (dipendente), l'entità del dipartimento è nell'insieme di entità (dipartimento).
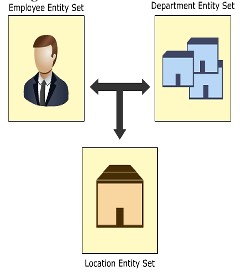
Relazione ternaria (relazione a 3 persone)
Per dirla semplicemente, questa relazione è una relazione di 3 entità partecipanti, che è chiamata relazione ternaria . Ad esempio, un dipendente lavora per il dipartimento finanziario in un determinato ramo dell'organizzazione. Qui ci sono 3 diverse entità: il personale, il dipartimento, la filiale e il personale sarà associato al dipartimento attraverso l'insieme di entità che rappresenta la filiale.
Le relazioni possono anche essere classificate in base alla mappatura delle cardinalità. I diversi tipi di mappatura si distinguono come segue:
Uno a uno (mappatura uno a uno)
Questa mappatura esiste quando l'oggetto di un insieme di entità può essere associato solo a un'istanza di un altro insieme di entità. Ad esempio, il numero di identificazione del cittadino di un cittadino, che si collegherà direttamente e in modo univoco al codice della patente della motocicletta di un cittadino. Non è possibile per un cittadino con un numero di identificazione avere più codici patente per moto. Si chiama luce lontana o relazione uno-a-uno.

Uno a molti (mappatura di uno a molti)
Questo tipo di mappatura viene utilizzato quando un'entità in un insieme di entità è associata a più di un'entità in un altro insieme di entità. Ad esempio, se ci sono molti studenti in una classe, viene spesso utilizzata una mappatura uno-a-molti per rappresentare questa mappatura. Le persone spesso la chiamano relazione 1-a-molti o mappatura 1-a-molti.
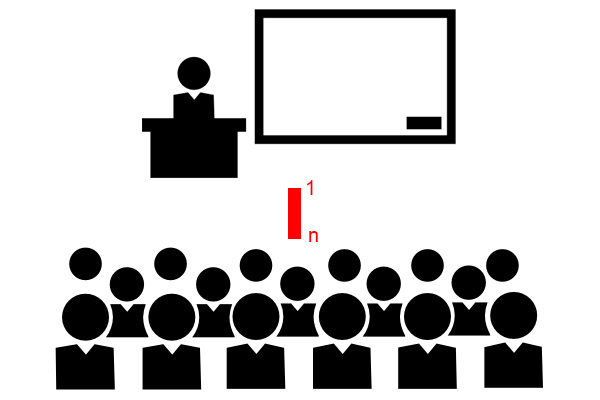
Molti a uno (mappa molti a uno)
Questo tipo di mappatura viene utilizzato quando più entità in un insieme di entità sono associate a un'entità di un altro insieme di entità. Capiamo approssimativamente che questa mappatura è l'opposto di una mappatura uno-a-molti. Ad esempio, una classe ha molti studenti.
Molti-a-molti (mappatura molti a molti)
Questo tipo di mappatura viene utilizzato quando più entità di un insieme di entità sono associate a molte entità di un altro insieme di entità.
Ad esempio, un negozio ha molti prodotti in vendita, l'ordine di ogni cliente al momento dell'acquisto includerà molti prodotti diversi, possiamo vedere che 1 ordine può avere molti prodotti, ma un prodotto appare anche su molti ordini, questo è il miglior esempio di molti mappatura -a-molti.
Inoltre, il modello ER aderisce anche ad alcuni concetti come segue:
Chiave primaria (chiave primaria)
La chiave primaria è un attributo utilizzato per determinare l'unicità di un'entità per un insieme di entità. Nella struttura del database, di solito è sempre consigliabile avere una colonna utilizzata come chiave primaria nella tabella (insieme di entità).
Insiemi di entità deboli
Gli insiemi di entità che non hanno un attributo per definire una chiave primaria sono chiamati insiemi di entità deboli.
Insiemi di entità forti
Gli insiemi di entità che hanno attributi per definire le chiavi primarie sono chiamati insiemi di entità forti.
Diagramma della relazione di entità (Diagramma ER)
Un diagramma ER è una rappresentazione grafica di un modello ER. Nel diagramma ER, utilizzare i simboli per rappresentare efficacemente le diverse componenti del modello ER
Gli attributi nel modello ER possono essere classificati come segue:
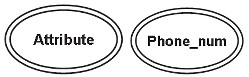
Multivalore (multivalore)
Un attributo multivalore è illustrato da un'ellisse di due righe, che ha più di un valore per almeno un'istanza della sua entità. Questo attributo può avere un limite superiore e un limite inferiore specificati per qualsiasi valore di entità individuale.
Ad esempio, l'attributo phone_number può memorizzare più valori per un'entità. (Una persona può avere più di un numero di telefono)
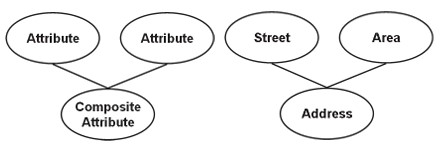
Composito (sintetico)
Uno stesso attributo composito può contenere due o più attributi, i sotto-attributi sono proprietà di base e hanno i propri significati indipendenti.
Ad esempio, l'attributo dell'indirizzo è solitamente un attributo composito, ad esempio, quando si rappresenta un indirizzo aziendale 6/203 Truong Chinh – Thanh Xuan – HN, 6/203 Truong Chinh sarà l'indirizzo, Thanh Xuan lo salverà nel distretto, Hanoi è Città
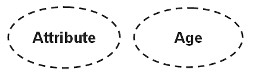
Derivato (attributo derivato)
Le proprietà derivate sono attributi il cui valore dipende completamente da un altro attributo e sono rappresentati da un'ellisse composta da ellissi.
L'attributo età di una persona è il miglior esempio di attributi derivati. Per una particolare entità persona, l'età di una persona può essere determinata dalla data e dalla data di nascita correnti della persona.
I passaggi per strutturare il diagramma ER sono i seguenti:
- Raccogliere tutti i dati che dovevano essere modellati.
- Definisci i dati che possono essere modellati come entità del mondo reale.
- Identificare gli attributi per ciascuna entità.
- Ordina gli insiemi di entità in insiemi di entità deboli o forti.
- Ordina gli attributi dell'entità come attributi chiave, attributi multivalore, attributi compositi, attributi derivati, ecc.
- Identificare le relazioni tra i diversi fattori manipolativi.
- Usando simboli diversi disegna gli elementi di attrazione, le loro proprietà e le loro relazioni. Utilizzare sysbol appropriati durante la stampa delle proprietà.
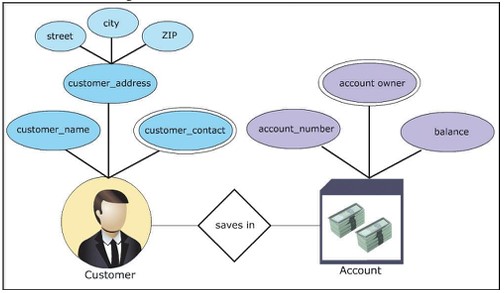
Ad esempio, la creazione di un database che simula una banca, con gestione clienti e account. Il diagramma ER per lo scenario può essere costruito come segue:
- Raccolta dati: questa attività ha bisogno di un elenco di conti e clienti che desiderano depositare denaro.
- Identifica entità: ci sono 2 entità cliente, conto
- Definisci le proprietà:
- Cliente: nome, indirizzo, contatto
- Conto: id,proprietario,saldo
- Ordinamento degli insiemi di entità
- cliente: insieme di entità deboli
- conto: insieme di entità forte
- Ordina le proprietà
- set di entità cliente: indirizzo – composito, contatto – multivalore
- set di entità account: id – chiave primaria, proprietario – multivalore
- Definisci relazione: il cliente deposita denaro sul conto, la relazione sarà "deposito"
- grafico Disegna il modello ER
Normalizzazione (normalizzare i dati)
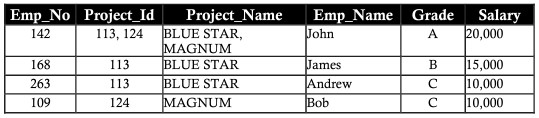
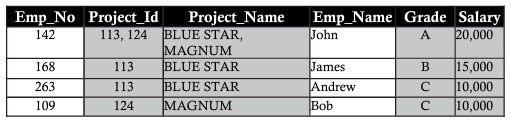
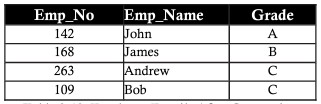
In genere, tutti i database sono identificati da un numero elevato di colonne e record. Questo approccio ha alcune limitazioni. Considera l'esempio seguente in cui due entità vengono salvate nella stessa tabella dei dipendenti nei progetti. Includere i dettagli del dipendente e i dettagli del progetto su cui stanno lavorando:
I concetti dei problemi riscontrati quando i dati non sono normalizzati sono i seguenti:
Anomalia di ripetizione
Colonne come project_id, project_name, stipendio hanno dati in record ripetuti, questa ripetizione ostacola sia le prestazioni di recupero dei dati che la capacità di archiviazione. Questa ripetizione di dati è chiamata anomalia di ripetizione
Anomalia di inserimento
Supponiamo che il nuovo membro del dipartimento sia un nuovo impiegato di nome Ann. Ad Ann non è stato assegnato un progetto in questo momento. Inserisci i suoi dettagli nella tabella con celle vuote su colonne denominate Project_id, Project_name. Lasciare le colonne vuote porta ad alcuni problemi in seguito. L'anomalia creata dall'operazione di inserimento è chiamata anomalia di inserimento.
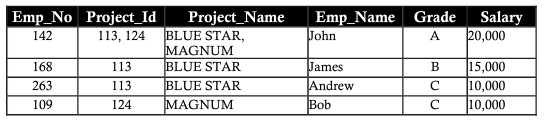
Elimina anomalia (elimina anomalia/anomalia)
Supponiamo che Bob sia tratto dal progetto MAGNUM. Elimina un record di progetto MAGNUM il cui nome del dipendente è Bob, incluso il numero del dipendente (numero_impiegato), grado (grado) e stipendio (stipendio). La perdita di dati influisce sui dettagli delle informazioni personali di Bob, questa perdita può essere vista nella tabella seguente. I dati persi a causa della cancellazione di cui sopra sono chiamati anomalia di cancellazione.

Anomalia di aggiornamento
Supponiamo che a John sia stato concesso un aumento o una riduzione dello stipendio. Le modifiche allo stipendio o al grado di John devono riflettersi in tutti i progetti su cui John lavora. Questo è chiamato aggiornamento anomalia.
La tabella che dettaglia i dipendenti del dipartimento è chiamata tabella non normalizzata. Queste limitazioni suggeriscono che la normalizzazione è necessaria.
La nomarlizzazione è un processo di rimozione di ridondanze e dipendenze indesiderate. Inizialmente, Codd (1972) descrisse tre forme di normalizzazione (1NF, 2NF e 3NF), tutte basate sulle dipendenze tra gli attributi della relazione. La quarta forma normale (4NF) e la quinta forma normale (5NF) si basano su associazioni multivalore e dipendenti e sono state introdotte successivamente.
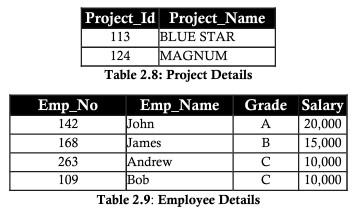
Prima forma normale (1NF)
I passaggi per completare 1NF sono i seguenti:
- Crea tabelle separate per ogni gruppo di dati correlati
- Le colonne della tabella devono memorizzare i valori primi (può comprendere i valori primitivi)
- Tutti gli attributi della chiave primaria devono essere definiti
Considerando l'esempio della tabella sopra, dobbiamo normalizzare la tabella dividendo chiaramente le due entità progetto e dipendente
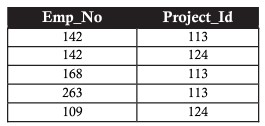
Seconda forma normale (2NF)
Le tabelle sono chiamate 2NF se sono soddisfatti i seguenti requisiti:
- Soddisfare i requisiti di 1NF
- non ci sono dipendenze nelle tabelle
- Le tabelle sono collegate tra loro tramite chiavi esterne.
Considerando l'esempio sopra, utilizziamo 2NF per collegare la tabella del progetto e la tabella del dipendente (per sapere a quale dipendente è assegnato il progetto) attraverso una tabella intermedia.
Terza forma normale (3NF)
Per completare la normalizzazione 3NF, devono essere soddisfatti i seguenti requisiti:
- La tabella dovrebbe soddisfare i requisiti di 2NF
- le tabelle non dovrebbero avere colonne dipendenti al loro interno
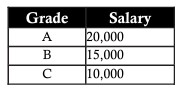
Continuando l'esempio sopra, nella tabella dei dipendenti, vediamo che la colonna Stipendio dipende dalla colonna Grado secondo la formula generale: A – 20.000 | B – 15.000 | C – 10.000. Quindi, per normalizzare questi dati, divideremo la tabella dei dipendenti, che memorizza solo il voto, e una tabella che mostra il voto e lo stipendio. Quando lo fai, puoi in seguito aggiungere e aggiornare i voti per soddisfare facilmente le tue esigenze senza influire sui dati complessivi.

Denormalizzazione
Normalizzando i dati, i dati ridondanti vengono ridotti al minimo. Ciò significa che la dimensione dello spazio di archiviazione del database richiesto nel database verrà ridotta. Tuttavia, hanno anche alcune limitazioni come segue:
- Le istruzioni di query diventeranno più complesse quando si connettono i dati tra tabelle diverse
- Infatti, l'istruzione di query può coinvolgere più di 3 tabelle a seconda delle esigenze informative (aumento della complessità nella scrittura di istruzioni di query, programmatori y/c o DBA altamente specializzati)
Se le istruzioni della query di join vengono utilizzate troppo spesso, le prestazioni del database diminuiranno, il tempo di elaborazione della CPU aumenterà, influenzando la velocità del programma. Pertanto, in alcuni casi, i dati ridondanti possono ancora essere utilizzati per aumentare le prestazioni del database, il che significa accettare l'archiviazione dei dati ridondante (sacrificando la capacità di archiviazione per aumentare le prestazioni).query), chiamata denormalizzazione (denormalizzazione dei dati)
Operatori relazionali
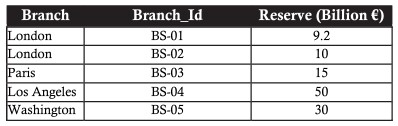
Il modello relazionale si basa su solide basi di algebra relazionale. L'algebra relazionale consiste in un insieme di operatori che operano sulle relazioni. Ogni operatore prende una o due relazioni come input e crea una nuova relazione come output. Si consideri la tabella di dati bancari di esempio con le seguenti filiali:
SELEZIONA (selezione)
L'operatore SELECT viene utilizzato per recuperare i dati che soddisfano le condizioni richieste. Il carattere sigmoideo (ð) viene utilizzato per rappresentare una selezione.
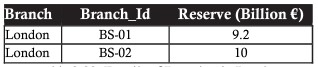
L'esempio seguente è una tabella quando si selezionano i record con una filiale a Londra
O un'operazione che richiede l'apertura di filiali con rovesci superiori a 20 miliardi di euro

PROGETTO (proiezione)
L'operatore PROGETTO viene utilizzato per fare riferimento ai dettagli di una tabella relazionale. L'operatore PPROJECT visualizza solo i campi obbligatori e omette i campi non obbligatori nella colonna. L'operatore PROGETTO è rappresentato dal carattere pi “π”.
L'esempio seguente utilizza l'operatore PROJECT per ottenere l'id e il reverse per un'azienda senza ottenere il nome della filiale:
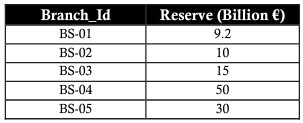
PRODOTTO (moltiplicazione/prodotto)
L'operatore PRODOTTO viene utilizzato per combinare superficialmente le informazioni di due tabelle correlate, rappresentate dal carattere "x".
Ad esempio, abbiamo una tabella dei prestiti come questa:

Utilizza l'operatore PRODOTTO utilizzato per combinare le tabelle filiale e prestito per rappresentare il totale delle riserve e il totale dei prestiti:
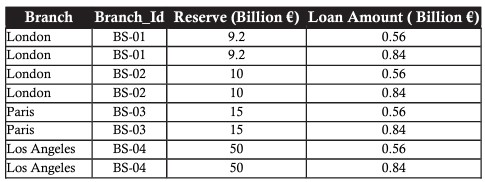
La moltiplicazione combina ogni record della prima tabella con tutti i record della seconda tabella, in altre parole crea tutte le possibili combinazioni tra i record delle due tabelle.
UNIONE (associazione)
Diciamo che, visti i dati di esempio della banca sopra riportati, il management voglia aprire filiali che hanno riserve o prestiti inferiori ai 20 miliardi di euro. La tabella risultante dovrebbe contenere sportelli con riserve o prestiti inferiori a 20 miliardi di euro, o entrambe le colonne che soddisfano i criteri.
Questa visualizzazione è la combinazione tra due set di dati, i passaggi a loro volta sono i seguenti:
- Raccolta di sportelli con riserve inferiori a 20 miliardi di euro
- Insieme di filiali con prestiti sotto i 20 miliardi di euro
- Unisci i 2 set, assicurandoti che la filiale con le stesse riserve e prestiti inferiori a 20 miliardi di euro appaia solo una volta
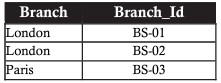
INTERSEZIONE (Intersezione)
Supponiamo di voler sapere quale di questi rami ha sia riserve basse che prestiti bassi. La soluzione sarebbe utilizzare l'operatore INTERSECT di intersezione. L'operatore INTERSECT produce i dati corretti in tutte le tabelle a cui è applicato. Si basa sulla teoria degli insiemi di intersezione ed è rappresentato dal simbolo " " . Il risultato sarà l'intersezione di due tabelle che includono l'elenco delle filiali che soddisfano sia il criterio della riserva che quello del prestito con meno di 20 miliardi di euro.

DIFFERENZA (miracolosa)
Tornando all'esempio sopra, se vogliamo sapere quale filiale ha riserve basse ma nessun prestito, la soluzione è utilizzare il (DIFFERENZA). La notazione è indicata dal carattere "-", il suo output è ancora un'unione da 2 tabelle diverse, ma la differenza è che recupera solo il valore corretto di una tabella, non dell'altra, quindi le filiali con riserve basse ma senza prestiti lo faranno non essere portato fuori.

GIUNTURA
La concatenazione è un'estensione della moltiplicazione che consente di selezionare il risultato della moltiplicazione. Ad esempio, se le riserve e i prestiti delle filiali sono inferiori con il PRODOTTO di cui sopra, i dati saranno ridondanti e dovranno essere aggregati e ridotti. L'output della JOIN restituirà solo le filiali di nuova quotazione che hanno sia riserve inferiori a 20 miliardi di euro che capitale di prestito.

DIVIDE (divisione/quoziente)
Supponiamo di voler nuovamente vedere il ramo tene e le riserve di tutti i rami che hanno prestiti. Questa situazione deve utilizzare l'autorizzazione DIVIDE per la gestione. Tutto ciò che serve è dividere la tabella Branch Reverse Details (2.19) per l'elenco di branch e la colonna Branch_id della tabella BranchLoanDetails (2.23). Il risultato è come mostrato di seguito

Nota: le proprietà della tabella di divisione devono essere sempre un sottoinsieme della tabella di divisione. La tabella risultante lascia sempre vuote le proprietà della tabella divisa e i record non corrispondono ai record nella tabella divisa.












