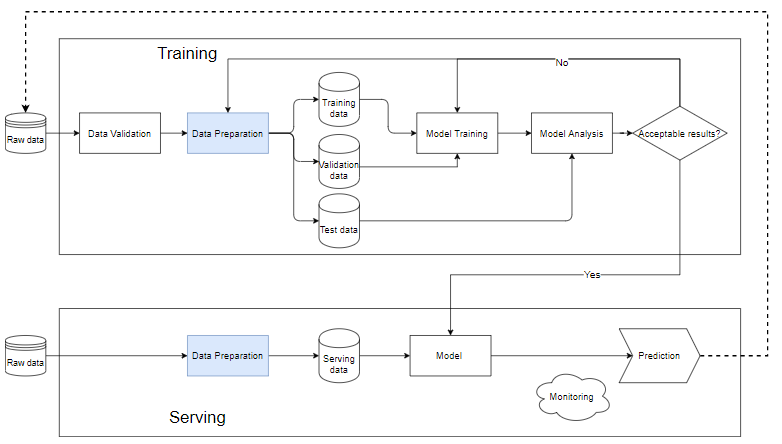
Pipeline nell'apprendimento automatico
Pipeline in ML è un modo per automatizzare il flusso di lavoro per la creazione di un modello di machine learning. Quasi tutti i sistemi di Machine Learning hanno componenti come il diagramma seguente, è una pipeline di machine learning.
Mục lục
Che cos'è una pipeline nell'apprendimento automatico?
Blocco di formazione
- Convalida dei dati: è la fase di test dei dati, che determina se i dati appena aggiunti sono soddisfatti dei dati nel database. Per questo motivo verranno sempre aggiunti nuovi dati per eseguire il treno.
- Dopo che i dati grezzi sono stati ripuliti nella fase di preparazione dei dati, vengono quindi suddivisi in un set di dati di addestramento, un set di dati di addestramento e un set di dati di convalida, per determinare la qualità del modello dopo il processo di addestramento.
- I dati di addestramento vengono inseriti nel blocco "addestramento del modello" per addestrare il modello.
- Dopo la formazione, eseguiamo l'analisi nel blocco "analisi del modello" per analizzare la qualità. Controlla se le metriche sul set di test sono buone, i risultati previsti e i risultati effettivi sono equivalenti, la velocità di previsione,…
- Quando i dati vengono passati attraverso il blocco di analisi del modello, il modello verrà utilizzato per eseguire i dati effettivi nella fase "Elaborazione". Altrimenti dobbiamo rivedere il modello o filtrare i dati.
Blocco di servizio
- Quando il modello è ancora stub, dovremmo utilizzare un piccolo set di dati, eseguire il test, se la qualità è accettabile, possiamo farlo su tutti i dati.
- La preparazione dei dati aiuta a pulire e creare i dati che dovranno essere gli stessi del modello nel blocco di addestramento.
- Ogni diverso problema richiede un diverso sistema di monitoraggio e avviso. Di solito, indipendentemente dai dati di input, il modello produrrà comunque un risultato prevedibile, possibilmente casuale. Se questi risultati non vengono monitorati e allarmati con attenzione, portando a improvvisi cambiamenti nella qualità del modello e nelle reazioni degli utenti, la reputazione e le entrate dell'azienda ne risentiranno seriamente.
Perché costruire pipeline?
- I sistemi di apprendimento automatico sono spesso costituiti da molti piccoli componenti come elaborazione dati, training del modello, valutazione del modello, previsione con nuovi dati, ecc. Senza costruire una pipeline completa con ogni componente separato Ovviamente, ci saranno molti problemi. Separare il sistema passo dopo passo e rimontarlo in una pipeline semplifica la ricerca di errori durante il training del modello.
- Costruire una pipeline ci aiuta anche a lavorare insieme meglio come una squadra. Se c'è un gruppo numeroso, possiamo dividerlo in piccoli gruppi: un gruppo è specializzato nella pulizia dei dati, un gruppo è specializzato nella creazione di funzionalità, un altro gruppo costruisce e addestra il modello e un altro gruppo si concentra sulla valutazione e monitora l'attività del modello. Questi blocchi di lavoro, se separati e specializzati, aiuteranno i team ad approfondire per migliorare la qualità di ogni blocco senza preoccuparsi di violare il codice dell'altro team.
Esempio semplice
Qui introdurrò una pipeline completa, non entrerò in ciascuna riga di comando, ma voglio usare questo esempio per darti una panoramica di una pipeline. Puoi vedere il codice completo qui
Il primo passo è importare le librerie necessarie.
from pathlib import Path import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.ensemble import RandomForestClassifier from sklearn.impute import KNNImputer, SimpleImputer from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.pipeline import Pipeline from sklearn.preprocessing import OneHotEncoder, RobustScalerCaricare dati
titanic_path = ( "https://github.com/CongSon01/titanic_pipeline/" ) df_train_full = pd.read_csv(titanic_path + "train.csv") df_test = pd.read_csv(titanic_path + "test.csv")
Elimina i dati mancanti, non porta efficienza al modello.
df_train_full.drop(columns=["Cabin"]) df_test.drop(columns=["Cabin"]);Prima di passare alla fase di creazione delle funzionalità, è necessario dividere i dati di addestramento/test. Qui, il 10% casuale dei dati etichettati originali viene estratto come dati di convalida , il restante 90% viene mantenuto come dati di addestramento . La colonna Sopravvissuta è la colonna dell'etichetta suddivisa in una variabile separata contenente l'etichetta:
df_train, df_val = train_test_split(df_train_full, test_size=0.1) X_train = df_train.copy() y_train = X_train.pop("Survived") X_val = df_val.copy() y_val = X_val.pop("Survived")Le funzionalità di elaborazione con tipi di dati categoriali o numerici avranno metodi di elaborazione diversi. Per prima cosa ci occupiamo di dati categoriali.
cat_cols = ["Embarked", "Sex", "Pclass"] cat_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="most_frequent")), ("onehot", OneHotEncoder(handle_unknown="ignore", sparse= False )), ] )Successivamente applichiamo num_transformer a due caratteristiche numeriche:
num_cols = ["Age", "Fare"] num_transformer = Pipeline( steps=[("imputer", KNNImputer(n_neighbors=5)), ("scaler", RobustScaler())] )Combinando due processori otteniamo un processore completo. La classe ColumnTransformer di scikit-learn aiuta a combinare i trasformatori:
preprocessor = ColumnTransformer( transformers=[ ("num", num_transformer, num_cols), ("cat", cat_transformer, cat_cols), ] )Infine, combiniamo il processore specifico del preprocessore con un semplice classificatore che viene spesso utilizzato con i dati tabulari, RandomForestClassifier, per ottenere una pipeline full_pp che includa sia l'elaborazione dei dati che i modelli. Full_pp viene adattato ai dati di addestramento (X_train, y_train) quindi utilizzato per l'applicazione ai dati di test.
# Full training pipeline full_pp = Pipeline( steps=[("preprocessor", preprocessor), ("classifier", RandomForestClassifier())] ) # training full_pp.fit(X_train, y_train) # training metric y_train_pred = full_pp.predict(X_train) print( f"Accuracy score on train data: { accuracy_score(list(y_train), list(y_train_pred)) : .2f } " ) # validation metric y_pred = full_pp.predict(X_val) print( f"Accuracy score on validation data: { accuracy_score(list(y_val), list(y_pred)) : .2f } " )Punteggio di precisione sui dati del treno: 0,98 Punteggio di precisione sui dati di convalida: 0,83
Pertanto, l'intero sistema fornisce una precisione del 98% sul set di addestramento e dell'83% sul set di test. Questa differenza dimostra che si è verificato un overfitting (ne parlerò nei seguenti articoli).












