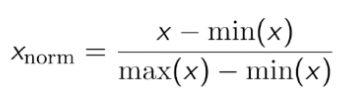Preelaborazione dei dati in Machine Learning, esempio concreto.
La pre-elaborazione dei dati è un passaggio indispensabile nel Machline Learning perché, come sai, i dati sono una parte molto importante, che influisce direttamente sul Modello di Formazione. Pertanto, è molto importante preelaborare i dati prima di inserirli nel modello, aiutando a rimuovere o compensare i dati mancanti.
In questo articolo ti aiuterò a capire come vengono elaborati i dati prima di entrare nel modello attraverso un esempio specifico, non solo la teoria a secco.
Il primo è sicuramente un set di dati su cui esercitarti.
Mục lục
Prepara i dati.
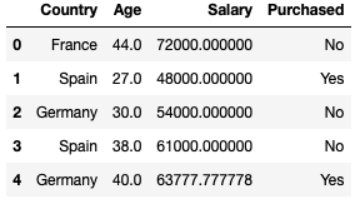
È possibile ottenere i dati seguendo il collegamento sottostante. Quindi semplicemente si tratta di dati composti da 10 righe e 4 colonne, in seguito capirai perché ho scelto i dati di 10 righe da eseguire. Dati statistici sul comportamento di acquisto di auto di un certo numero di persone in tutti i paesi, con età e stipendi diversi. Ci sono anche alcuni dati persi.
dataset = pd.read_csv("data.csv") Country Age Salary Purchased 0 France 44.0 72000.0 No 1 Spain 27.0 48000.0 Yes 2 Germany 30.0 54000.0 No 3 Spain 38.0 61000.0 No 4 Germany 40.0 NaN Yes 5 France 35.0 58000.0 Yes 6 Spain NaN 52000.0 No 7 France 48.0 79000.0 Yes 8 Germany 50.0 83000.0 No 9 France 37.0 67000.0 YesSeparazione dei dati
Gestione delle funzioni .iloc[] in pandas.core per suddividere i dati, determinare quali sono le funzionalità e cosa viene prodotto.
Esempio: X = dataset.iloc[:3, :-1] // taglia dalle prime 3 righe e rilascia l'ultima colonna.
Stipendio dell'età del paese
0 France 44.0 72000.0 1 Spain 27.0 48000.0 2 Germany 30.0 54000.0 E per elaborare i dati, devi convertire in array numpy con la funzione X = dataset.iloc[:3, :-1].values.
Preelaborazione dei dati
Ecco alcuni dei concetti che ho utilizzato in questo articolo:
- Gestione dei dati mancanti
- Standardizzazione (distribuzione standard)
- Gestione delle variabili catogiche
- Codifica one-hot
- Multicollinearità
1. Gestione dei dati mancanti
Su qualsiasi tipo di set di dati nel mondo ci sono pochi valori nulli. Non va davvero bene quando vuoi usare modelli come la regressione o la classificazione o qualsiasi altro modello. Nota: in Python, NULL è rappresentato anche da NAN. Pertanto possono essere usati in modo intercambiabile .
Puoi implementare il tuo codice scorrendo gli elementi di ciascuna colonna per vedere quale colonna ha l'equivalente di isnull() e process.
In questo esempio ti mostrerò come utilizzare la libreria Sklearn per aiutarti a gestire facilmente i dati mancanti. SimpleImputer è una classe di Sklearn che supporta la gestione dei dati mancanti che sono numerici e li sostituisce con una media della colonna, la frequenza dei dati più visibili,…
from sklearn.impute import SimpleImputer #Create an instance of Class SimpleImputer: np.nan is the empty value in the dataset imputer = SimpleImputer(missing_values=np.nan, strategy='mean') #Replace missing value from numerical Col 1 'Age', Col 2 'Salary' imputer.fit(X[:, 1:3]) #transform will replace & return the new updated columns X[:, 1:3] = imputer.transform(X[:, 1:3])
2. Trattamento dei dati categoriali
Codifica variabili indipendenti : ci aiuta a convertire una colonna contenente stringhe nel vettore 0 e 1
- Utilizzo della classe ColumnTransformer di sklearn e OneHotEncoder.
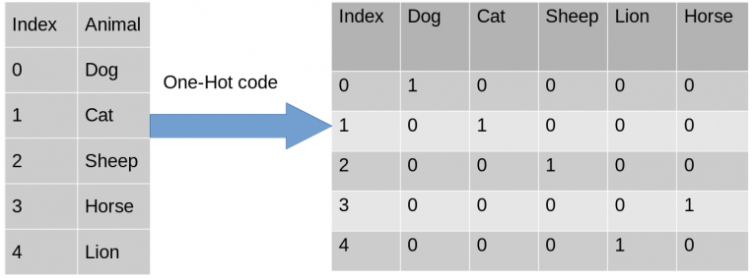
from sklearn.compose import ColumnTransformer from sklearn.preprocessing import OneHotEncoderCrea una tupla (trasformazione di codifica 'encoder', istanza della classe OneHotEncoder, [cols vuole trasformare) e altri cols con cui non vuoi fare nulla, puoi usare rester="passthrough" per saltarli.
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [0])] , resto = "passthrough" )Adatta e trasforma con input = X e ct istanza della classe ColumnTransformer
#adatta e trasforma con input = X #np.array: è necessario convertire l'output di fit_transform() da matrice a np.array X = np.array(ct.fit_transform(X))
Dopo la conversione otteniamo France = [1.0,0.0,0.0] che è già one-hot.
Codifica variabili dipendenti : Cioè, dobbiamo codificare le etichette di output per far capire alla macchina.
- Utilizzare Label Encoder per codificare le etichette
da sklearn.preprocessing import LabelEncoder le = codificatore di etichette() #output di fit_transform di Label Encoder è già un Numpy Array y = le.fit_transform(y) #y = [0 1 0 0 1 1 0 1 0 1]
Set di allenamento per scissione e set di prova
- Usa train_test_split di Sklearn-Model Selection per suddividere i dati del treno e del test.
- Utilizzare il parametro: test_size=… per dividere i dati del set di test su tutti i dati.
- random_state = 1: aiuta a usare il set casuale integrato di Python.
da sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 1)
Ridimensionamento delle funzioni
Perché si verifica FS: quando eseguiamo il data mining, potrebbero esserci alcune funzionalità più grandi di altre, quindi le funzionalità più piccole verranno sicuramente ignorate quando eseguiamo ML Model.
# Nota 1: FS non deve essere applicato ai modelli multi-regressione perché quando y prevede = b0 + b1*x1 + b2*x2 + … + bn*xn allora (b0, b1, …, bn) ) sono coefficienti per compensare la differenza, quindi non è necessario alcun FS.
# Nota 2: per la codifica delle caratteristiche categoriali, non è necessario applicare FS.

#Nota3: le FS devono essere eseguite dopo aver diviso i set di addestramento e di test. Perché se utilizziamo FS prima di dividere i set di training e test, i dati perderanno la loro correttezza.
Quindi, come applicare il ridimensionamento delle funzionalità .
Ci sono due tecniche per farlo:
- Standardizzazione: trasforma i dati in modo che la media sia 0 e la deviazione standard sia 1.
Su questi dati puoi vedere che l'età e lo stipendio sono abbastanza diversi, quindi i dati sull'età potrebbero non essere utilizzati nel modello. Pertanto, è necessario normalizzare i dati per ridurli a un numero inferiore e garantire comunque la correlazione dei dati.
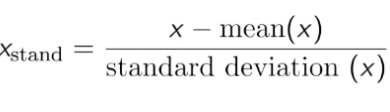
È possibile utilizzare StandardScaler di sklearn.preprocessing su Std per i dati.
da sklearn.preprocessing import StandardScaler sc = StandardScaler() X_treno[:,3:] = sc.fit_transform(X_treno[:,3:]) #usa solo Trasforma per usare lo STESSO scaler del Training Set X_test[:,3:] = sc.transform(X_test[:,3:])
- Normalizzazione: fa oscillare il set di dati tra 0 e 1.