
Usa la convalida K-fold per valutare il modello in modo più efficace.
Il modello di addestramento non dipende solo dal modello utilizzato, ma coinvolge anche molte altre cose, inclusa la quantità di dati. Un set di dati modesto porterà inevitabilmente a una valutazione del modello inefficiente. Quindi la convalida incrociata K-fold è un trucco piuttosto interessante per aiutarci a gestirlo.
Mục lục
E se valutiamo il modello con pochi dati?
Sicuramente tutti hanno familiarità con come dividere i dati di treno, convalida e test, giusto?
Per ora, devi solo preoccuparti del set di addestramento e del set di valori, e il set di test ci consentirà di valutare il modello al termine dell'addestramento per vedere come il modello gestirà i dati nella pratica.
Di solito vedrai che spesso dividiamo treno / val nel rapporto di 80/20 (80% dei dati del treno, 20% dei dati del test). Tale divisione è abbastanza buona quando i nostri dati sono grandi. Per quanto riguarda i piccoli dati, sicuramente renderà il tuo modello scadente. Poiché alcuni dei dati utili per il processo di addestramento sono stati lanciati da noi per la convalida e il test, il modello non può apprendere da quei dati. Per non parlare del fatto che non è garantito che i nostri dati siano casuali, alcune etichette sono presenti nella convalida e nel test ma non nel set di addestramento. E, naturalmente, valutare il modello sulla base di quel risultato non va bene. È come se non avesse studiato matematica ma gli avesse fatto imparare l'apprendimento automatico.
Quindi abbiamo bisogno della convalida incrociata K-Fold.
Che cos'è la convalida incrociata K?
K-Flod CV ci aiuterà a valutare un modello in modo più completo e accurato quando il nostro set di allenamento non è ampio.
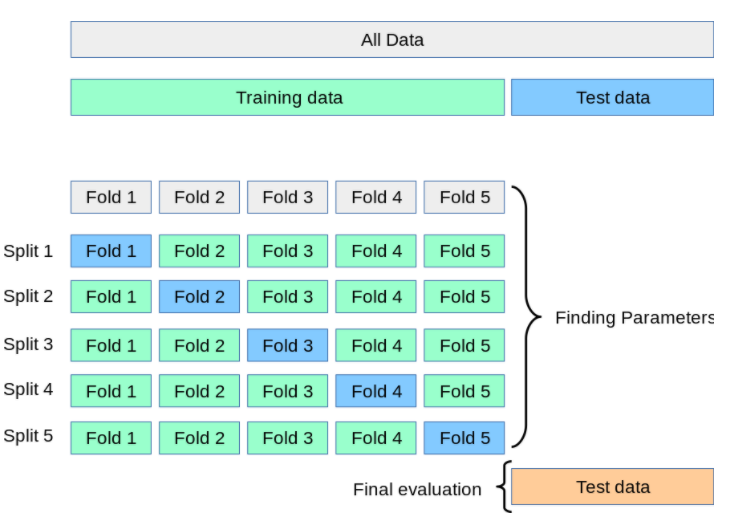
La parte dei dati di addestramento sarà suddivisa in K parti (K è un numero intero spesso troppo difficile da scegliere 10). Quindi addestra il modello K volte, ogni volta che il treno sceglierà 1 parte come dati di convalida e la sottoparte K-1 sarà il set di addestramento. Il risultato finale sarà la media dei risultati della valutazione dei tempi di allenamento K. Anche per questo motivo questa valutazione è più obiettiva.
Dopo che la valutazione è completa e trovi l'accuratezza a un livello "accettabile", procedi alla previsione solo con il set di dati del test.
Esercitati con Keras
Ok teoria di base fatta. Ora per esercitarsi! Usiamo sempre il set di dati CIFAR10 in keras per esercitarci.
Importa librerie.
from tensorflow.keras.datasets
import cifar10
from tensorflow.keras.models
import Sequential from tensorflow.keras.layers
import Dense, Flatten, Conv2D, MaxPooling2D from sklearn.model_selection
import KFold import numpy as np
Scrivi una funzione per caricare i dati:
def load_data():
# Load dữ liệu CIFAR đã được tích hợp sẵn trong Keras
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# Chuẩn hoá dữ liệu
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_test = X_test / 255
X_train = X_train / 255 # Do CIFAR đã chia sẵn train và test nên ta nối lại để chia K-Fold
X = np.concatenate((X_train, X_test), axis=0)
y = np.concatenate((y_train, y_test), axis=0)
return X, y
Costruisci modelli in Keras
def get_model():
model = Sequential()
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(no_classes, activation='softmax')) # Compile model
model.compile(loss="sparse_categorical_crossentropy", optimizer="Adam", metrics=['accuracy'])
return model
Usiamo anche la libreria KFold di Sklearn per condividere
kfold = KFold(n_splits=num_folds, shuffle= True )
# K-fold Cross Validation model evaluation
fold_idx = 1
for train_ids, val_ids in kfold.split(X, y):
model = get_model()
print ("Bắt đầu train Fold ", fold_idx)
# Train model
model.fit(X[train_ids], y[train_ids], batch_size=batch_size, epochs=no_epochs, verbose=1) # Test và in kết quả
scores = model.evaluate(X[val_ids], y[val_ids], verbose=0) print ("Đã train xong Fold ", fold_idx) # Thêm thông tin
accuracy và loss vào list accuracy_list.append(scores[1] * 100) loss_list.append(scores[0]) # Sang Fold tiếp theo
fold_idx = fold_idx + 1
L'idea è che useremo KFold per ottenere l'indice del treno impostato e l'indice val impostato ad ogni piega, quindi estrarremo gli elementi in base a quell'insieme di indice in treno, val per essere più adatto. I risultati di precisione e perdita verranno salvati nell'elenco per visualizzare la media.
riepilogo
Invece di valutare il modello faccia a faccia con il set di treni e val set, siamo stati in grado di valutare il modello in modo più efficiente con il K-Fold CV. Oltre a K-Fold CV puoi provare K-Fold stratificato, questo è meglio perché è un'estensione di K-Fold CV.












