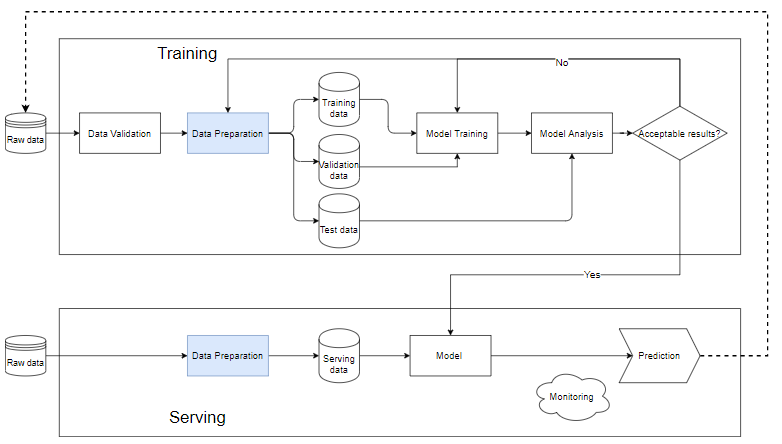
機械学習のパイプライン
MLのパイプラインは、機械学習モデルを作成するワークフローを自動化する方法です。ほとんどすべての機械学習システムには、下の図のようなコンポーネントがあり、機械学習パイプラインです。
Mục lục
機械学習のパイプラインとは何ですか?
トレーニングブロック
- データ検証:データをテストし、新しく追加されたデータがデータベース内のデータに満足しているかどうかを判断するステップです。そのため、trainを実行するために常に新しいデータが追加されます。
- 生データがデータ準備ステップにクリーンアップされた後、トレーニングデータセット、トレーニングデータセット、検証データセットに分割されます。テストデータは、トレーニングプロセス後のモデルの品質を決定します。
- トレーニングデータは、モデルをトレーニングするために「モデルトレーニング」ブロックに入れられます。
- トレーニング後、「モデル分析」ブロックで分析を行い、品質を分析します。テストセットのメトリックが良好であるかどうか、予測結果と実際の結果が同等であるかどうか、予測速度などを確認します。
- データがモデル分析ブロックを通過すると、モデルは「提供」ステップで実際のデータを実行するために使用されます。それ以外の場合は、モデルを確認するか、データをフィルタリングする必要があります。
サービング。ブロック
- モデルがまだスタブである場合は、小さなデータセットを使用してテストを実行する必要があります。品質が許容範囲内であれば、データ全体に対して実行できます。
- データ準備は、トレーニングブロックのモデルと同じである必要があるデータをクリーンアップして作成するのに役立ちます。
- 異なる問題ごとに、異なる監視および警告システムが必要です。通常、入力データに関係なく、モデルは予測可能な、場合によってはランダムな結果を生成します。これらの結果を注意深く監視および警告しないと、モデルの品質とユーザーの反応が突然変化し、会社の評判と収益に影響が及びます。深刻です。
なぜパイプラインを構築するのですか?
- 機械学習システムは、多くの場合、データ処理、モデルトレーニング、モデル評価、新しいデータによる予測など、多くの小さなコンポーネントで構成されます。各コンポーネントを個別に使用して完全なパイプラインを構築しないと、明らかに多くの問題が発生します。システムを段階的に分離し、パイプラインに戻すことで、モデルのトレーニング時にエラーを見つけやすくなります。
- パイプラインを構築することは、チームとしてよりよく協力するのにも役立ちます。大きなグループがある場合は、小さなグループに分けることができます。1つのグループはデータクリーニングを専門とし、1つのグループはフィーチャの作成を専門とし、別のグループはモデルの構築とトレーニングを専門とし、別のグループは評価に焦点を合わせます。モデル。これらの作業ブロックは、分離されて専門化されている場合、他のチームのコードを壊すことを心配することなく、チームがドリルダウンして各ブロックの品質を向上させるのに役立ちます。
簡単な例
ここでは完全なパイプラインを紹介します。各コマンドラインには触れませんが、この例を使用してパイプラインの概要を説明します。あなたは ここで完全なコードを見ることができます
最初のステップは、必要なライブラリをインポートすることです。
from pathlib import Path import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.ensemble import RandomForestClassifier from sklearn.impute import KNNImputer, SimpleImputer from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.pipeline import Pipeline from sklearn.preprocessing import OneHotEncoder, RobustScalerデータを読み込む
titanic_path = ( "https://github.com/CongSon01/titanic_pipeline/" ) df_train_full = pd.read_csv(titanic_path + "train.csv") df_test = pd.read_csv(titanic_path + "test.csv")
欠落しているデータを削除します。モデルに効率をもたらしません。
df_train_full.drop(columns=["Cabin"]) df_test.drop(columns=["Cabin"]);機能構築のステップに入る前に、トレーニング/テストデータを分割する必要があります。ここでは、元のラベル付きデータのランダムな10%が検証データとして抽出され、残りの90%がトレーニングデータとして保持されます。 Survived列は、ラベルを含む別の変数に分割されるラベル列です。
df_train, df_val = train_test_split(df_train_full, test_size=0.1) X_train = df_train.copy() y_train = X_train.pop("Survived") X_val = df_val.copy() y_val = X_val.pop("Survived")カテゴリデータ型または数値データ型の処理機能には、さまざまな処理方法があります。まず、カテゴリデータを扱います。
cat_cols = ["Embarked", "Sex", "Pclass"] cat_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="most_frequent")), ("onehot", OneHotEncoder(handle_unknown="ignore", sparse= False )), ] )次に、num_transformerを2つの数値機能に適用します。
num_cols = ["Age", "Fare"] num_transformer = Pipeline( steps=[("imputer", KNNImputer(n_neighbors=5)), ("scaler", RobustScaler())] )2つのプロセッサを組み合わせると、完全なプロセッサが得られます。 scikit-learn ColumnTransformerクラスは、トランスフォーマーを組み合わせるのに役立ちます。
preprocessor = ColumnTransformer( transformers=[ ("num", num_transformer, num_cols), ("cat", cat_transformer, cat_cols), ] )最後に、プリプロセッサ固有のプロセッサを、表形式のデータでよく使用される単純な分類子であるRandomForestClassifierと組み合わせて、データ処理とモデルの両方を含むfull_ppパイプラインを取得します。 Full_ppはトレーニングデータ(X_train、y_train)に適合され、テストデータに適用するために使用されます。
# Full training pipeline full_pp = Pipeline( steps=[("preprocessor", preprocessor), ("classifier", RandomForestClassifier())] ) # training full_pp.fit(X_train, y_train) # training metric y_train_pred = full_pp.predict(X_train) print( f"Accuracy score on train data: { accuracy_score(list(y_train), list(y_train_pred)) : .2f } " ) # validation metric y_pred = full_pp.predict(X_val) print( f"Accuracy score on validation data: { accuracy_score(list(y_val), list(y_pred)) : .2f } " )列車データの精度スコア:0.98 検証データの精度スコア:0.83
したがって、システム全体で、トレーニングセットで98%、テストセットで83%の精度が得られます。この違いは、過剰適合が発生したことを証明しています(これについては次の記事で説明します)。
Bài viết liên quan:











Dịch vụ thiết kế Wesbite
