
データベースモデルの紹介、RDBMSコンセプトの紹介(関連データベース管理システム)
Mục lục
データベースの概念
通常、実際には、ウェブサイト、ソフトウェアプロジェクト、組織-運営中の機関は、毎日のデータ収集の結果である大量のデータを保持します(たとえば、データユーザー/ユーザー、政府居住者データ、学校の学生データ…これらのデータは以前は基本的に紙で保存され、今日では人々はそれらをデジタル化します。保存を容易にするための最も基本的なストレージソリューションは、ユーザーの観点からファイル(ファイル)に保存することです。以前は.txtテキストファイル、次に単語、優れたファイル( .doc、.xls)プログラマーに関しては、ファイルに保存します(Cでのテキストファイルの読み取りと書き込み、およびバイナリファイルの読み取りと書き込みを確認します)。最近のプログラミングでは、データ量がますます多くなり、管理が難しくなっています。 、人々は、レコードと呼ばれる1つ以上のデータ項目を含む可能性のあるデータの組織を表すためにデータベース(データベース)の概念を導入しました。データベースを理解することができますuは、さまざまな質問に応じてデータを満たすことができるデータセットです。例えば:
- データ編成で8点を超える生徒は何人いますか?
- データ組織のクラスAでのみ、スコアが9を超える2人の生徒を取り出します。
- データ組織内の最新の10人のユーザーレコードを取得します
- データ組織内の出身地がホーチミンであるすべての学生を取得します
- ..。
データとデータベース(データとデータベース)
データは情報であり、あらゆる種類の作業、組織メカニズムにおいて最も重要なコンポーネントです…日常の活動では、利用可能なデータを使用します。作成または更新、新しく生成されたデータの追加、データの収集、分析、および情報の提示ユーザー。人、車両、製品、スポーツ、天気などに関する情報である可能性があります。つまり、データは情報であり、この情報に基づいて、特定のタスクに役立つデータのブロックに収集されます。
例を挙げます。政府には、収集されたデータに基づいて、人口データ全体を保存するためのデータセットがあり、政府は次のことを識別できます。
- 18歳未満の人口(男性/女性を含む)
- 18歳の人口における男性と女性の平衡比
- 出生率(前回と比較した過去5〜10年間の人口の増加率)。
- ….。
または例:コンピューターコンポーネントを製造する会社は、以前はインポートされただけのコンポーネントを製造することを計画しています。会社が過去5年間の部品の輸入価格に関する古いデータを持っている場合、物事はより簡単になり、会社は輸入価格、輸入量、部品が毎年輸入されることに基づいて輸入部品の総コストを計算することができますそのデータから、工場への投資、人件費、完成品の生産コストが輸入品と大きく異なるかどうかを検討することができます。
この一連のデータに基づいて、政府はそれを完全に使用して判断し、開発の方向性に基づいて将来的に合理的な政策を立てることができます。
組織でも企業でも同じです。情報があれば、履歴データに基づいて予測し、それに応じて計画を立てることができます。集計が簡単な場合、スマートパフォーマンスは、企業や組織が多くのリソースとお金を節約するのに役立ちます。
データベースは、データのリストのコレクションです。または、データを格納するための互換性のあるデータ編成メカニズムとして理解できます。この情報には、ユーザーが効率的かつ迅速にアクセスできます。
例えば:
電話帳はデータベースです。このデータベースでは、各個人の連絡先情報はレコードと呼ばれ、このレコードには次のものが含まれます。
- 電話番号
- 電話の所有者情報
- 住所
- ..。
要約すると、データベースはデータの整理されたリストであり、その内容に簡単にアクセス、管理、または更新できます。
データ管理
データガバナンスは、情報ストレージの整理や、情報やデータを操作および操作するメカニズムの提供など、大量の情報を管理する必要がある場合に意味があります。さらに、システムは、アクセスできるユーザーの権利を制限するメカニズム、機密を保持する必要のあるデータ、アクセスを制限するメカニズムなど、さまざまな場合に保存された情報のセキュリティを確保する必要があります。パスワードを保存… 。
ファイルベースのシステム
保存するときのデータのサイズは常に大きな懸念事項です。以前は、ファイルシステム(ファイル)を使用してデータを保存していました(C言語でFILEを操作する記事をもう一度見ることができます)。このシステムでは、データはさまざまな個別のファイルに保存され、これらのファイルのコレクションはコンピューターに保存されます。それらは、オペレーティングシステムからのデータを照会して操作できます。データの保存に使用されるファイルは通常テーブルと呼ばれ、このテーブルの行はレコードと呼ばれ、列はフィールドと呼ばれます。
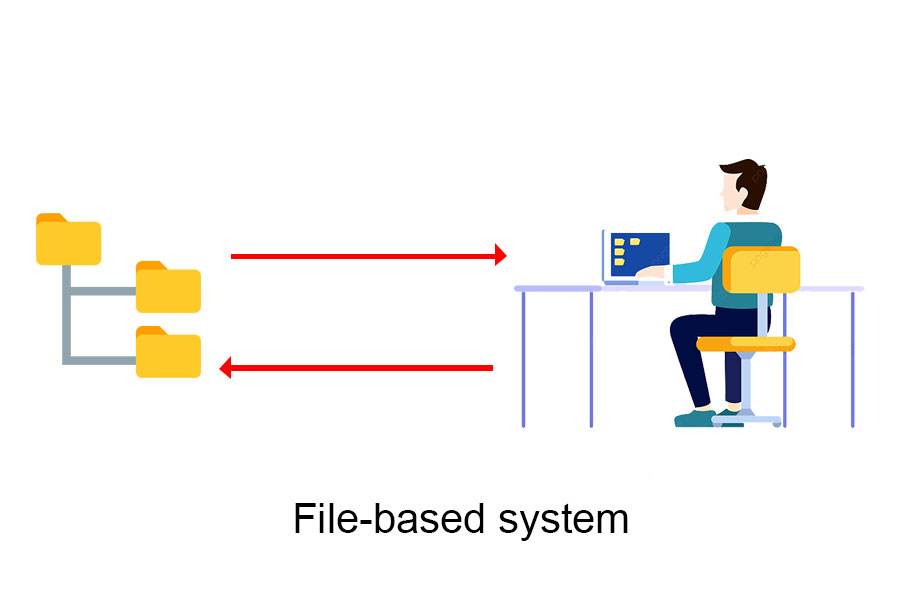
データベース管理システムが登場する前は、人々はファイルを使用してソフトウェアアプリケーションにデータを保存していました。
ファイルベースのシステムのデメリット
ファイルベースのシステムでは、アプリケーションのさまざまなプログラムと機能がさまざまなファイルと相互作用してビジネスに対応します。データ標準化システムがないか、データを整理する方法を示します。これらの個別のファイルの構造と構造。
データの冗長性と不整合
ファイルを分割して個別のデータを保存すると、個別のデータは簡単に冗長になり、一貫性がなくなります。たとえば、学生を追加/編集/削除/並べ替える機能は、学生リストを保存しているファイルと対話します。クラスを追加/編集/削除/並べ替える機能は、アーカイブファイルで機能します。クラスに属するオブジェクト、たとえば学生のNguyen Van Aはクラス1Bにあります->ここから、問題が発生します。利用可能なクラスデータに基づいて、学生が学習したクラスを保存するために、学生データファイルにフィールドを追加する必要があります。間違ったコード、非標準データ(誤った学生入力など)のいくつかの状況も、不合理な状況につながります(クラスがデータベースにないか、削除されましたが、学生側にはまだあります)。フィールドはそのクラスを表します。 ..
予期しないクエリ
ファイルベースのシステムでは、特にプログラムに変更があった場合、突然またはアドホックなクエリ処理が非常に困難になる可能性があります。たとえば、銀行員は、口座残高が$2000以上のすべての顧客のリストを作成する必要があります。銀行家には選択肢があります。すべての顧客のリストを取得して必要な情報を手動で抽出するか、システムプログラマーを雇って必要なアプリケーションプログラムを設計します。どちらの選択肢も不十分です。そのようなプログラムが作成され、数日後、従業員はそのリストを切り取って、1年前にアカウントを開設した顧客のみを含める必要があるとします。このようなリストジェネレータは存在しないため、データへのアクセスは困難です。
データ分離データ分離
データはさまざまなファイルに分散しており、ファイルの形式が異なる場合があります。データはアプリケーション内のさまざまなプログラムによって使用されますが、データを関連付けることができる状況がいくつかあり、それらは分散した無関係のデータファイルとして保存されます。
同時アクセスの異常
マルチユーザーシステムでは、ファイルまたはレコードに同時に多くのユーザーがアクセスできるため、ファイルベースのシステムの処理がより困難になります。
セキュリティの問題
企業や組織では、データのセキュリティも大きな問題です。データは安全である必要があり、許可されたファイルベースのシステムがこれをうまく実行できない場合にのみアクセスできます。
データ整合性の問題
どのアプリケーションでも、特定のデータ整合性ルールが必要であり、それを維持する必要があります。データの要素またはレコードに特定の条件または制約がある場合があります。ファイルベースのシステムでは、データはファイルにのみ保存されるため、データレイヤーでこれを行うことはできません。これらはコードレイヤーでのみ行うことができ、維持または変更を続けるのは非常に複雑です。アプリケーションデータは大きくなります。
データベースシステム
データベースシステムは、ビッグデータを処理および処理する際のアプリケーション開発の問題を解決するために1960年代に開発され、よりデータ集約的です。また、ファイルベースのシステムの欠点に起因する問題を解決するためにも。
データベースは、効率的かつ組織化された方法でデータを保存するために使用されます。データベースを使用すると、データを簡単かつ迅速に管理できます。たとえば、企業は人事情報に関するデータをデータベースに保持する必要があり、いつでもデータを簡単に照会、追加、または検索する必要があります…
たとえば、ストレージに関してのみ、単純な手動ファイルを使用してもデータを満たすことができる場合、大学は教師、学生、科目に関する情報を維持する必要があります。この情報は別々のファイルに維持および保存できますが、時間の経過とともにデータはファイルはジャンクになり、多くのストレージスペースを消費し、より多くの編集と削除を管理することは非常に困難です。難しいため、長年にわたる長期保存には適していません。
代わりに、データベースシステムに保存されているデータを使用すると、データを長期間保存できるため、クエリや更新が簡単になります。
データベースシステムの利点
データまたは情報は、標準に従って長期保存され、データベースシステムを使用してデジタル化されます。データベースシステムは、一元化されたデータストレージソリューションを提供するため、多くの利点があります。
保存されたデータの冗長性を減らすことができます
組織または機関内では、部門のデータは同じ構造を持っていることがよくあります。一元化されたデータベースを組み合わせると、複数の部門が同じ標準に対応するデータにアクセスできるようになり、データの重複やデータの冗長性を最小限に抑えることができます。
データの一貫性
ファイルベースのシステムを使用してデータが異なる部門で複製される場合、データへの変更は関連データに影響を与え、データの不整合につながることがあります。データの更新はコードレイヤーで行われるため、データとソースコードが複雑になり、問題が発生します。一元化されたデータベースシステムまたは私たちが話しているデータベースでは、データを定期的に更新することは完全に可能です。この場合、更新できるレコードは1つだけであり、データの不整合の問題を軽減します。
保存したデータを共有できます
データベースはサーバー内に配置でき、許可されたときにさまざまなユーザーと共有するメカニズムを備えています。このようにして、ユーザーはいつでもデータにアクセスして更新できます。
基準を設定し、それに従うことができます。
一元化されたガバナンスにより、表現されたデータ標準を確立して順守することができます。たとえば、Mr。を含むようにユーザーのフルネームを表すのが一般的です。 Toan Ngo Vinh(フルネーム)なので、3つのコンポーネントに分けられます。
- タイトルタイトル:Mr。
- 名前:トーアン
- フルネーム:Ngo Vinh
データベースを使用すると、データベース設計者の意図に従って保存するときにこの形式が保証されます。
データの整合性を維持できます
データの整合性は、データベースの精度に影響します。たとえば、従業員が組織を辞任した場合、人事データベースを更新する必要があります。退職したばかりの従業員の情報と関連データをデータベースから削除するか、人事履歴を保存するために別の場所に保存する必要があります。この従業員に関連する作業に関するデータは、作業を続行できるように別の従業員に転送する必要があります。
中央でホストされるデータベースは、これらのエラーを回避するのに役立ちます。データベースのメカニズムにより、データは確実にテーブルから削除され、このレコードとのリンクも設計者の意図に従って削除または更新されます。
データのセキュリティを実装できます
一元化されたデータベースシステムでは、データを更新する権限を承認する必要があります。正しいメカニズムは、データベース全体を完全に制御できるのは1人だけであるということです。この人はデータベース管理者(DBA)と呼ばれます。 DBAは、データに制限を設けることにより、セキュリティメカニズムを実装できます。 DBAの許可に基づいて、許可されたユーザーに、データの追加、編集、削除、および照会を行うための許可を割り当てることができます。
データベース管理システム(DBMS)
DBMSは、関連するレコードのリストと、これらのレコードを照会および処理できるプログラムのセットを定義できます。 DBMSを使用すると、ユーザーはデータにアクセス、保存、および管理できます。以前のDBMSの主な問題は、データがfilemに書き込まれるため、さまざまなオブジェクトに関する情報がさまざまな物理ファイルに保持されることでした。したがって、オブジェクト間の関連付けは別々のファイルに残り、ファイルと機能が多すぎて単一のシステムに統合できない状況になります。
これらの問題の解決策は、データを一元化されたデータベースシステムに正規化することです。データベースは1つの場所に保存され、ユーザーは自分のデバイスを介してサーバーに保存されているデータにアクセスできます。
一言で言えば、データベースは相互に関連するデータのリストのコレクションであり、DBMSはこのデータを追加、編集、および削除するために使用される一連のプログラムで構成されるシステムです。当然のことながら、DBMSは、データベースの定義、データの作成と操作、およびデータの操作に役立つ一連の機能を含むソフトウェアです。
DBMSは、大規模なデータセットとインタラクティブな更新操作を操作するための便利で効率的な環境を提供します。 DBMSは、パーソナルコンピュータで実行される小さなシステムから大きなコンピュータシステムまで対応できます。
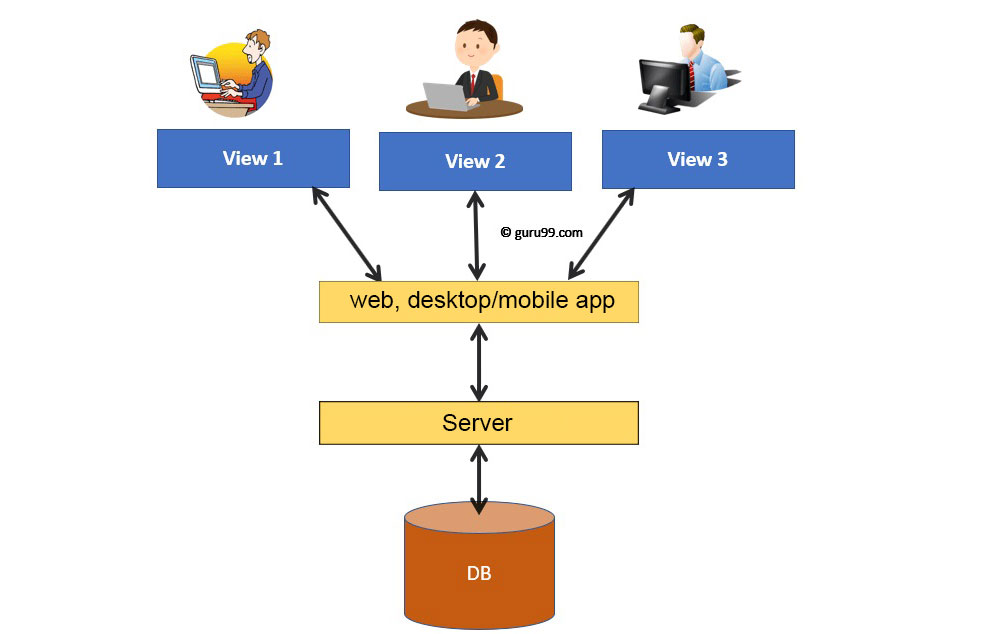
以下に、DBMSアプリケーションが実際に実行できることの例をいくつか示します。
- 図書館システムのデジタル化
- 現金自動預け払い機
- 航空券発券システム
- 小売および製造システム
- ..。
技術的な観点から、DBMS製品には多くの違いがあります。 DBMSはさまざまなクエリ言語をサポートしていますが、一般に、プログラマが必要に応じてDBMSに簡単にアクセスして変換できるようにするための共通点がいくつかあります。人々は、この言語を構造化クエリ言語(SQL)と呼んでいます。
データベースシステムを管理するための言語は、第4世代言語(4GL)と呼ばれます。データベースからの情報は、さまざまな形式で表示できます。ほとんどのDBMSには、ユーザーがレポート形式でデータをエクスポートできるレポート作成プログラムが含まれています。多くのDBMSには、グラフやチャートの形式のグラフィック情報も含まれています。
データベースをデプロイするために汎用DBMSを使用する必要はありません。ユーザーは独自のプログラムセットを作成してデータベースを作成および保守できるため、プログラマーの目的に応じて、クエリやデータの操作などに使用できるデータベースとDBMSを作成できます。データベースとソフトウェアを合わせてデータベースシステムと呼びます。
エンドユーザーは、データベースに直接クエリを実行するアプリケーションのグラフィカルインターフェイスを介してデータベースシステムにアクセスします。 DBMSを使用すると、ユーザーはクエリを実行し、結果をエンドユーザーに返すソフトウェアとプログラムの背後にあるソースコードを介してデータベースからデータを取得できます。
DBMSを使用する利点
DBMSは、データを処理し、それらを情報に変換する責任があります。この目的のために、特定のデータを取得するためのデータベースのクエリ、データベースの更新、レポートの生成など、データベースを操作する必要があります。
レポートには、情報、つまり処理されたデータが含まれます。 DBMSは、データのセキュリティと整合性を確保する責任もあります。
DBMSを使用する利点のいくつか:
データストレージ
通常、ほとんどのプログラムはデータを格納できるように設計する必要があります。この問題はDBMSによって処理されます。これは複雑なデータ構造を作成することによって行われ、このプロセスはデータ管理と呼ばれます。データの保存。
データ定義
DBMSは、アプリケーション内のデータの構造を定義する機能を提供します。これらには、レコードの構造、フィールドのデータ型とサイズ、および各フィールドが満たさなければならない制約と条件の定義と変更が含まれます。
データ操作
データ構造を定義したら、データを追加、更新、および削除できるようにする必要があります。これらの機能はDBMSの一部です。これらの関数は、計画されたデータ操作要求と計画されていないデータ操作要求を処理できます。計画されたクエリは、アプリケーションのアプリケーションの機能からのクエリです。計画外のクエリはアドホッククエリであり、必要に応じて実行されます。
データのセキュリティと整合性
データベースをマルチユーザー環境で使用する場合、データセキュリティは最も重要な機能の1つです。ユーザーデータアクセスチェックが必要です。データベースは、ルール、データベースにアクセスできるユーザー、ユーザーがアクセスできるデータ要素、またはユーザーが実行できるデータを使用した操作を決定します。
データベース内のデータには、エラーをできるだけ少なくする必要があります。たとえば、学生IDは常に有効である必要があり、空白であってはなりません。電話番号には番号のみを含める必要があります。これらはDBMSで確認できます。
データ回復および同時実行機能
システム障害が発生した場合のデータ回復と、複数のユーザーによるレコードへの同時アクセスは、DBMSによって簡単に処理できます。
パフォーマンス
クエリパフォーマンスの最適化は、DBMSの重要な機能の1つです。したがって、DBMSには、パフォーマンスの標準化、最適化に役立つ一連のプログラムがあります。つまり、DBMSはさまざまなクエリの実装を推測し、使用するのに最適なソリューションを選択します。
マルチユーザーアクセス制御
いつでも、複数のユーザーが同じトレンDBデータにアクセスできます。DBMSは、異なるユーザー間でデータを共有し、データの整合性を維持するのに役立ちます。
データベースアクセス言語とAPI
DBMSクエリ言語は、データアクセスソリューションを実装します。 SQLは最も一般的に使用されるクエリ言語です。クエリ言語は非手続き型言語です。つまり、ユーザーは必要なものをクエリし、その方法を指定する必要はありません。
例:構文の観点は言うまでもなく、SQLを使用して、学生データベースで最高スコアの10人の学生のリストを取得します。ステートメントの意味は、最高スコアの10人の学生を上位から並べ替えることです。低い値までですが、手続き型言語の場合、これを行うには、順番に実行する必要があります。学生配列を取り出し、ループで上から下に並べ替えてから、最初の10個の要素を取り出します。
データベースモデル
データベースは、機能とデータモデルに基づいて区別できます。データモデルは、データを格納するためのコンテナと、そのコンテナからデータを格納および取得するためのプロセスを記述します。データモデルの分析と設計は、データベース開発の基礎です。
フラットファイルデータモデル
このモデルでは、データベースには1つのテーブルまたは1つのファイルしか含まれていません。このモデルは、単純なデータベースに使用されます。たとえば、学生のグループのロール番号、名前、科目、および学年を保存したいとします。このモデルは複雑なデータを処理できません。このパターンは、データが複数回繰り返される場合に、データの冗長性の原因となる可能性があります。

階層データモデル
階層データモデルでは、さまざまなレコードが階層またはツリー構造を介して関連付けられます。このモデルでは、関係は親子の用語または構造を介して行われます。ただし、子構造には親が1つしかありません。このモデルでデータを検索するには、ユーザーがデータの階層構造を理解することが不可欠です。
Windowsレジストリは、Windowsオペレーティングシステムの構成と設定を格納するために使用される階層型データベースの例です。
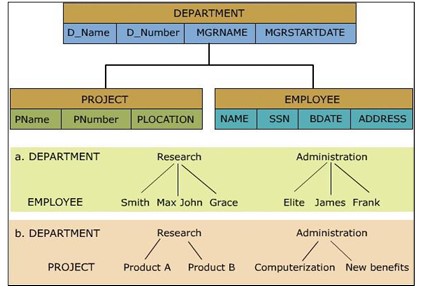
階層化されたデータモデルの利点
- データはデータベースに保存されるため、共有が容易であり、セキュリティはDBMSによって提供および実施されます。
- 独立したデータはDBMSによって提供され、プログラムを維持するためのリソースとコストを削減します
このモデルは、データベースに大量のデータが含まれている場合に非常に効果的です。
ネットワークデータモデル
このモデルは、層化モデルに似ています。層化モデルは、基本的にネットワークモデルのサブセットです。ただし、階層型の親子ツリーを使用する代わりに、ネットワークモデルは集合論を使用して、子テーブルが複数の親を許可することを除いて、階層型モデルを提供します。
ネットワークモデルでは、データは階層化された形式ではなく、集約で保存されます。これにより、冗長性の問題が解決されます。したがって、レコードはリンクリストを介して物理リンクにアップロードされます。
一部の企業は、ネットワークデータモデルを開発しています。
https://en.wikipedia.org/wiki/IDMS
ネットワークモデルと階層データモデルは、多くの商用DBMSを実装するための主要なデータモデルでした。ネットワークモデルコンストラクトと言語コンストラクトは、データシステム言語に関する会議/委員会(CODASYL)のデータシステム言語委員会によって定義されています。
データベースごとに、データベース名の定義、各レコードのレコードタイプ、およびこれらのレコードを構成するコンポーネントが格納されます。これらはネットワークスキーマと呼ばれます。アプリケーションプログラムによって表示されるデータベースの部分は、実際には、サブスキーマと呼ばれるデータベース内のデータコンテナからの必要な情報で構成されています。これにより、アプリケーションプログラムはデータベースから要求されたデータにアクセスできます。
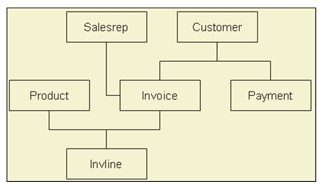
ネットワークデータモデルの利点:
このモデルでは、データに簡単にアクセスでき、アプリケーションはセット内の所有者レコードとメンバーレコードにもアクセスできます。ネットワークモデルでは、所有者なしでメンバーが存在することはできません。これにより、データの整合性が保証されます。
ネットワークデータモデルのデメリット:
このモデルのデザインや構造はユーザーフレンドリーではありません。このモデルには自動クエリ最適化スコープがなく、クエリのパフォーマンスはプログラマーのスキル、経験、アルゴリズムに大きく依存します。ネットワークデータベースモデルはデータの独立性を実現できますが、このモデルは構造的な独立性を実現しません。
リレーショナルデータモデル
情報を扱う必要性が高まり、データベースを扱うアプリケーションの開発がますます複雑になるため、データの設計、管理、および操作はますます面倒になります。クエリ機能がないため、プログラマーが最も単純なレポートを生成するのに多くの時間がかかり、リレーショナルモデルデータベースと呼ばれる概念が開発されました。
「関係」という用語は、数学的集合論に由来します。このモデルでは、階層モデルやネットワークモデルとは異なり、物理的な接続はまったくありません(親子ツリーモデルは関連付けとして理解されます)。すべてのデータは、行と列で構成されるテーブルテンプレートに保存されます。 2つのテーブルのデータは、物理リンク(親と子)ではなく、共通の列を介してリンクされています。プログラマーは、提供されている構文またはソフトウェアインターフェイスを使用して、テーブル内の行またはレコードを操作します。
有名なリレーショナルデータベースには、 Oracle(Mysql) 、Sybase、DB2、 Posgres、MicrosoftSQLServerなどがあります。
このモデルは、データベースを関係のコレクションとして表します。このモデル用語では、行はタプル(未翻訳、wikiを参照: https ://en.wikipedia.org/wiki/tuple、列は属性)、テーブルはリレーション(リレーションシップ)と呼ばれることもあります適用される値のリストフィールドへのドメインはドメインと呼ばれ、関係の属性の数は関係の程度と呼ばれます。フィールドのタプル(値)の数は、関係の性質を決定します。
それが理論です、兄弟、理解しやすいようにこれを覚えておいてください:
- テーブル(テーブル)は行(行)と列(列)で構成され、行と列の交点はフィールド(フィールド)です。このテーブルは実際の情報を記述できます。
- 各行は異なるレコード、通常は実際のエンティティの情報を表します
- 列はオブジェクトのプロパティ(プロパティ)を表します
- 共通の列を介して相互にリンクされたテーブル
たとえば、単純なHR計算を表すために使用する2つのテーブル:
- 表現フィールド(人事コード、名前、年齢、住所、給与)を含む人事テーブル
- 給与スプレッドシートには、パフォーマンスフィールド(レコードコード、人事コード、勤務日、月、総給与)が含まれています。
- これらの2つのテーブルは、人事コード列を介してリンクされています
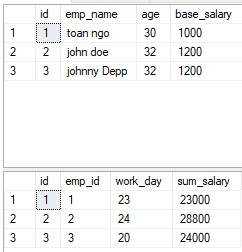
リレーショナルデータモデルの利点
リレーショナルデータベースモデルにより、プログラマーは物理ビューについて心配するのではなく、データベースの論理ビューに集中することができます。柔軟性の理由の1つ。ほとんどのリレーショナルデータベースは、構造化クエリ言語(SQL)を使用しています。 RDBMSは、SQLを使用して、ユーザーのクエリを、要求されたデータを取得するために必要な技術コードに変換します。リレーショナルモデルは非常に扱いやすいため、適切なデータベースを設計するために必要な多くの要件がなくても、トレーニングを受けていない人でも簡単に便利なクエリやレポートを生成できます。
リレーショナルモデルの欠点
- モデルはシステムのすべての複雑さを隠しますが、他のデータベースシステムよりも遅くなる傾向があります。
- 他のすべてのモデルと比較して、リレーショナルデータモデルは最も人気があり、広く使用されています
リレーショナルデータベース管理システム
リレーショナルモデルは、データベース構造を単純化する試みです。データベース内のすべてのデータに、単純な行の色のデータ値テーブルとして応答します。 RDBMSは、リレーショナルデータベースを作成、維持、および操作するソフトウェアプログラムです。リレーショナルデータベースは、テーブルと呼ばれる論理ユニットに分割されたデータベースであり、テーブルはデータベース内で相互に関連付けられています。
テーブルはリレーショナルデータベースで関連付けられているため、1回のクエリで完全なデータを取得できます(複数のテーブルに存在する可能性のある目的のデータを置き換えます)。リレーショナルデータベーステーブル間で共通のキーまたはフィールドを使用することにより、複数のテーブルのデータを大規模な結果セットから組み合わせることができます。
したがって、リレーショナルデータベースはリレーショナルモデル上に構造化されたデータベースであり、リレーショナルモデルの基本的な特徴は、実際のモデルでは、データがリレーションで引き裂かれるということです。
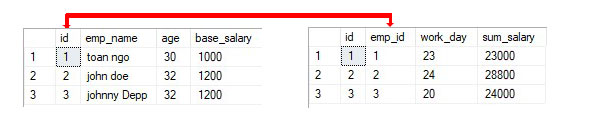
RDBMSの利用規約
- データは一連の関係として表示されます。
- 各関係は表として記述されます
- 列は属性です
- エンティティ表現行
- 各テーブルには、各エンティティ(レコード)を一意に識別するキーとしてまとめられた属性のセットがあります。
| ルール | 意味のある |
| 関係 | ボード |
| タプル | テーブルの行またはレコード |
| 属性 | テーブルのフィールドまたは列 |
| 関係のカーディナリティ | テーブル内のレコード数 |
| 関係の程度 | テーブル属性の数 |
| 属性のドメイン | 属性によって使用されるすべての可能な値のセット |
| 関係の主キー | リレーションシップ(テーブル)内の各タプルを一意に識別する属性または属性の組み合わせ |
| 外部キー(外部キー) | テーブル間の関係を定義する属性または属性の組み合わせ |
ユーザーRDBMS
データベースシステムの主な目標は、データベースから情報を取得し、データベースに新しい情報を格納するための環境を提供することです。
小さな個人データベースの場合、通常、1人の人がデータベースを使用して構造と操作を定義します
ただし、RDBMSは、複数のユーザーが大規模なデータベースの設計、使用、および保守に参加するのに役立つ機能を提供します。
エンティティとテーブル
エンティティの概念(エンティティ)
それらを人、場所、物、物、または単にアイデアなどの現実の物体として視覚化できることは、明確に識別されます。たとえば、学校のエンティティは、学生、教師、トレーニング担当者、科目などです。
各エンティティには、属性と呼ばれる固有の特性があります。たとえば、学生エンティティには、学生ID、名前、スコアなどの属性を含めることができます。各属性には、説明する適切な名前があります。
関連するエンティティのグループは、エンティティセットと呼ばれます。各エンティティには一意の名前があり、エンティティの名前はコンテンツ、格納するデータを反映します。したがって、学校のすべての生徒のプロパティは、studentという名前のオブジェクトに保存されます。
テーブルとその特性
テーブルと呼ばれる構造に基づいてデータ関係を作成することにより、データへのアクセスと操作が容易になります。テーブルには、エンティティセットである関連エンティティのグループが含まれています。人々はエンティティを置き換える名前としてテーブルを使用します。テーブルはリレーション、行はタプル、列は属性です。
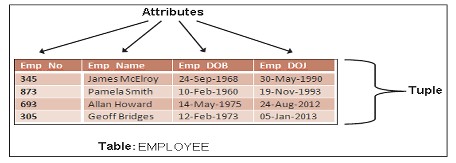
テーブルの特性は、次の基準に従います。
- 行と列で構成される2次元構造は、テーブルと見なされます。
- 各タプルは、エンティティセット内のエンティティを表します。
- 各列には特定の名前があります。
- 各行/列の共通部分は、個別のデータ値を表します。
- 各テーブルには、各行を一意に識別するためのキー(主キー)が常に必要です。
- 列のすべての値は、同じデータ形式で正規化する必要があります。たとえば、属性に整数データ形式が割り当てられている場合、すべての列の値は常に整数として表されます。
- 各列には、属性ドメインと呼ばれる定義された値の範囲があります。
- 各行には、エンティティの完全な説明が含まれています
- 行と列の順序はDBMSでは重要ではありません
DBMSとRDBMSの違い
| DBMS | RDBMS |
| 表形式のデータは必要ありません。また、データ項目間の表形式の関係も必要ありません。 | RDBMSでは、テーブル構造が必須であり、テーブルの関係により、ユーザーはビジネスルールを適用および管理し、コード作成の作業と複雑さを軽減できます。 |
| データは小さなサイズで保存および取得できます | データは大きなサイズで保存および取得できます |
| セキュリティが低い | より高いセキュリティ |
| シングルユーザーシステム | マルチユーザーシステム |
| ほとんどのDBMSはクライアント/サーバーアーキテクチャをサポートしていません | クライアント/サーバーアーキテクチャのサポート |
RDBMSでは、関係がより重要になります。その結果、依存RDBMSのテーブルとユーザーは、これらのテーブルに異なる整合性制約を設定して、ユーザーが消費する最終データが正しいままになるようにすることができます。 DBMSの場合、オブジェクトがより重要視され、これらのエンティティ間に安定した関係はありません。
この記事では、データベースの現在までの違いと開発履歴をご理解いただければ幸いです。記事に誤りがある場合は、チームが更新できるように以下にコメントしてください。遠慮なく質問してください。勉強を頑張ってください。
Bài viết liên quan:










Dịch vụ thiết kế Wesbite
