実体関連モデル(ERモデル)とデータの正規化(正規化)
データモデルは、データ、それらの関係、およびそれらの意味を記述するために使用される概念ツールのグループです。また、データが従う必要のある整合性の制約も含まれています。エンティティ-関係モデルでは、ネットワーク関係または階層モデルはすべてデータモデルの例です。データベースモデルの概要の記事を参照してください。理解を深めるために、RDBMSの概念(関連するデータベース管理システム)を紹介してください。各データベースの開発は、データを表すのに最適なデータモデルを見つけるためのデータ分析の基本的な手順から始まります。
Mục lục
データモデリング
データを整理および構造化するために、適切なデータモデルをデータに適用するプロセスは、データモデリングと呼ばれます。
データモデリングは、データベースの開発だけでなく、プロジェクトの計画と設計にも不可欠です。データモデルなしでデータベースを構築することは、計画や設計なしでプロジェクトを開発するようなものです。データモデルは、データベース開発者がデータベース内のテーブル、主キー、外部キー、ストアドプロシージャ、トリガーの関係を定義するのに役立ちます。これはイベントトリガーです)…
データモデリングの手順は次のとおりです。
- 概念的なデータモデリング:データは、最上位のデータの関係によってモデル化されます。このモデルの目的は、概念とルール、およびビジネスプロセスを整理、範囲設定、および定義することです。概念データモデルが作成されると、それを適応させて論理データモデルに変換することができます。
- 論理データモデリング:モデル化されたデータは、データとその関係を詳細に記述します。モデル化されたデータは、データベースの論理モデルを作成します。モデルの主な目的は、ルールとデータ構造のテクニカルマップを作成することです。論理データモデルは、物理データモデルを作成するための基礎として機能します。
- 物理データモデリング:このモデルは、特定のデータベース管理システムを使用してシステムを実装する方法を説明します。このモデルは、実際のデータベースを実装することを主な目的として、データ管理者や開発者によって作成されることがよくあります。
実体関連モデル-ERモデル
データモデルは、次の3つのグループに分類できます。
- オブジェクトベースのロジックモデル
- レコードに基づく論理モデル
- 物理モデル
実体関連(ER)モデルは、最初のカテゴリであるオブジェクトベースのロジックモデルに属します。
モデルは、現実に接触するという単純なアイデアに基づいています。データは、オブジェクトと呼ばれる実世界のオブジェクトと、それらの間に存在する関係と考えることができます。たとえば、組織で働いている従業員に関するデータは、従業員の集合と、組織を構成するさまざまな部門(部門)の集合と考えることができます。従業員と部門はどちらも実世界のオブジェクトです。部門の従業員。したがって、「所属」関係は、従業員を特定の部門に関連付けます。

ERモデルには、次の5つの基本コンポーネントが含まれています。
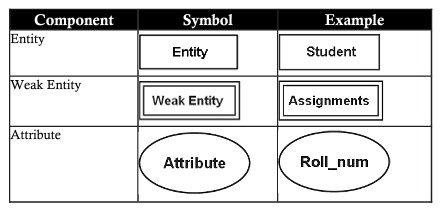
| エンティティ(エンティティ) | エンティティは、物理的に存在し、他のオブジェクトと区別できる実世界のオブジェクトです。例:人事、部門、学生、顧客、アカウント…..エンティティと呼ぶことができます |
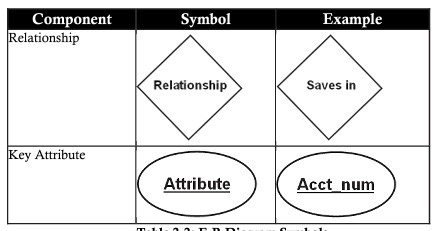
| 関係(関係) | 関係は、1つ以上のエンティティ間に存在する1つまたは複数の関連付けです。例:所属、所有、勤務、保存、購入… |
| 属性(属性) | 属性は、エンティティが持つ機能です。属性は、各エンティティを別のエンティティと区別するのに役立ちます。学生と顧客の2つの属性の例。同じ人物ですが、データベースに表示されたときに属性が異なります。 -エンティティstudentには、student_id、name、age、markという属性があります。 -エンティティcustomerには、customer_id、name、age、phone、addressという属性があります |
| エンティティセット(エンティティセット) | エンティティセットは、類似したオブジェクトのリスト(セット)です。たとえば、学校の生徒のリスト(同じ属性を持つ共通の基準による)は、生徒エンティティセットと呼ばれます。 |
| 関係セット | 2つ以上のエンティティセット間の関係のリスト(セット)は、関係セットと呼ばれます。たとえば、学生は多くの異なる主題を研究します。学生と主体の2つのエンティティ間に存在するすべての「主体学習」関係のセットは、「学習」関係セットと呼ぶことができます。 |
1つ以上のエンティティ間の関連付け関係であり、次の3種類の関係を持つことができます。
自己関係
エンティティとそのようなオブジェクト間の関係は、自己関係と呼ばれます。たとえば、マネージャーとチームのメンバーはどちらも人員であり、同じエンティティセットに属しています。チームメンバーは管理のために働くため、2つの異なるHRエンティティ間に「働く」関係が存在しますが、これらの担当者は同じエンティティセットに属しています。
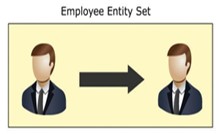
二項関係
2つの異なるエンティティセットにあるエンティティ間に存在する関係は、バイナリ関係と呼ばれます。たとえば、従業員は部門に属しています。 2つの異なるエンティティセットにある2つのエンティティ間に関係が存在します。 HRエンティティはエンティティセット(従業員)にあり、部門エンティティはエンティティセット(部門)にあります。
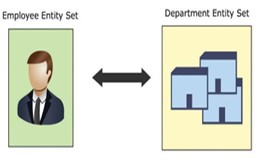
三項関係(3人関係)
簡単に言うと、この関係は3つの参加エンティティの関係であり、三項関係と呼ばれます。たとえば、従業員は組織の特定の支店の財務部門で働いています。ここでは、3つの異なるエンティティがあります。人員、部門、ブランチ、および人員は、ブランチを表すエンティティセットを介して部門に関連付けられます。
関係は、マッピングのカーディナリティに従って分類することもできます。さまざまなタイプのマッピングは、次のように区別されます。
1対1(1対1のマッピング)
このマッピングは、あるエンティティセットのオブジェクトを別のエンティティセットの1つのインスタンスにのみ関連付けることができる場合に存在します。たとえば、市民のオートバイ免許証コードに直接かつ一意にリンクする市民の市民識別番号。 1つの識別番号を持つ市民が複数のオートバイ免許証コードを持つことはできません。それは遠い光または1対1の関係と呼ばれます。

1対多(1対多のマッピング)
このタイプのマッピングは、エンティティセット内のエンティティが別のエンティティセット内の複数のエンティティに関連付けられている場合に使用されます。たとえば、クラスに多数の生徒がいる場合、このマッピングを表すために1対多のマッピングがよく使用されます。多くの場合、これは1対多の関係または1対多のマッピングと呼ばれます。
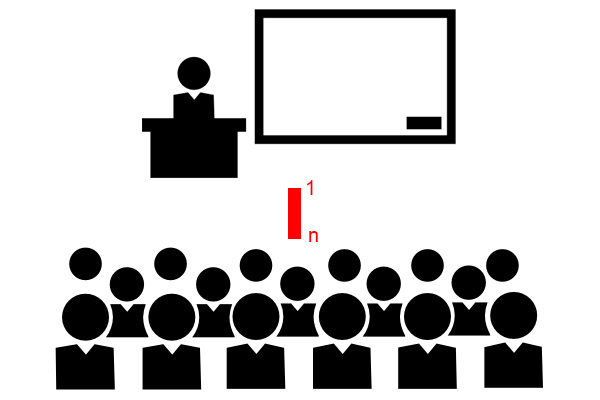
多対1(多対1のマッピング)
このタイプのマッピングは、エンティティセット内の複数のエンティティが別のエンティティセットのエンティティに関連付けられている場合に使用されます。このマッピングは、1対多のマッピングの反対であると大まかに理解しています。たとえば、クラスには多くの生徒がいます。
多対多(多対多のマッピング)
このタイプのマッピングは、1つのエンティティセットの複数のエンティティが別のエンティティセットの多くのエンティティに関連付けられている場合に使用されます。
たとえば、店舗には多くの商品が販売されており、購入時の各顧客の注文にはさまざまな商品が含まれます。1つの注文に多くの商品が含まれる可能性がありますが、1つの商品も多くの注文に表示されます。これは、多くの商品の最良の例です。 -多対多のマッピング。
さらに、ERモデルは次のようないくつかの概念にも準拠しています。
主キー(主キー)
主キーは、エンティティセットに対するエンティティの一意性を判断するために使用される属性です。データベース構造では、通常、テーブル(エンティティセット)の主キーとして列を使用することをお勧めします。
弱いエンティティセット
主キーを定義する属性を持たないエンティティセットは、ウィークエンティティセットと呼ばれます。
強力なエンティティセット
主キーを定義する属性を持つエンティティセットは、強力なエンティティセットと呼ばれます。
実体関連図(ER図)
ERダイアグラムは、ERモデルをグラフィカルに表現したものです。 ERダイアグラムでは、記号を使用してERモデルのさまざまなコンポーネントを効果的に表します。
ERモデルの属性は、次のように分類できます。
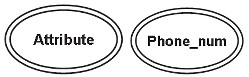
複数値(複数値)
複数値の属性は、エンティティの少なくとも1つのインスタンスに対して複数の値を持つ2行の楕円で示されます。この属性には、個々のエンティティ値に指定された上限と下限を含めることができます。
たとえば、phone_number属性は、エンティティの複数の値を格納できます。 (1人が複数の電話番号を持つことができます)
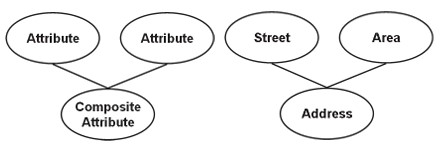
コンポジット(合成)
複合属性自体には2つ以上の属性を含めることができ、サブ属性は基本的なプロパティであり、独自の独立した意味を持ちます。
たとえば、住所属性は通常、複合属性です。たとえば、会社の住所を表す場合、6/203 Truong Chinh-Thanh Xuan-HN、6/203 Truong Chinhが住所になり、ThanhXuanはそれをハノイの地区に保存します。シティです
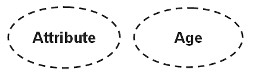
派生(派生属性)
派生プロパティは、値が別の属性に完全に依存する属性であり、楕円で構成される楕円で表されます。
人の年齢属性は、派生属性の最良の例です。特定の個人エンティティの場合、個人の年齢は、その個人の現在の日付と生年月日から決定できます。
ER図を構成する手順は次のとおりです。
- モデル化する必要のあるすべてのデータを収集します。
- 実世界のエンティティとしてモデル化できるデータを定義します。
- 各エンティティの属性を特定します。
- エンティティセットを弱いエンティティセットまたは強いエンティティセットに並べ替えます。
- エンティティ属性をキー属性、複数値属性、複合属性、派生属性などとして並べ替えます。
- さまざまな操作要因間の関係を特定します。
- さまざまなシンボルを使用して、誘惑要素、それらのプロパティ、およびそれらの関係を描画します。プロパティをプロットするときは、適切なシステムを使用してください。
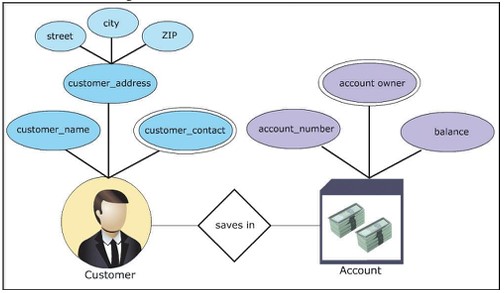
たとえば、顧客とアカウントを管理して、銀行をシミュレートするデータベースを構築します。シナリオのERダイアグラムは、次のように作成できます。
- データ収集:このビジネスには、お金を預けたいアカウントと顧客のリストが必要です。
- エンティティの識別:顧客、アカウントの2つのエンティティがあります
- プロパティを定義します。
- 顧客:名前、住所、連絡先
- アカウント:ID、所有者、残高
- エンティティセットの並べ替え
- 顧客:弱いエンティティセット
- アカウント:強力なエンティティセット
- プロパティを並べ替える
- 顧客エンティティセット:アドレス-複合、連絡先-複数値
- accounetエンティティセット:id-主キー、所有者-複数値
- 関係を定義する:顧客は口座にお金を預け入れます。関係は「預け入れ」になります
- グラフERモデルを描画します
正規化(データの正規化)
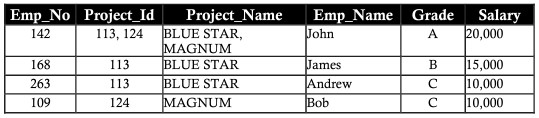
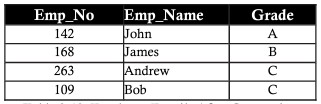
通常、すべてのデータベースは、多数の列とレコードによって識別されます。このアプローチには特定の制限があります。 2つのエンティティがプロジェクトの同じ従業員テーブルに保存されている次の例について考えてみます。従業員の詳細と、彼らが取り組んでいるプロジェクトの詳細を含めます。
データが正規化されていない場合に発生する問題の概念は次のとおりです。
繰り返し異常
project_id、project_name、salaryなどの列には、繰り返しレコードにデータがあります。この繰り返しは、データ取得のパフォーマンスとストレージ容量の両方を妨げます。このデータの繰り返しは、繰り返し異常と呼ばれます
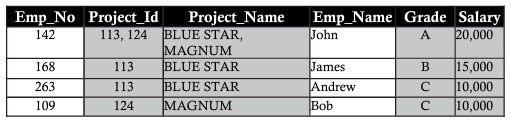
挿入異常
部門の新しいメンバーがアンという名前の新しい従業員であると想定します。現在、アンにはプロジェクトが割り当てられていません。 Project_id、Project_nameという名前の列に空白のセルがあるテーブルに彼女の詳細を挿入します。列を空白のままにすると、後でいくつかの問題が発生します。挿入操作によって作成された異常は、挿入異常と呼ばれます。
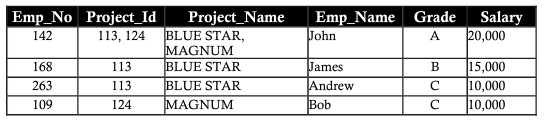
異常の削除(異常/異常の削除)
ボブがMAGNUMプロジェクトから取得されたと仮定します。従業員番号(employee_number)、ランク(grade)、および給与(salary)を含む従業員名がBobであるMAGNUMプロジェクトレコードを削除します。データの損失はボブの個人情報の詳細に影響します。この損失は下の表で確認できます。上記の削除によって失われたデータは、削除異常と呼ばれます。

異常の更新
ジョンに昇給または減額が与えられたと仮定します。ジョンの給与または等級の変更は、ジョンが取り組んでいるすべてのプロジェクトに反映される必要があります。これは、異常の更新と呼ばれます。
部門の従業員の詳細を示すテーブルは、非正規化テーブルと呼ばれます。これらの制限は、正規化が必要であることを示唆しています。
正規化は、不要な冗長性と依存関係を削除するプロセスです。 Codd(1972)は当初、関係の属性間の依存関係に基づいた3つの正規化形式(1NF、2NF、および3NF)について説明しました。 4番目の正規形(4NF)と5番目の正規形(5NF)は、多値の依存関係に基づいており、後で導入されました。
第一正規形(1NF)
1NFを完了する手順は次のとおりです。
- 関連データのグループごとに個別のテーブルを作成します
- テーブルの列には素数を格納する必要があります(プリミティブ値を理解できます)
- すべての主キー属性を定義する必要があります
上記の表の例を考慮すると、プロジェクトと従業員の2つのエンティティを明確に分割して表を正規化する必要があります。
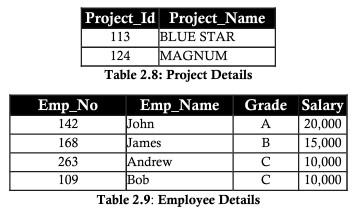
第2正規形(2NF)
次の要件が満たされている場合、テーブルは2NFと呼ばれます。
- 1NFの要件を満たす
- テーブルに依存関係はありません
- テーブルは外部キーを介してリンクされています。
上記の例を考慮して、2NFを使用して、中間テーブルを介してプロジェクトテーブルと従業員テーブル(プロジェクトが割り当てられている従業員を知るため)をリンクします。
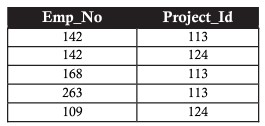
第3正規形(3NF)
3NFの正規化を完了するには、次の要件を満たす必要があります。
- テーブルは2NFの要件を満たす必要があります
- テーブルに従属列を含めることはできません
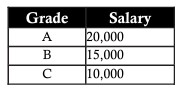
上記の例を続けると、employeeテーブルでは、Salary列が一般式に従ってGrade列に依存していることがわかります。 B-15,000 | C-10,000。したがって、このデータを正規化するために、成績のみを格納する従業員テーブルと、成績と給与を示すテーブルを分割します。そうすると、後で成績を追加および更新して、データ全体に影響を与えることなく、ニーズを簡単に満たすことができます。

非正規化
データを正規化することにより、冗長なデータが最小限に抑えられます。これは、データベースに必要なデータベースストレージスペースのサイズが削減されることを意味します。ただし、次のようないくつかの制限もあります。
- 異なるテーブル間でデータを接続すると、クエリステートメントがより複雑になります
- 実際、クエリステートメントには、情報のニーズに応じて3つ以上のテーブルが含まれる場合があります(クエリステートメント、y / cプログラマー、または高度に専門化されたDBAの記述が複雑になります)。
結合クエリステートメントが頻繁に使用されると、データベースのパフォーマンスが低下し、CPUの処理時間が長くなり、プログラムの速度に影響します。したがって、場合によっては、冗長データを使用してデータベースのパフォーマンスを向上させることができます。つまり、非正規化(データ非正規化)と呼ばれる冗長データストレージ(ストレージ容量を犠牲にしてパフォーマンスを向上させる)を受け入れることができます。
関係演算子
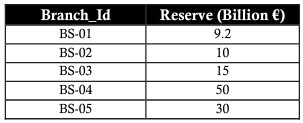
リレーショナルモデルは、関係代数の強固な基盤に基づいています。関係代数は、関係を操作する一連の演算子で構成されます。各演算子は、入力として1つまたは2つのリレーションを取り、出力として新しいリレーションを作成します。次のブランチを持つサンプルの銀行データテーブルについて考えてみます。
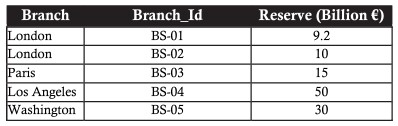
SELECT(選択)
SELECT演算子は、必要な条件を満たすデータを取得するために使用されます。シグモイド文字(ð)は、選択を表すために使用されます。
以下の例は、ロンドンに支店があるレコードを選択する場合の表です。
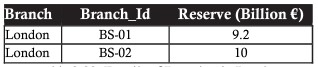
または、200億ユーロを超えるリバースで支店を取得する必要があるトランザクション

プロジェクト(プロジェクション)
PROJECT演算子は、リレーショナルテーブルの詳細を参照するために使用されます。 PPROJECT演算子は、必須フィールドのみを表示し、列の不要フィールドは除外します。 PROJECT演算子は、円周率文字「π」で表されます。
以下の例では、PROJECT演算子を使用して、ブランチ名を取得せずにビジネスのIDとリバースを取得します。
PRODUCT(乗算/製品)
PRODUCT演算子は、文字「x」で表される2つの関連するテーブルからの情報を表面的に結合するために使用されます。
たとえば、次のようなローンテーブルがあります。

ブランチテーブルとローンテーブルを組み合わせて、総準備金と総ローンを表すために使用されるPRODUCT演算子を使用します。
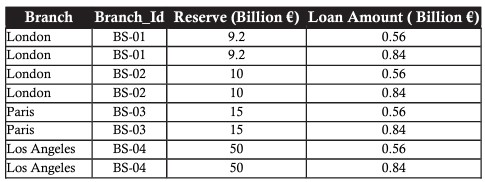
乗算は、最初のテーブルの各レコードを2番目のテーブルのすべてのレコードと組み合わせます。つまり、2つのテーブルのレコード間に可能なすべての組み合わせを作成します。
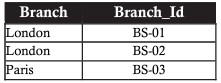
UNION(協会)
上記の銀行のサンプルデータを考えると、経営陣は、200億ユーロ未満の準備金またはローンを持っている支店を取り出したいと考えているとしましょう。結果のテーブルには、200億ユーロ未満の準備金またはローン、あるいは基準を満たす両方の列を持つブランチが含まれている必要があります。
この視覚化は、2つのデータセット間の組み合わせであり、手順は次のとおりです。
- 準備金が200億ユーロ未満の支店のコレクション
- 200億ユーロ未満のローンを持つ支店のセット
- 2つのセットをマージして、同じ準備金とローンが200億ユーロ未満の支店が1回だけ表示されるようにします。
INTERSECT(交差点)
これらの支店のどれが低い準備金と低い貸付の両方を持っているかを知りたいとしましょう。解決策は、交差点INTERSECT演算子を使用することです。 INTERSECT演算子は、それが適用されるすべてのテーブルに正しいデータを生成します。これは交差集合論に基づいており、記号「 」で表されます。結果は、200億ユーロ未満で準備金とローンの両方の基準を満たす支店のリストを含む2つのテーブルの共通部分になります。

違い(奇跡)
上記の例に戻って、どの支店の準備金が少ないがローンがないかを知りたい場合、解決策は (違い)。表記は「-」文字で示され、その出力は2つの異なるテーブルからの和集合ですが、違いは、一方のテーブルの正しい値のみを取得し、もう一方のテーブルは取得しないため、準備金は少ないがローンがないブランチは取り出さないでください。

加入
連結は、乗算の結果の選択を可能にする乗算の拡張です。たとえば、上記のPRODUCTを使用して支店の準備金とローンが少ない場合、データは冗長になり、集計して削減する必要があります。 JOINのアウトプットは、200億ユーロ未満の準備金とローン資本の両方を持つ新しく上場された支店のみを返します。

DIVIDE(除算/商)
もう一度、支店のテネとローンを持っているすべての支店の準備金を確認したいとします。この状況を処理するには、DIVIDE権限を使用する必要があります。必要なのは、Branch Reverse Detailsテーブル(2.19)をブランチのリストと、BranchLoanDetailsテーブル(2.23)のBranch_id列で分割することだけです。結果は以下のようになります。

注:分割テーブルのプロパティは、常に分割テーブルのサブセットである必要があります。結果のテーブルは常に分割テーブルのプロパティを空白のままにし、レコードは分割テーブルのレコードと一致しません。
Bài viết liên quan:










Dịch vụ thiết kế Wesbite
