
機械学習でのデータ前処理、具体例。
ご存知のように、データは非常に重要な部分であり、トレーニングモデルに直接影響するため、データの前処理はMachlineLearningに不可欠なステップです。したがって、データをモデルに配置する前にデータを前処理することが非常に重要であり、欠落しているデータを削除または補正するのに役立ちます。
この記事では、乾式理論だけでなく、特定の例を通じて、モデルに入る前にデータがどのように処理されるかを理解するのに役立ちます。
最初は間違いなくあなたが練習するためのデータセットです。
Mục lục
データを準備します。
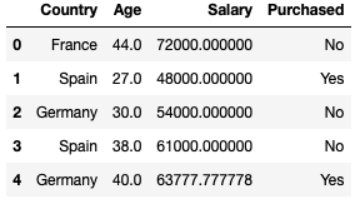
以下のリンクからデータを入手できます。簡単に言うと、これは10行4列のデータです。後で、実行する10行のデータを選択した理由がわかります。年齢や給与が異なる、国を超えた多くの人々の自動車購入行動に関する統計データ。いくつかの失われたデータもあります。
dataset = pd.read_csv("data.csv") Country Age Salary Purchased 0 France 44.0 72000.0 No 1 Spain 27.0 48000.0 Yes 2 Germany 30.0 54000.0 No 3 Spain 38.0 61000.0 No 4 Germany 40.0 NaN Yes 5 France 35.0 58000.0 Yes 6 Spain NaN 52000.0 No 7 France 48.0 79000.0 Yes 8 Germany 50.0 83000.0 No 9 France 37.0 67000.0 Yesデータの分離
関数の処理 pandas.coreの.iloc[]を使用してデータをスライスし、機能と出力されるものを決定します。
例:X = dataset.iloc [:3、:-1] //上位3行から切り取り、最後の列を削除します。
国の年齢給与
0 France 44.0 72000.0 1 Spain 27.0 48000.0 2 Germany 30.0 54000.0 また、データを処理するには、関数X = dataset.iloc [:3、:-1].valuesを使用してnumpy配列に変換する必要があります。
データの前処理
この記事で使用した概念のいくつかを次に示します。
- 欠測データの処理
- 標準化(標準分布)
- カテゴリ変数の処理
- ワンホットエンコーディング
- 多重共線性
1.欠落データの処理
世界のどの種類のデータセットでも、null値はほとんどありません。回帰や分類などのモデルやその他のモデルを使用する場合、これは実際には良くありません。注:Pythonでは、NULLはNANでも表されます。したがって、それらは交換可能に使用できます。
各列の要素をループして、どの列にisnull()およびprocessと同等のものがあるかを確認することにより、独自のコードを実装できます。
この例では、Sklearnライブラリを使用して、不足しているデータを簡単に処理する方法を示します。 SimpleImputerはSklearnのクラスであり、数値である欠落データの処理をサポートし、それらを列の平均、最も目に見えるデータの頻度などに置き換えます。
from sklearn.impute import SimpleImputer #Create an instance of Class SimpleImputer: np.nan is the empty value in the dataset imputer = SimpleImputer(missing_values=np.nan, strategy='mean') #Replace missing value from numerical Col 1 'Age', Col 2 'Salary' imputer.fit(X[:, 1:3]) #transform will replace & return the new updated columns X[:, 1:3] = imputer.transform(X[:, 1:3])
2.カテゴリーデータ処理
独立変数のエンコード:文字列を含む列をベクトル0および1に変換するのに役立ちます
- sklearnのColumnTransformerクラスとOneHotEncoderを使用します。
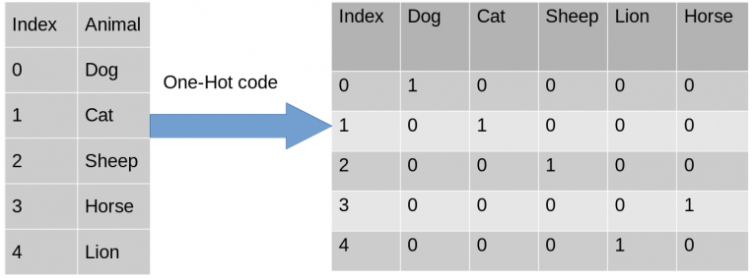
from sklearn.compose import ColumnTransformer from sklearn.preprocessing import OneHotEncoderタプル(「エンコーダー」エンコーディング変換、クラスOneHotEncoderのインスタンス、[列は変換したい)、および何もしたくない他の列を作成します。remainder="passthrough"を使用してそれらをスキップできます。
ct = ColumnTransformer(transformers = [('encoder'、OneHotEncoder()、[0])]、remainder = "passthrough")
input=XおよびクラスColumnTransformerのctインスタンスを使用して近似および変換します。
#fit and transform with input = X #np.array:fit_transform()の出力を行列からnp.arrayに変換する必要があります X = np.array(ct.fit_transform(X))
変換後、France = [1.0,0.0,0.0]が得られますが、これはすでにワンホットです。
従属変数のエンコード:つまり、マシンが理解できるように出力ラベルをエンコードする必要があります。
- ラベルエンコーダーを使用してラベルをエンコードする
sklearn.preprocessingインポートLabelEncoderから le = LabelEncoder() LabelEncoderのfit_transformの#outputはすでにNumpy配列です y = le.fit_transform(y) #y = [0 1 0 0 1 1 0 1 0 1]
トレーニングセットとテストセットの分割
- Sklearn-Model Selectionのtrain_test_splitを使用して、トレインとテストデータをスライスします。
- パラメータ:test_size = …を使用して、テストセットデータをすべてのデータに分割します。
- random_state = 1:Pythonの組み込みランダムセットの使用に役立ちます。
sklearn.model_selectionからimporttrain_test_split X_train、X_test、y_train、y_test = train_test_split(X、y、test_size = 0.2、random_state = 1)
機能のスケーリング
FSが発生する理由:データマイニングを実行する場合、他の機能よりも大きい機能がいくつかある可能性があるため、MLモデルを実行するときに小さな機能は確実に無視されます。
#注1:yが= b0 + b1 * x1 + b2 * x2 + … + bn * xnを予測すると(b0、b1、…、bn)になるため、FSを重回帰モデルに適用する必要はありません。 )は差を補正するための係数であるため、FSは必要ありません。
#注2:カテゴリカル機能エンコーディングの場合、FSを適用する必要はありません。

#注3:FSは、トレーニングセットとテストセットを分割した後に実行する必要があります。トレーニングセットとテストセットを分割する前にFSを使用すると、データの正確性が失われるためです。
では、スケーリングを特徴とする方法。
これを行うには2つの手法があります。
- 標準化:平均が0、標準偏差が1になるようにデータを変換します。
このデータでは、年齢と給与がまったく異なることがわかります。そのため、年齢データはモデルで使用されていない可能性があります。したがって、データを正規化してデータをより少ない数に減らし、それでもデータの相関を確保する必要があります。
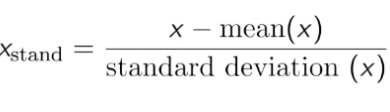
sklearn.preprocessingのStandardScalertoStdをデータに使用できます。
sklearn.preprocessingからインポートStandardScaler sc = StandardScaler() X_train [:、3:] = sc.fit_transform(X_train [:、3:]) #トレーニングセットとして同じスケーラーを使用するには、Transformのみを使用します X_test [:、3:] = sc.transform(X_test [:、3:])
- 正規化:データセットを0と1の間で変動させます。
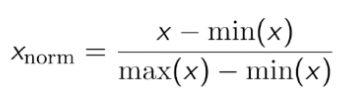
Bài viết liên quan:











Dịch vụ thiết kế Wesbite
