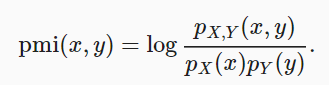
機械学習における特徴選択方法。
実際、すべてのデータが明確であるとは限りません。機能はモデルに役立ちます。たとえば、家の価格を予測したい場合、家主が男の子であるか女の子であるかは関係ありません。したがって、モデルに役立つ機能を選択することが非常に重要であり、入力データの次元数を減らすのに役立ちます。
基本的に、確率を使用して、各特徴と予測されるターゲットフィールドとの関係を計算します。しかし、そのアイデアは、機能が良くないことを決定するために任意の公式または尺度を使用することは、依然として素晴らしい知恵であるということです。この記事では、あなたと私はいくつかの式と計算を通して学びます!
Mục lục
特徴選択法
特徴選択アルゴリズムは、フィルターメソッド、ラッパーメソッド、埋め込みメソッドの3つのカテゴリに分類できます。
フィルター
この男には次の特徴があります。
- データの特性に依存します
- ラッパーメソッドや埋め込みメソッドよりもパフォーマンスが低下します。
- 方法:分散、相関、単変量選択、多変量選択。
一定、準一定、重複した機能について。
一定の機能:データセット内のすべての観測値に対して1つの値のみを表示します。
一定の機能を処理する最も簡単な方法。分散のしきい値(しきい値)を設定します。そのしきい値を満たさない機能は破棄されます。 (sklearnを使用して処理できます)
sklearn.feature_selectionからimportVarianceThreshold sel = VarianceThreshold(threshold = 0) #fitは、分散がゼロの特徴を見つけます。 sel.fit(X_train) #get_support()メソッドは、保持されている機能を返します。 保持された機能=sel.get_support()
これはブールシーケンスを返します。どの機能が条件を満たさないかを知るためにそれを見る必要があります。
準定数機能:上記の定数機能と同様に、しきい値を調整して条件をより厳密にすることができます(たとえば、しきい値= 0.01の場合、99%の値になると機能は削除されます)。
重複する機能:類似した機能です。たとえば、1つの元の機能と別の機能が元の機能のラベルエンコーダである場合、これら2つの機能は同等であり、1つの機能を削除できます。または複数の同一の行。
方法:
- 小さなデータセットの場合:パンダには、データフレームに重複した行が含まれているかどうかを評価する関数があります。列のチェックに関しては、引き続きduplicate()関数を使用し、行列を転置するだけです。
- 大きなデータセットの場合:大きなデータで転置を使用することは、間違いなく非常にメモリを消費し、実行可能ではありません。したがって、ループを使用して重複する列を検索したり、numpyライブラリを使用したりできます。
for_、idx = np.unique(df.to_numpy()、axis = 1、return_index = True) df_uniq = df.iloc [:、np.sort(idx)]
相関
2つ以上の変数間の相関を使用することも、相関の低い特徴を削除するための良い方法です。相関性の高い特徴を削除すると、線形モデルがより適切に機能し、特徴間のバイアスが回避されます。
- 相関の低いターゲットで機能をテストでき、機能を削除できます。
- または、2つの特徴の相関が高い場合は、特徴と特徴の相関を確認します。これら2つの特徴の情報が同じである場合は、1つの特徴を削除して、入力データの次元を減らすことができます。
相関係数の決定方法。
ピアソンの相関係数
sum((x1 -x1.mean)*(x2-x2.mean)*(xn-xn.mean))/ var(x1)* var(x2)* var(xn)
- ピアソンの係数の値は[-1,1]の範囲です。
- アイデアは、フィーチャ間の相関を計算することです。2つのフィーチャの相関が設定したしきい値よりも大きい場合、それらの2つのフィーチャの1つを削除します。
corrmat = X_train.corr()
#プロット
イチジク、ax = plt.subplots()
fig.set_size_inches(11,11)
sns.heatmap(corrmat)
defcorrelation(df、threshold):
col_corr = set()
corrmat = df.corr()
for i in range(len(corrmat.columns)):
range(i)のjの場合:
#絶対係数値に関心がある
abs(corrmat.iloc [i、j])>しきい値の場合:
col_corr.add(corrmat.columns [i])
col_corrを返します
corr_feats =correlation(X_train、0.8)
X_train.drop(labels = corr_feats、axis = 1、inplace = True)統計的測定
次のように、統計的手法に従って特徴を選択するためのいくつかの方法と基準があります。
- 情報獲得
- 単変量ROC-AUC/RSME
上記の各方法について、次の2つのステップがあります。
- 特定の基準に従って機能を評価します。各機能は、ターゲットとの関係を検討するときに、他の機能を個別に評価します。
- 上位の機能の選択:分類または回帰モデルを適用して、上位の機能を評価できますか?そしてもちろん、ランキングが高いか低いかを知る方法はあなた次第です。
いくつかの注意点:この手順を実行する前に、重複または相互に関連する機能を適用できます。また、この方法には、2つの機能を組み合わせることができるという大きな欠点があり、ターゲットに影響を与えます。この方法をタガートの観点から各機能にのみ適用すると、ミスが発生する可能性があります。したがって、機能とターゲットの間を評価するには、より多くの方法を適用する必要があります。
相互情報量(情報獲得)
この方法では、xとyが分布全体で同時に発生する確率を比較し、2つの分布が独立している場合と組み合わせます。
相互情報量=sum{i、y} P(xi、yj)* log(P(xi、yj)/ P(xi)* P(yj))xとyが独立している場合、相互情報量は0になります。
Pythonのライブラリを使用して機能を選択できます。
- 回帰モデルで
sklearn.feature_selection.mutual_info_regressionを使用します。 - そして、モデル分類で選択する
mutual_info_classif。
変数とターゲット間の相互情報量計算を実行します。各機能の相互情報量を返します。値が小さいほど、ターゲットに関するその機能に関する情報は少なくなります。 (この方法を適用する前に前処理を行うことをお勧めします)。
単変量ROC-AUC/RSME
アイデアは、各機能のROC-AUCを計算してから、機械学習モデルを使用してターゲットを予測することです。ここでは、決定木を使用して、ROC-AUCまたはRMSEに従って評価できます。そこから、メトリックの高い機能を選択します。
#bnp-paribasデータセットを使用 roc_vals = [] X_train.columnsの偉業のために: clf = DecisionTreeClassifier() clf.fit(X_train [feat] .fillna(0).to_frame()、y_train) y_scored = clf.predict_proba(X_test [feat] .fillna(0).to_frame()) roc_vals.append(roc_auc_score(y_test、y_scored [:、1]))
rocvals = pd.Series(roc_vals) rocvals.index = X_train.columns rocvals.sort_values(ascending = False) #機能の数は、ランダムよりも高いroc-auc値を示しています。 len(rocvals [rocvals> 0.5])
概要:
この研究を通じて、あなたと私は特徴選択のいくつかの方法を学び、入力次元の数を減らしてトレーニングモデルを簡単にしました。
Bài viết liên quan:











Dịch vụ thiết kế Wesbite
