機械学習におけるGDAとナイーブベイズ
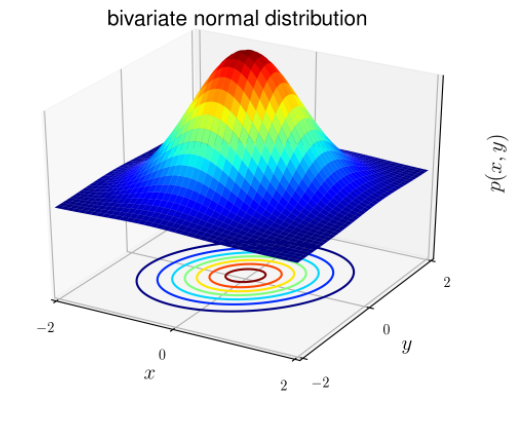
正規分布は、ガウス(ベル型)分布とも呼ばれます。分布の一般的な形式は同じですが、位置パラメーター(平均μ)と比率(分散σ2 )のみが異なります。
ガウス分布の形式は次のとおりです。

そこで:
- 平均ベクトル(予想): μ∈Rd
- 共分散行列: ∈Rdxd
分類問題の場合、xは連続ランダムであることが知られています(xが連続の場合、その可能な値は数直線X∈ (x min ; x max )の間隔を埋めます)ガウス弁別分析(GDA)モデルを使用できます:多くの変数の正規分布に基づいて確率P(x | y)を予測します。
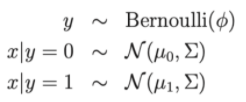
ディストリビューションとして書く:
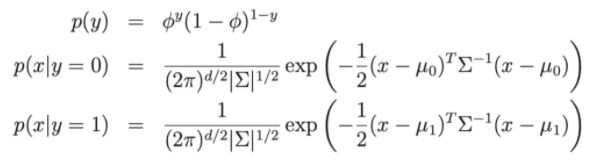
そこで:
- モデルパラメータ、、 μ0 、 μ1 。
- μ0 、 μ1は、x | y=0とx|y=1の2つの平均ベクトルです。
- モデルの損失関数:対数リンク
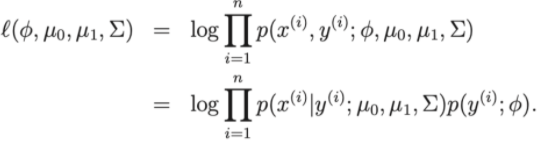
したがって、損失関数で極化するために、パラメータ、、 μ0 、 μ1を見つけることへの問題を減らすことができます。トレーニングデータセットの。
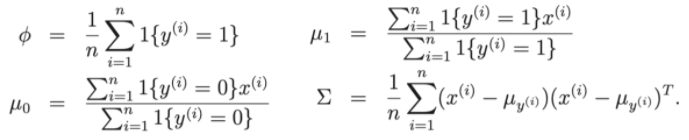
GDAとロジスティック回帰の間のいくつかの問題について説明しましょう。
p(y = 1 |∅、 Σ 、 μ0 、 μ1 )がxの関数である場合、式は次の形式になります。
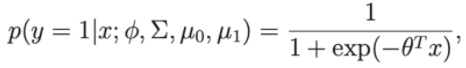
ここで、シータは、、 μ0 、 μ1の近似値です。
したがって、ロジスティック回帰アルゴリズムと同じ形式であることがわかります。
- したがって、p(x | y)の分布がガウス分布である場合、GDAは適切です。
- p(x | y)の分布がガウス分布でない場合、GDAの効率が低下する可能性があります。
Mục lục
単純ベイズ分類アルゴリズム
アルゴリズムが顧客を分類するか、電子メールをスパムまたは非スパムとして分類するとします。電子メールを辞書のサイズに等しい次元の特徴ベクトルとして表す場合。電子メールに辞書にj番目の単語がある場合はxj= 1、それ以外の場合はx j = 0です。単語ポイントのセットが5000語で構成されている場合、 x∈ {0、1} 5000 。したがって、分類器を作成する場合は、少なくとも2つ(50000-1)のパラメーターが必要であり、それは少数ではありません。
p(x | y)をモデル化するために、xiが独立していると仮定します。この仮定は、ナイーブベイズ(ナイーブ)と呼ばれます。アルゴリズムの結果は、単純ベイズ分類器です。
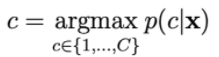
確率p(c | x)は次のように計算されます。
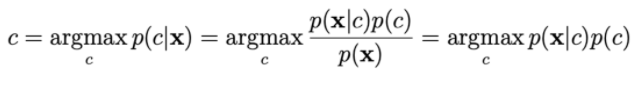
p(x | c)を計算するには、xiが独立しているという仮定に依存します。
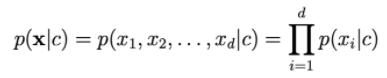
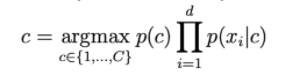
dが大きいほど、おはりの確率は低くなります。したがって、ログを拡大するには、右側のログを取得する必要があります。
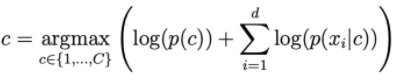
NBCで一般的に使用されるディストリビューション。
1.グアシアンナイーブベイズ:
各データ次元iとクラスcについて、xiは期待されるμciと分散σci2の正規分布に従います。
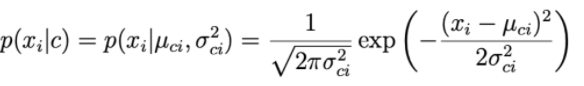
パラメータμciと分散σci2は、クラスcのトレーニングセット内の点に基づいて決定されます。
2.ベルヌーイナイーブベイズ
特徴ベクトルの成分は、値0または1をとる離散変数です。次に、p(xi | c)は次のように計算されます。
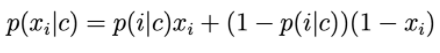
p(i | c)は、単語iがクラスcのテキストに現れる確率として理解できます。
3.多項ナイーブベイズ:
特徴ベクトルの成分は、ポアソン分布による離散変数です。
xがBow表現であるテキスト分類問題を想定します。
各ベクトルのi番目の要素の値は、テキスト内でi番目の単語が出現する回数です。
次に、p(xi | c)は、クラスcのドキュメントに単語iが出現する頻度に比例します。
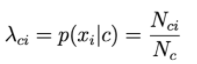
N ciは、クラスcのドキュメントにiが出現する合計回数です。
Ncは、クラスcに出現する単語の総数(繰り返しを含む)です。
4.ラプラススムージング。
クラスcに決して現れない単語がある場合、次の式の右に行く確率は=0になります。
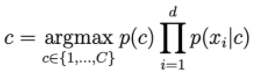
これを解決するために、ラプラス平滑化と呼ばれる手法が適用されます。
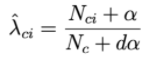
αが正の数である場合、通常、αは1に等しくなります。サンプルとdαは、合計確率を保証するのに役立ちます。したがって、各クラスcは、合計が1になる正の数のサブセットによって記述されます。
Bài viết liên quan:











Dịch vụ thiết kế Wesbite
