
機械学習の概要
Mục lục
なぜ機械学習を学ぶのですか?
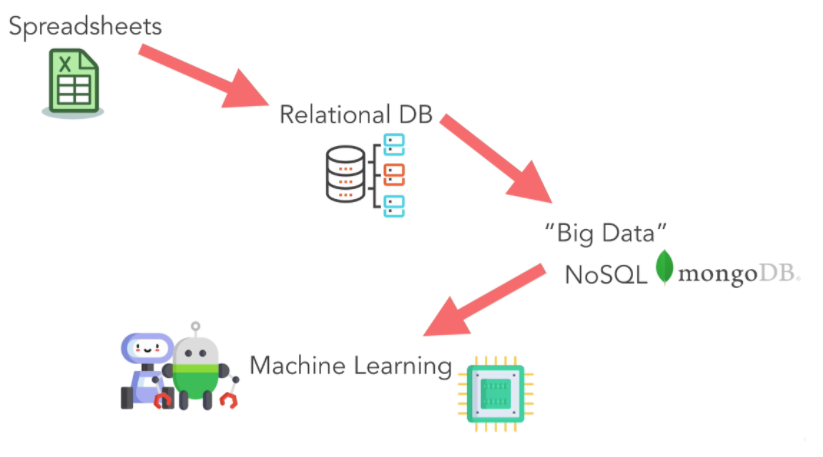
- スプレッドシート(Excel、CSV):必要なビジネスデータを保存する場所として、今日利用できる最も便利なツールの1つです。ビジネスに必要なデータの分析と表現に役立ちます。
- リレーショナルDB(MySQL):スプレッドシートよりも優れたデータストレージの場所であり、クエリステートメントを介して実行されます。クエリステートメントから、ビジネスはステートメントを使用してデータを検索および処理できます。
- ビッグデータ(NoSQL):FB、Amazon、Shopee、…ユーザーデータが大きいため、ビッグデータと呼ばれ、ここではデータが厳密に整理されていないため、子供ではなく機械学習を使用する必要があります。意思決定者。
機械学習に関連する分野がいくつかあります。
人工知能AI?
人工知能または人工知能(AI)は、コンピューターサイエンスの一分野です。コンピューターが人間のようなインテリジェントな動作を自動化するのを支援することを目的として、人間によって作成されたインテリジェンス。
機械学習
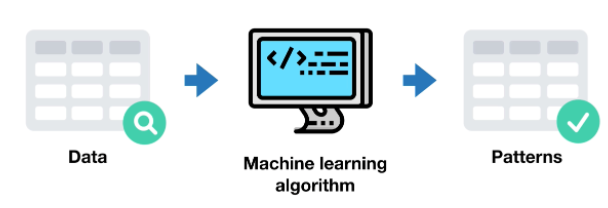
AIのサブブランチとして、機械学習はアルゴリズム( Algorithms )またはコンピュータープログラムを使用してさまざまなデータを学習し、アルゴリズムと以前に学習した内容を使用して予測を行います。同様のデータに基づいて推測または再分類します。
例:分類または製品分析。
機械学習と通常のアルゴリズムの違い
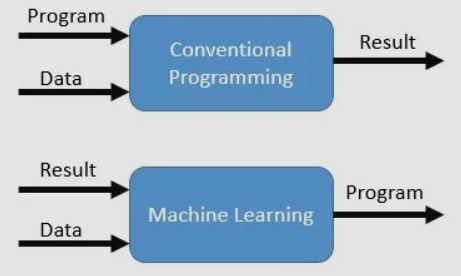
- 通常のアルゴリズム:入力+アルゴリズム->結果(出力)を使用します。
- マシンアルゴリズム:入力と出力から開始し、そこからI/PとO/Pの関係を決定します。
機械学習におけるいくつかの問題

監視あり:ラベルを含むデータ
例:犬と猫のデータのように、..。
教師なし:列ヘッダーのないExcelファイルのようなラベルのないデータ。
- クラスタリング:グループのクラスタリングに役立ちます。例:顧客の好みに応じて顧客をクラスタリングします。
- 相関ルール学習:複数の属性を関連付けて顧客の行動を予測します。例:将来何を購入するか。
強化:マシンに試して失敗するように教えてください。そうすれば、次回は改善するための報酬が得られます。例:alphagoで適用-世界的に有名なチェスマシン。
ディープラーニング
ディープラーニングは機械学習のサブセットであり、従来の浅い機械学習とはいくつかの重要な点で異なる可能性があり、コンピューターが解決できない複雑な問題を幅広く解決できるようにします。
データサイエンス
データ分析:そこからデータを分析して、必要なレポートを作成します。
データサイエンス:データセットに対してテストを実行して、そのデータに関する有用な情報を見つけます。
機械学習の仕組み

ステップ1 :問題を特定する-顧客の文章を機械学習の問題に変換します。
あなたはあなたの問題が何を解決する必要があるかを決定しなければなりませんか?
- 監視あり
- 監督されない
- 分類
- 回帰
ステップ2 :データ:既存のデータ型は何ですか?
ステップ3 :評価
- アルゴリズムがいつ正しいかを判断します。
- 注意が必要な指標は、プロジェクトの評価に役立ちます。
ステップ4:データ機能(機能)
- データにはどのような機能があり、モデルを構築するためにどの機能を使用する必要がありますか?そこから特徴をパターンに変えます。
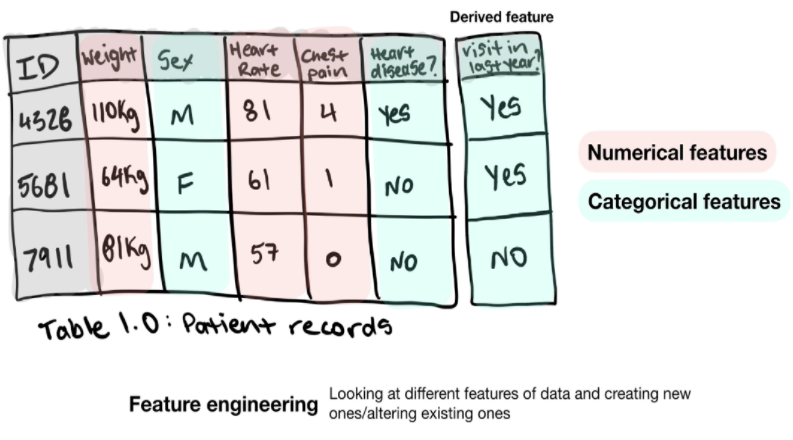
- 機能には主に3つのタイプがあります。
- カテゴリ機能:性別、またははい/いいえにすることができます。
- 連続(または数値)機能:メッセージスパンやアクションの実行回数などの数値。
- 派生機能(データから作成する機能のタイプ):多くの場合、機能エンジニアリングと呼ばれます。たとえば、初期データから速度と時間を取得すると、移動距離である派生フィーチャを作成できます。
ステップ5 :モデル
最近、問題の解決に役立つライブラリがたくさんあります。どのモデルをいつ使用するかを決定することが重要ですか?
- 教師あり学習:(入力と出力)データ+ラベル→分類、回帰モデル、..。
- 教師なし学習:入力のみ)データ→クラスタリング、..。
- 強化学習:完了とやりがい:MLスコアを更新する方法を見つける必要があります。
ステップ6 :テスト、評価。
モデルを確認し、アルゴリズムによる評価方法を使用して、モデルが正しいかどうか、およびモデルがどの程度正確かを確認してください。
| 分類 | 回帰 | おすすめ |
|---|---|---|
| 正確さ | 平均絶対誤差(MAE) | ケンタッキーでの精度 |
| 精度 | 平均二乗誤差(MSE) | |
| 想起 | 二乗平均平方根誤差(RMSE) |
機械学習処理におけるいくつかの一般的な問題。

過剰適合
トレーニングデータセットが適切で、テストデータが適切な場合、一般的なモデルは適切ではありません。
解決策:Haiは、より単純なモデルを使用して、テストデータがトレーニングデータと同じタイプであることを確認してください。
アンダーフィッティング
トレーニングデータのパフォーマンスが低いため、そもそもデータが適切に学習されていませんでした。アンダーフィットにつながります。
解決策:データトレーニングとデータテストを再度分割して、データのパラメーターを調整してみてください。
Bài viết liên quan:











Dịch vụ thiết kế Wesbite
