SQLServerのインデックス
アーキテクチャの概要
Mục lục
インデックスの紹介
インデックスは、クエリを高速化するためにテーブルまたはビューに関連付けられた特別なデータ構造です。簡単に言うと、テーブル内のフィールドにインデックスを付けると、そのフィールドの値が構造化された方法で整理および保存されるため、パフォーマンスと速度の点でデータをより効率的にクエリできます。 SQLServerの一般的なインデックスのリストは次のとおりです。
| インデックスタイプ | 説明 |
| クラスター化 | キーに基づいて、テーブルまたはビューのデータ行を並べ替えて保存します。 Bツリー構造に実装されたクラスター化インデックスは、キー値インデックスに基づいた行データの取得をサポートします |
| 非クラスター化 | 非クラスター化インデックスは、クラスター化された構造またはヒープにデータがあるテーブルまたはビューで削除されます。非クラスター化インデックスの各インデックス行には、キー値と行ロケーターが含まれています。ロケーターは、クラスター化されたインデックスまたはキーの値を持つヒープ内のデータの行を指します。インデックス内の行はインデックスキー値の順序で格納されますが、クラスター化インデックスがテーブルに作成されない限り、データ行が特定の順序であるとは限りません。 |
| 個性的 | 一意のインデックスにより、インデックスキーに重複する値が含まれないようになり、テーブルまたはビューの各行が何らかの方法で一意になります。 一意性は、クラスター化インデックスと非クラスター化インデックスの両方のプロパティになります。 |
| 列ストア | Index Columnstoreは、メモリ内の列ベースのデータストレージと列ベースのクエリ処理を使用してデータを格納および管理します インデックス列ストアは、データストレージワークロードが主に組み込みの読み込みキューと読み取り専用キューを実行する場合に機能します。インデックス列ストアを使用して、従来の行指向ストレージの最大10倍のクエリパフォーマンスと、非圧縮データサイズの最大8倍のデータ圧縮を実現します。 |
| フィルタリング | クラスター化インデックスは、明確に定義されたデータのサブセットから選択するクエリを含むように最適化されています。フィルタ述語を使用して、テーブル行の一部にインデックスを付けます。適切に設計されたフィルター処理されたインデックスは、フルテーブルインデックスと比較して、クエリパフォーマンスを向上させ、インデックスメンテナンスコストを削減し、インデックスストレージコストを削減できます。 |
| 空間的な | ジオメトリデータ型の列内の空間オブジェクトに対して、より効率的な操作を実行する機能を提供します。 |
| XML | XML列のサイズが大きいため、これらの列での検索クエリは遅くなる可能性があります。列ごとにXMLインデックスを作成することで、これらのクエリを高速化できます。 XMLインデックスは、クラスター化インデックスまたは非クラスター化インデックスにすることができます。 |
ハッシュ、メモリ最適化非クラスター化、列が含まれるインデックス、計算列のインデックス、フルテキストなどの他のタイプのインデックスもあります。
SQL Serverは、書籍のインデックス作成と同様のインデックスを使用します。たとえば、SQLラーニングブックですべての「INSERT」キーを検索する状況を考えると、すぐに実行できるアプローチは、開始ページから始まるブックの各ページをスキャンし、「INSERT」という単語を毎回ブックマークすることです。 「本の終わりまで、」が見つかりました。このアプローチには時間と労力がかかります。使用される2番目の方法は、本の目次を使用して、結果がINSERTについて説明しているページに移動し、そのページを見つけて使用することです。方法2の結果は方法1と同様ですが、時間と労力を節約できます。
SQL Serverがインデックスを定義しない場合、例の最初の方法のように動作します。SQLエンジンはデータベース内の各レコードにアクセスする必要があります。データベース用語では、この動作はテーブルスキャンまたは単にスキャンと呼ばれます。
テーブルスキャンは非効率的ではありませんが、特定の状況では、インデックスを使用してパフォーマンスを向上させる別のソリューションを使用する必要があります。これは、レコード数が増えるにつれてデータテーブルが大きくなるため、スキャンが遅くなり、リソースが増えるためです。 -集中的で、この状況では、インデックスが常に推奨されます。
データストレージの概要
本にはページが含まれ、内部には段落と文があり、SQLServerがデータページと呼ばれる単位でデータを格納するのと似ています。これらのページには、行にデータが含まれています。
本の各ページには物理的な寸法があります。同様に、SQL Serverでは、すべてのデータページのサイズは同じ8KBです。つまり、データベースには、1メガバイト(MB)のストレージスペースあたり128ページのデータが含まれています。
ページは96バイトのヘッダーで始まります。このヘッダーには、ページに関するシステム情報が格納されています。これには、次のものが含まれます。
- ページ数
- ページスタイル
- ページの空き容量
- アトリビューションページのオブジェクトのアトリビューションID
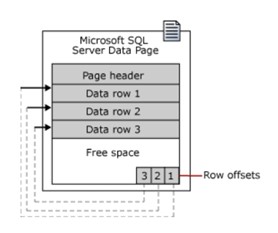
注:データページは、データストレージの最小単位です。アロケーションユニットは、ページタイプに基づいてグループ化されたデータページのコレクションです。グループ化により、データガバナンスがより効率的になります。
データファイル
データベース内のすべての入力タスクと出力タスクは、ページレイヤーで処理されます。これは、データベースエンジンがデータページの読み取りまたは書き込みを行うことを意味します。 8つの連続したページのセットはエクステントと呼ばれます。
SQL Serverは、データページをデータファイルと呼ばれるファイルに格納します。データファイルに割り当てられたスペースは、順番に配置されたデータページの数に分割され、ページは0から始まり、以下に示すように幾何学的表現になります。
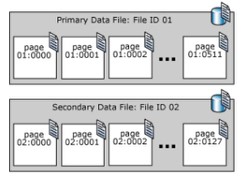
次のように説明される3つのデータファイルの3つのタイプがあります。
- プライマリ:メインファイルはデータベースの作成時に自動的に作成されます。このファイルには、データベース内の残りのすべてのファイルへの参照が含まれています。プライマリデータファイルの推奨されるデフォルトの拡張子は.mdfです。
- 二次:オプションのユーザー定義データファイルです。各ファイルを異なるドライブに配置することで、データを複数のドライブに分散させることができます。二次データファイルの推奨拡張子は.ndfです。
- トランザクションログ:ログファイルには、データベース内の変更履歴に関する情報が格納されます。この情報は、突然の停電やデータベースを別のサーバーに移動する必要があるなどのバックアップデータの回復に役立ちます。各データベースには少なくとも1つのログファイルがあります。ログファイルの推奨拡張子は.ldfです。
インデックスの要件
SQL Serverは、データベースからのデータの迅速な取得を容易にするために、インデックス作成機能を提供します。本の目次と同様に、SQL Serverデータベースのインデックスには、データ全体をスキャンせずに、一度に1つずつ正しくデータを検索できる情報が含まれています。テーブル。

索引
テーブルでは、レコードは入力された順序で格納され、ソートされずにデータベースに格納されます。つまり、入力履歴によってソートされます。テーブルからデータを取得するときは、テーブル全体をスキャンする必要があるため、プロセスが遅くなります。プロセスをスピードアップするために、インデックス作成と呼ばれる処理を実行します。
テーブルにインデックスが作成されると、レコードの並べ替えられたバージョンが作成され、検索中のデータの検索と取得が高速化されます。
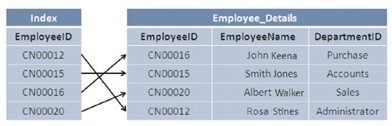
PRIMARY KEYおよびUNIQUE制約がテーブルで定義されると、インデックスが自動的に作成されます。インデックスを作成すると、ディスクの読み取りおよび書き込みタスクが削減され、システムリソースの消費が少なくなります。
構文:
CREATE INDEX <index_name> ON <table_name> (<column_name>)インデックスは、テーブルを検索する代わりに、データページ内のレコードの位置を指します。インデックスのいくつかの機能:
- インデックスは、テーブルを結合したり、並べ替えタスクを処理したりするクエリを高速化します。
- インデックスは、インデックスの作成時に定義されている場合、行の一意性を実装します。
- インデックスは、順方向および逆方向の並べ替えで作成および維持されます。
スクリプト
たとえば、電話帳では、頻繁に並べ替えられてアクセスされる大量のデータがあり、データはアルファベット順に保存されます。データがソートされていない場合、特定の電話番号をすばやく見つけることはほぼ不可能です。
同様に、多数のレコードがあり、頻繁にクエリを実行する必要があるデータベーステーブルでは、クエリを高速化するためにデータが並べ替えられます。テーブルのインデックスが作成されると、インデックスはレコードを物理的または論理的にソートします。したがって、指定されたレコードの検索が高速になり、システムリソースの負荷が軽減されます。
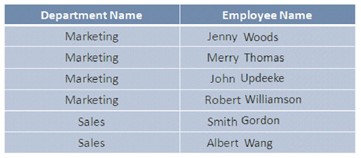
グループごとのアクセスデータ
インデックスは、データがグループでアクセスされるときに役立ちます。たとえば、データベースで担当者が作業している部門に基づいて、HRグループの部門を切り替える変更を作成するとします。この状況では、レコードにアクセスする前に、 DepartmentName列のインデックスを作成することができます。
このインデックスは、論理データフラグメントを作成し、レコードを部門にグループ化します。これにより、データ取得中に実際にスキャンされるデータの量が制限されます。
インデックスアーキテクチャ
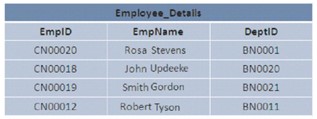
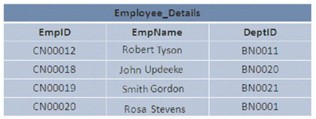
SQL Serverでは、データベース内のデータを特定の配置またはランダムな配置で格納できます。データが順序付けられた方法で格納されている場合、データはクラスター構造で表されていると言われます。データがランダムに格納される場合、それはヒープ構造と呼ばれます。
この画像は、2つのヒープ構造とクラスター構造を示しています。
Bツリー
SQL Serverでは、インデックスはBツリー構造で編成され、Bツリーインデックスの各ページはインデックスノードと呼ばれます。最上位ノードはルートノードと呼ばれます。インデックスの一番下のメモはリーフノードと呼ばれます。ルートノードとリーフノードの間のレイヤーは、中間ノードと呼ばれます。
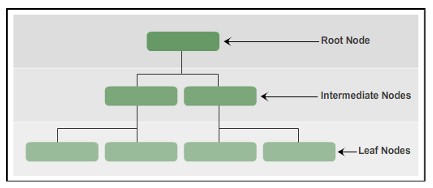
Bツリーインデックスは、ポインタによってノードの上部から下部に移動します。
Bツリーインデックス構造
インデックスのBツリー構造では、ルートノードにインデックスページが含まれます。インデックスページにはポインタが含まれており、最初の中間層を表すインデックスページを指します。これらのインデックスページは、次の中間レベルにあるインデックスページを指します。 Bツリーインデックスには複数の中間層が存在する可能性があります。 Bツリーインデックスのリーフノードには、レコードデータを含むデータページ、またはテーブル上のデータレコードを指すインデックスレコードを格納するデータページが含まれています。
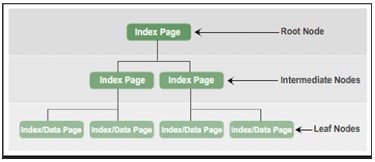
要約すると、Bツリーインデックスのノードタイプは次のとおりです。
- ルートノード:中間層のインデックスページへのポインタを含むインデックスページが含まれます。
- 中間ノード:中間層のインデックスページまたはリーフ層のインデックスページまたはデータページへのポインタを持つインデックスページが含まれます。
- リーフノード:データページまたはデータページを指すインデックスページが含まれます。
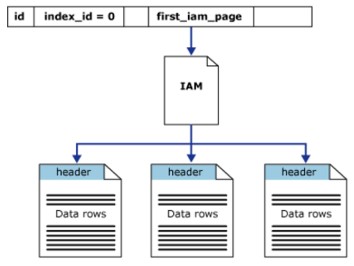
ヒープ構造
ヒープは、クラスター化されたインデックスのないテーブルです。これは、ヒープ構造では、データページとレジスタがソートされていないことを意味します。データページ間の唯一のリンクは、インデックス割り当てマップ(IAM)ページに記録されている情報です。
データ構造のヒープ構造という用語の詳細については、https: //en.wikipedia.org/wiki/%C4%90%E1%BB%91ng_(c%E1%BA%A5u_tr%C3%BAc_d%E1%BB% AF_li%E1%BB%87u)#:〜:text = In%20khoa%20h%E1%BB%8Dc%20m%C3%A1y%20t%C3%ADnh、%C4%91%C6%B0%E1%BB %A3c%20g%E1%BB%8Di%20l%C3%A0%20max%2ヒープ。
ヒープにはsys.partitionsに行があり、ヒープによって使用される各パーティションのindex_id=0です。デフォルトでは、ヒープには独自のパーティションがあります。ヒープに複数のパーティションがある場合、各パーティションには、定義されたデータを保持するヒープ構造があります。たとえば、ヒープには4つのパーティションがあり、それぞれがパーティション内に4つのヒープ構造があります。
少なくとも、各ヒープには、パーティションユニットごとに1つのIN_ROW_DATAが割り当てられます。ヒープにラージオブジェクト(LOB)列が含まれている場合、ヒープにはパーティションユニットごとにLOB_DATAも割り当てられます。また、パーティション単位ごとにROW_OVERFLOW_DATAが割り当てられます。既知の長さの列が含まれていない場合、最大サイズ制限は8060レコードです。
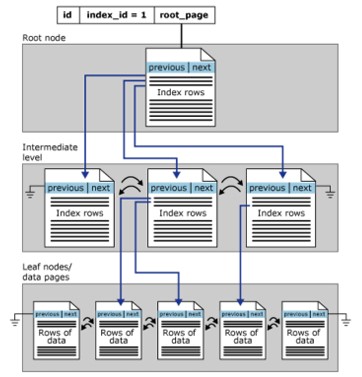
クラスター化されたインデックス構造
クラスター化インデックスは、Bツリー形式で編成されています。 Bツリーインデックスの各ページは、インデックスノードと呼ばれます。概念的には、クラスター化されたインデックスの最上位ノードもルートノードであり、最下位ノードはリーフノードです。
- リーフノードにはテーブルの基本データページが含まれ、ルートレイヤーと中間レイヤーにはインデックス行を保持するインデックスページが含まれます。各インデックスには、キー値と、Bツリーの中間ページまたはインデックスのリーフレイヤーのデータ行へのポインターが含まれています。
- デフォルトでは、クラスター化されたインデックスには単一のパーティションがあります。クラスター化インデックスに複数のパーティションがある場合、各パーティションは、指定されたパーティションの値を含むBツリー構造になります。
- クラスタ化インデックスには、LOB列(ラージオブジェクト)内に含まれている場合、各パーティションに割り当てられたLOB_DATAもあります。また、各単一パーティションにROW_OVERFLOW_DATA割り当てがあります。
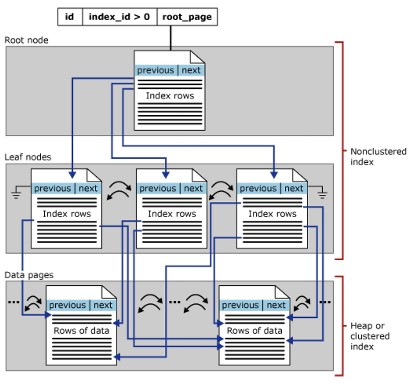
非クラスター化インデックス構造
非クラスター化インデックスは、クラスター化インデックスと同じBツリー構造を持ちますが、次の違いがあります。
- テーブルのデータ行は、区別されていないキーによって決定された順序で物理的に格納されません。
- 非クラスター化インデックス構造では、リーフレイヤーにインデックス行が含まれます。
- 非クラスター化インデックスは、データを見つけるために複数の方法が必要な場合に役立ちます。
- クラスター化インデックスが再作成されるか、DROP_EXISTINGオプションが使用されると、SQLServerは既存の非クラスター化インデックスを構築します。
- テーブルには、最大888個の非クラスター化インデックスを含めることができます
- 非クラスター化インデックスを作成する前に、クラスター化インデックスを作成します。
列ストアインデックス(列ストアインデックス)
列ストアインデックスは、列ストアと呼ばれる列データを使用してデータを格納、取得、および管理することを目的としたSQLServerの機能です。
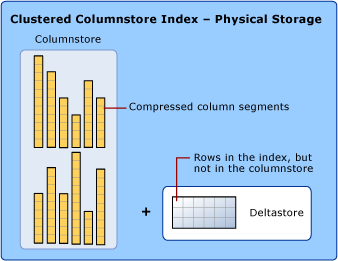
列ストアインデックスは、行ストア形式と列ストア形式の2種類のデータストレージを使用します。
コロンストアインデックスは、主に次の理由で使用されます。
- ストレージコストの削減
- 性能を上げる
列ストア、行ストア、デルタストア形式の詳細は次のとおりです。
- 列ストア:データは、列グループデータ形式で物理的に格納された行と列を持つテーブルに論理的に編成されます。
- 行ストア:データは、行と列を含むテーブルとして論理的に編成され、行グループデータ形式で物理的に格納されます。
- Deltastore :列ストアに圧縮するにはデータが少なすぎる場合に行の位置を保持します。 Deltastoreは、行を行ストア形式で格納します。
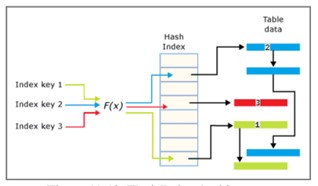
HashIndex
ハッシュインデックスはポインタの配列で構成され、配列内の各要素はハッシュバケットと呼ばれます。
- 各バケットのサイズは8バイトで、キーのメモリ位置をリンクリストエントリ構造に格納するために使用されます。
- 各エントリは、メモリ最適化テーブルの行の対応するアドレスであるインデックスキーの値です。
- 各エントリは、リンクリストエントリ内の次のエントリを指します。これらのエントリはすべてチェーンされています(現在のバケットへのチェーンロックとして解釈できます)。
バケットの数は定義時に定義する必要があり、次のプロパティのいくつかがあります。
- 短いリストリンクは、長いリストリンクよりも高速に処理されます。
- ハッシュインデックスには、最大で1,073,741,824個のバケットを含めることができます。
ドキュメント: https ://docs.microsoft.com/en-us/sql/relational-databases/in-memory-oltp/indexes-for-memory-optimized-tables?view = sql-server-ver16
XMLインデックス
XMLデータ型の列に対してXMLインデックスを作成できます。これらは、列内のXMLインスタンス内のタグ、値、およびパスにインデックスを付け、クエリのパフォーマンスを向上させます。次の場合、アプリケーションにはXMLインデックスを使用する利点があります。
XML列クエリはワークロードで一般的です。データの変更中にインデックスxmlを維持するためのリソースコストを考慮する必要があります。
XML値が比較的大きく、アクセスされる部分が比較的小さい場合、インデックスの構築により、実行時にデータ全体を解析する必要がなくなり、クエリ処理のインデックスルックアップに役立ちます。効果的です。
XMLインデックスには次の2つのタイプがあります。
- プライマリXMLインデックス
- セカンダリXMLインデックス
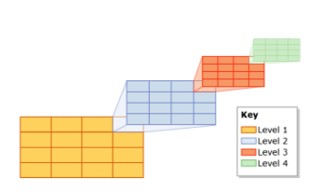
空間インデックス(空間インデックス)
SQL Serverでは、空間インデックスはBツリーを使用します。つまり、インデックスはBツリーの線形配置で2つの空間次元で表す必要があります。したがって、空間インデックス内のデータを読み取る前に、SQLServerは均一な階層空間階層化モデルを実装します。インデックス作成プロセスは、スペースを4レベルのグリッド階層に分割します。
全文索引
フルテキストインデックスの作成と維持には、クロールとも呼ばれる集約と呼ばれるプロセスを使用したインデックス作成が含まれます。
情報収集の種類:
- 全人口
- 変更追跡に基づく自動/手動入力
- タイムスタンプで激しい人口増加
クラスター化されたインデックスの作成
CREATE CLUSTEREDインデックスステートメントを使用すると、ユーザーは指定された列とテーブルのCLUSTEREDインデックスを作成できます。
構文:
CREATE CLUSTERED INDEX index_name ON table_name (column1,column2,...);例えば:
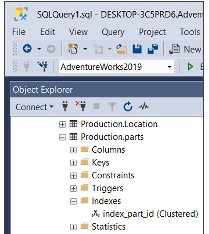
USE AdventureWorks2019 CREATE TABLE Production.Parts( part_id INT NOT NULL, part_name VARCHAR(100) ) CREATE CLUSTERED INDEX ix_parts_id ON Production.parts (part_id);インデックスの名前変更
sp_renameは、テーブル、インデックス、列など、現在のデータベースでユーザーが作成したオブジェクトの名前を変更できるシステムストアドプロシージャです。
構文:
EXEC sp_rename index_name,new_index_name, N'INDEX';例えば:
EXEC sp_rename N'Production.parts.ix_parts_id', N'index_part_id',N'INDEX';または、オブジェクトエクスプローラーのインデックスを右クリックして、名前の変更オプションを選択します
インデックスを無効にする
インデックスを無効にするには、 ALTERINDEXステートメントを使用します。
構文
ALTER INDEX index_name ON table_name DISABLE;例えば:
ALTER INDEX index_part_id ON Production.Parts DISABLE; select * from Production.Partsインデックスを無効にした後、データをクエリするとエラーが発生します。
The query processor is unable to produce a plan because the index 'index_part_id' on table or view 'Parts' is disabled.インデックスを有効にする
索引付けを有効にするには、 ALTERINDEXステートメントを使用します。
構文:
ALTER INDEX index_name ON table_name REBUILD;例えば:
ALTER INDEX index_part_id ON Production.Parts REBUILD;ドロップインデックス
DROP INDEXステートメントは、現在のデータベースからインデックスを削除します。
構文:
DROP INDEX [IF EXISTS] index_name ON table_name;例えば:
DROP INDEX IF EXISTS index_part_id ON Production.Parts;非クラスター化インデックス
非クラスターインデックスは、テーブルからデータを取得する速度を向上させるデータ構造です。クラスター化インデックスとは異なり、非クラスター化インデックスは、テーブル内のデータ行からデータを断片的に並べ替えて格納します。
構文:
CREATE [NONCLUSTERED] INDEX index_name ON table_name(column1,column2,...);例えば:
CREATE NONCLUSTERED INDEX index_customer_storeid ON Sales.Customer(StoreID);ユニークインデックス
一意のインデックスにより、indexkey列に重複する値が含まれないようにします。
1つ以上の列を含めることができます。一意のインデックスに1つの列がある場合、列の値は一意になります。多数の列を持つ一意のインデックスの場合、これらの列の値の組み合わせは一意になります。
注:一意のインデックスは、クラスター化することも非クラスター化することもできます。
一意のインデックスを作成するための構文:
CREATE UNIQUE INDEX index_name ON table_name(column_list);例えば:
CREATE UNIQUE INDEX AK_Customer_rowguid ON Sales.Customer(rowguid);フィルタリングされたインデックス
フィルタされたインデックスは、どの行がインデックスに追加されるかを決定できる非クラスター化インデックスです。
構文:
CREATE INDEX index_name ON table_name(column_list) WHERE predicate;例えば:
CREATE INDEX index_cust_personID ON sales.Customer(PersonID) WHERE PersonID IS NOT NULL;パーティション化されたテーブルとインデックス
ドキュメント: https ://docs.microsoft.com/en-us/sql/t-sql/statements/create-partition-function-transact-sql?view = sql-server-ver16
SQL Serverは、2種類のテーブルとインデックスパーティション(パーティション)をサポートしています。パーティション化されインデックスが作成されたテーブルのデータは、データベース内の複数のファイルグループにまたがることができるオプションのユニットに分割されます。データは水平方向にパーティション化されるため、マップされた(結合された)行は個別のパーティションにグループ化されます。単一のテーブルまたはインデックスのすべてのパーティションは、同じデータベース上にある必要があります。テーブルまたはインデックスは、データをクエリまたは更新するときにオブジェクトとして扱われます。
SQL Seerver 2019は、デフォルトで最大15,000のパーティションをサポートします。
パーティション分割の利点:
- データを迅速かつ効率的に変換またはクエリします。
- 1つ以上のパーティションで永続化タスクを処理する場合、タスクのターゲットはテーブル全体ではなく、パーティション上のデータセットのみにあるため、タスクはより効率的です。
- クエリのパフォーマンス、頻繁に実行するクエリの種類に関するデータ、およびハードウェア構成を向上させます。
この例では、次の情報を使用してサンプルテーブルを作成します。
CREATE TABLE testing_table(receipt_id BIGINT, date DATE)テーブルがどの程度正確にパーティション化されるかを指定します。この場合は、日付列と
値の範囲が各パーティションに追加されます。パーティションの境界については、LEFTまたはRIGHT(左側または右側)を指定できます
CREATE PARTITION FUNCTION partition_function (int) AS RANGE LEFT FOR VALUES (20200630,20200731,20200831);これは、次のように4つのパーティションに分割されることを意味します。
- パーティション1:日付<=2020-06-30のすべてのレコード
- パーティション2:日付>2020-06-30および日付<=2020-07-31のすべてのレコード
- パーティション3:日付>2020-07-31および日付<=2020-08-31のすべてのレコード
- パーティション4:日付が2020-08-31を超えるすべてのレコード
以下のコードを使用すると、各レコードが配置されている地域のファナを識別できます。
(SELECT 20200613 date, $PARTITION.partition_function(2020613) AS PartitionNumber) UNION (SELECT 20200713 date, $PARTITION.partition_function(2020713) AS PartitionNumber) UNION (SELECT 20200813 date, $PARTITION.partition_function(20200813) AS PartitionNumber) UNION (SELECT 20200913 date, $PARTITION.partition_function(20200913) AS PartitionNumber)
XMLインデックス
XMLデータは、ラージバイナリオブジェクト(BLOB)と呼ばれる大量のサイズを消費するデータ型であるデータ型XMLの列型に格納されます。
xmlデータを表すために、データ型のサイズは最大2GBにすることができます。
XMLインデックスは、xmlデータを含む列に作成され、テーブルとデータベースに保存されます。
例えば:
CREATE PRIMARY XML INDEX PXML_PRoduct_Model_Catalog_Description ON Production.ProductModel (CatalogDescription);プライマリXMLインデックスには、XML列のすべてのデータが含まれます。 XMLクエリのパフォーマンスを向上させるために、セカンダリインデックスを追加できます。セカンダリXMLインデックスも、基になるプライマリインデックスであるため同じデータセットを使用しますが、プライマリインデックスに基づいてより具体的なインデックスを作成します。
例えば:
CREATE XML INDEX IXML_ProductModel_CatalogDescription_Path ON Production.ProductModel (CatalogDescription) USING XML INDEX PXML_ProductModel_CatalogDescription FOR PATH;列ストアインデックス
構文:
CREATE COLUMNSTORE INDEX IX_SalesOrderDetail_ProductIDOrderQty_ColumnStore ON Sales.SalesOrderDetail (ProductID,OrderQty);このインデックスを作成すると、集計関数を使用するときにクエリごとのグループが改善されますが、現在SSMSでこのコマンドタイムアウトエラーが実行されているため、環境で再度テストしてください。
SELECT ProductID,SUM(OrderQty) FROM Sales.SalesOrderDetail GROUP BY ProductId;
Bài viết liên quan:


Dịch vụ thiết kế Wesbite

