
K-fold検証を使用して、モデルをより効果的に評価します。
トレーニングモデルは、使用するモデルに依存するだけでなく、データの量など、他の多くのことも含みます。適度なデータセットは、必然的に非効率的なモデル評価につながります。したがって、K分割交差検定は、それを処理するのに役立つ非常に優れたトリックです。
Mục lục
データが少ないモデルを評価するとどうなりますか?
確かに、誰もが列車、検証、テストデータを分割する方法に精通していますか?
今のところ、トレーニングセットとvalセットだけを気にする必要があります。テストセットでは、トレーニングの完了後にモデルを評価して、モデルが実際にデータをどのように処理するかを確認できます。
通常、train / valを80/20の比率で分割することがよくあります(trainデータの80%、テストデータの20%)。このような分割は、データが大きい場合に非常に適しています。小さなデータに関しては、それは間違いなくあなたのモデルのパフォーマンスを低下させます。トレーニングプロセスに役立つデータの一部が検証とテストのためにスローされたため、モデルはそのデータから学習できません。データがランダムであることが保証されていない場合は言うまでもなく、一部のラベルは検証とテストには存在しますが、トレーニングセットには存在しません。そしてもちろん、その結果に基づいてモデルを評価することは良くありません。彼は数学を勉強しなかったが、機械学習を学ばせたようです。
次に、K分割交差検定が必要です。
K相互検証とは何ですか?
K-Flod CVは、トレーニングセットが大きくない場合に、モデルをより完全かつ正確に評価するのに役立ちます。
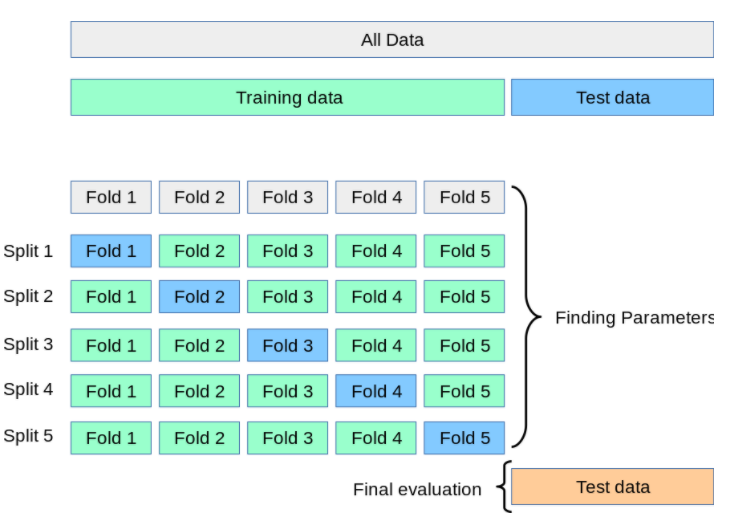
トレーニングデータ部分はK個の部分に分割されます(Kは整数であり、10を選択するのが難しいことがよくあります)。次に、モデルをK回トレーニングします。そのたびに、トレインは検証データとして1つのパーツを選択し、K-1サブパーツがトレーニングセットになります。最終結果は、K回のトレーニング時間の評価結果の平均になります。これが、この評価がより客観的である理由でもあります。
評価が完了し、「許容可能な」レベルの精度が見つかったら、テストデータセットのみを使用して予測に進みます。
Kerasで練習する
さて、基本的な理論は終わりました。さあ、練習しましょう!練習のために、常にkerasのCIFAR10データセットを使用します。
ライブラリをインポートします。
from tensorflow.keras.datasets
import cifar10
from tensorflow.keras.models
import Sequential from tensorflow.keras.layers
import Dense, Flatten, Conv2D, MaxPooling2D from sklearn.model_selection
import KFold import numpy as np
データをロードする関数を記述します。
def load_data():
# Load dữ liệu CIFAR đã được tích hợp sẵn trong Keras
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# Chuẩn hoá dữ liệu
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_test = X_test / 255
X_train = X_train / 255 # Do CIFAR đã chia sẵn train và test nên ta nối lại để chia K-Fold
X = np.concatenate((X_train, X_test), axis=0)
y = np.concatenate((y_train, y_test), axis=0)
return X, y
Kerasでモデルを構築する
def get_model():
model = Sequential()
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(no_classes, activation='softmax')) # Compile model
model.compile(loss="sparse_categorical_crossentropy", optimizer="Adam", metrics=['accuracy'])
return model
また、SklearnのKFoldライブラリを使用して共有します
kfold = KFold(n_splits=num_folds, shuffle= True )
# K-fold Cross Validation model evaluation
fold_idx = 1
for train_ids, val_ids in kfold.split(X, y):
model = get_model()
print ("Bắt đầu train Fold ", fold_idx)
# Train model
model.fit(X[train_ids], y[train_ids], batch_size=batch_size, epochs=no_epochs, verbose=1) # Test và in kết quả
scores = model.evaluate(X[val_ids], y[val_ids], verbose=0) print ("Đã train xong Fold ", fold_idx) # Thêm thông tin
accuracy và loss vào list accuracy_list.append(scores[1] * 100) loss_list.append(scores[0]) # Sang Fold tiếp theo
fold_idx = fold_idx + 1
KFoldを使用して、各フォールドでトレインインデックスセットとvalインデックスセットを取得し、そのインデックスセットに従って要素をtrain、valに抽出してより適切にするという考え方です。精度と損失の結果は、平均を表示するためにリストに保存されます。
まとめ
列車セットとvalセットを使用してモデルを対面で評価する代わりに、K-FoldCVを使用してモデルをより効率的に評価することができました。 K-Fold CVの他に、Stratified K-Foldを試すことができますが、K-Fold CVの拡張であるため、これは優れています。
Bài viết liên quan:










Dịch vụ thiết kế Wesbite
