SQLServer2019のSQLの高度な機能
Mục lục
詳細な切り捨て警告(詳細な切り捨て警告)
これは、SQLServer2019で提供される新しい拡張機能の1つです。レポート作成、新規追加、大量のデータの更新にかかる時間を節約できます。
例えば:
ステップ1-サンプルDB2017を作成する
USE [master] GO CREATE DATABASE [SampleDB2017] GO ALTER DATABASE [SampleDB2017] SET COMPATIBILITY_LEVEL = 140 GOステップ2-上記のデータベースにいくつかのレコードテーブルを追加します
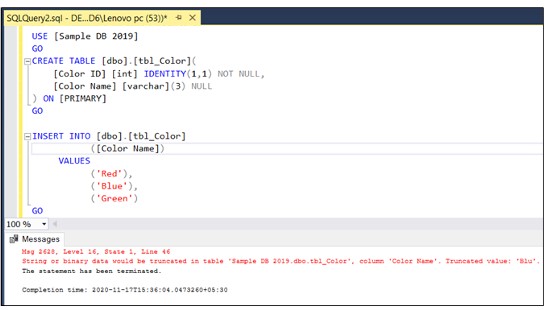
USE [SampleDB2017] GO CREATE TABLE [dbo].[tbl_Color]( [ColorID] int IDENTITY not null, [ColorName] varchar(3) NULL ) GO INSERT INTO dbo.tbl_Color (ColorName) values ('Red'), ('Blue'),('Green') GO古いバージョンでは、エラーは次のように返されます。
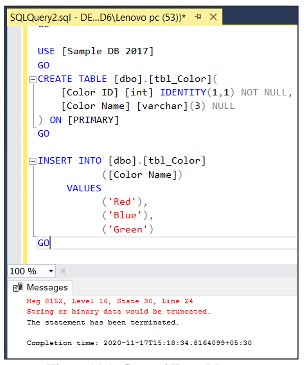
エラーが表示されていても、レコード’Green’がnvarchar(3)データの列に挿入されるとエラーが発生しますが、レコード数が多いと、どのレコードを挿入するときにどのエラーが発生したかを判断するのが困難になります。 、セッションバージョン2019では、エラーメッセージが修正され、より詳細に表示されるため、エラーの識別が容易になります。
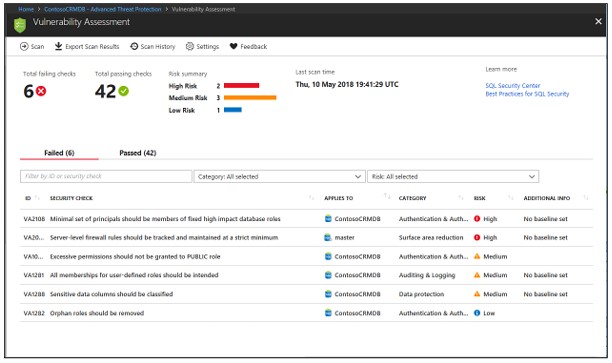
脆弱性評価
これは、データベースの脆弱性を発見、逆転、または削減する、構成が容易なビジネスです。
データベース管理者はこれを使用して、データベースのセキュリティを積極的に開発できます。
脆弱性アセットは、高度なSQLセキュリティ機能の統合パッケージであるAzure DefensiveforSQLの一部です。これは、SQLポータル用のAzureDefenderを介してアクセスおよび管理できます。
Azure SQL Database、Azure SQLマネージドインスタンス、Azure Synapse Analytics(SQLデータウェアハウス)で使用されるSQLの脆弱性に注意してください。
SQL Vulnerability Assetには、データベースのセキュリティを向上させるための手順が含まれており、次のことに役立ちます。
- データベーススキャンレポート要件でコンプライアンス要件を満たす
- データプライバシー基準を満たす
- 変更の追跡が困難な動的データベース環境を監視する
ルールはMicrosoftのベストプラクティスに基づいており、データベースとその貴重なデータに最大のリスクをもたらすセキュリティの問題に焦点を当てています。スキャンの結果には、各問題を解決し、適切なカスタム修復シナリオを提供するための実用的な手順が含まれています。
次のベースラインを設定することにより、環境の脆弱性レポートをカスタマイズできます。
- 権限を構成する
- 機能構成
- データベース設定
脆弱性評価を展開する手順:
スキャンを実行する
注:スキャンプロセスは軽量で安全です。数秒で読み取り専用になります。スキャンプロセス全体で、データベースに変更はありません。
レポートを表示
スキャンが終了すると、レポートはAzureポータルに自動的に表示されます
結果には、データベースの役割やガイドライン、権限などのセキュリティ関連の設定のベストプラクティスやスナップショットからの逸脱に関する警告、およびそれらの関連性が含まれます。
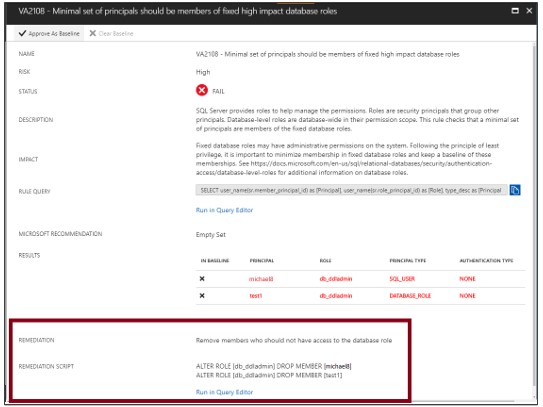
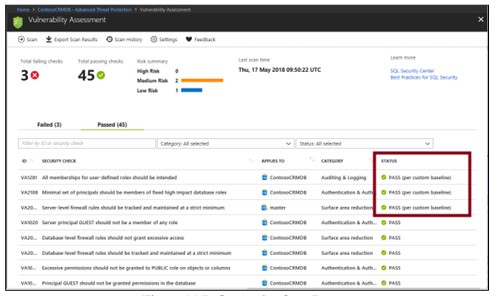
結果を分析し、問題を解決します
結果を再度確認し、環境に問題があるかどうかをレポートで特定します。
各失敗の結果を詳しく調べて、検出の影響と、各セキュリティチェックが失敗する理由を理解します。
レポートによって提供される実用的な修復情報を使用して、問題を解決します。
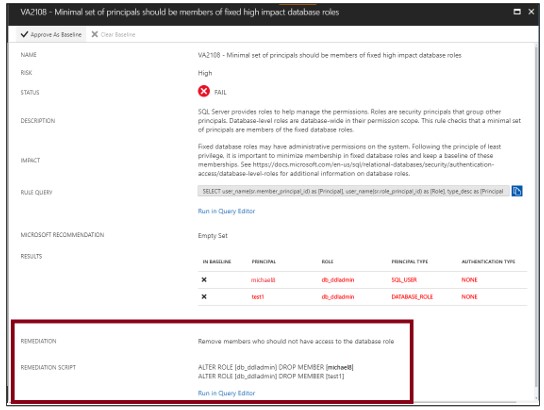
ベースラインを設定する
評価結果を確認するときに、特定の結果を許容可能なベースラインとしてマークできます。ベースラインに一致する結果は、後続のスキャンで合格と見なされます。ベースラインセキュリティを確立した後、脆弱性評価はベースラインからの逸脱のみを報告します。
ベースラインに一致する結果は、後続のスキャンで合格と見なされます。セキュリティベースラインの日付を設定した後、脆弱性評価はベースラインからの逸脱のみを報告します。
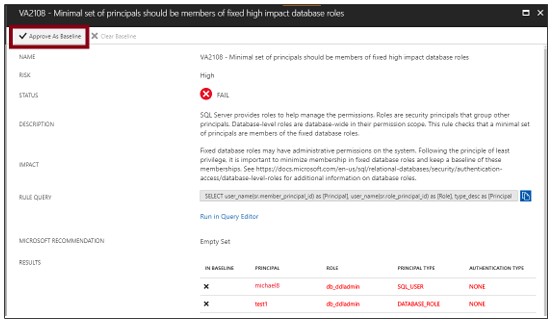
新しいスキャンを実行して、カスタム追跡レポートを確認します。
ルールベースラインをインストールした後、スキャンを実行してカスタムレポートを確認します。脆弱性評価では、承認されたベースラインから逸脱したセキュリティ問題のみが報告されます。
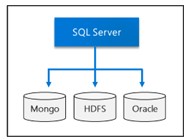
ビッグデータクラスター
SQL Server 2019では、ビッグデータクラスターにより、SQL Server、Spark、およびHadoop分散ファイルシステム(HDFS)のスケーラブルクラスターを展開できます…
ビッグデータクラスターは主に次の目的で使用されます。
- Kubernetes上で実行されるスケーラブルなSQLServer、Spark、およびHDFSコンテナークラスターをデプロイします。
- T-SQLまたはSparkSQLからのビッグデータの読み取り、書き込み、処理。
- 大きな価値のあるリレーショナルデータと大きな価値のあるビッグデータを簡単に組み合わせて分析します。
- 外部データソースをクエリします。
- SQLServerが管理するHDFSにビッグデータを保存します。
- クラスタを介して複数の外部データソースからデータをクエリします。
- AI、ML、またはその他の分析タスクにデータを使用します。
- ビッグデータクラスターにアプリケーションをデプロイして実行し、PolyBaseを使用してデータを仮想化します。
- 外部SQLServer、Oracle Teradata、MongoDB、外部テーブルを使用したODBCデータソースからデータをクエリします。
- Always On可用性テクノロジファミリを使用して、SQLServerの主要なインスタンスとすべてのデータベースに高可用性を提供します。
データ仮想化(データ仮想化)
SQL Serverビッグデータクラスターは、データを移動またはコピーすることなく、外部データソースをクエリできます。
データレイク
データレイクは、ネイティブ形式で大量の生データを保持するコンテナストアです。
これは、スケーラブルなHDFSストレージプールです。
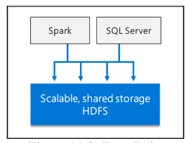
スケールアウトデータマート
大規模なコンピューティングとストレージを提供して、データ分析のパフォーマンスを向上させます。
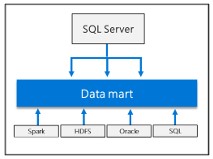
AIと機械学習の統合
HDSFストレージプールとデータプールに保存されたデータを使用して、AIと機械学習タスクを実行できます。
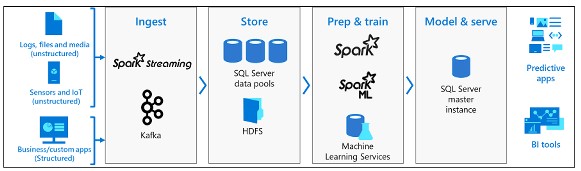
SQL Serverビッグデータクラスターは、KubernetesプラットフォームによってホストされるLinuxコンテナーのクラスターです。
Kubernetesという用語
Kubernetesは、必要に応じてコンテナのデプロイを拡張できるオープンソースのコンテナオーケストレーションです。いくつかの重要なKubernetes用語:
| 条項 | 説明 |
| 集まる | Kubernetesクラスターはマシンのコレクションであり、ノードとして理解されます。1つのノードがクラスターを制御し、それをマスターノードとして指定し、残りのノードはワーカーノードです。 Kubernetesマスターは、ワーカー間で作業を分散し、クラスターの状態を監視する責任があります。 |
| ノード | アプリケーションを実行するノードは、コンテナー内に含まれています。物理マシンでも仮想マシンでもかまいません。 Kubernetesクラスタには、物理ノードと仮想マシンノードの両方を含めることができます。 |
| ポッド | ポッドは、Kubernetesのアトミック実装です。バケットは、1つ以上のコンテナーと必要な関連リソースの論理グループです。 |
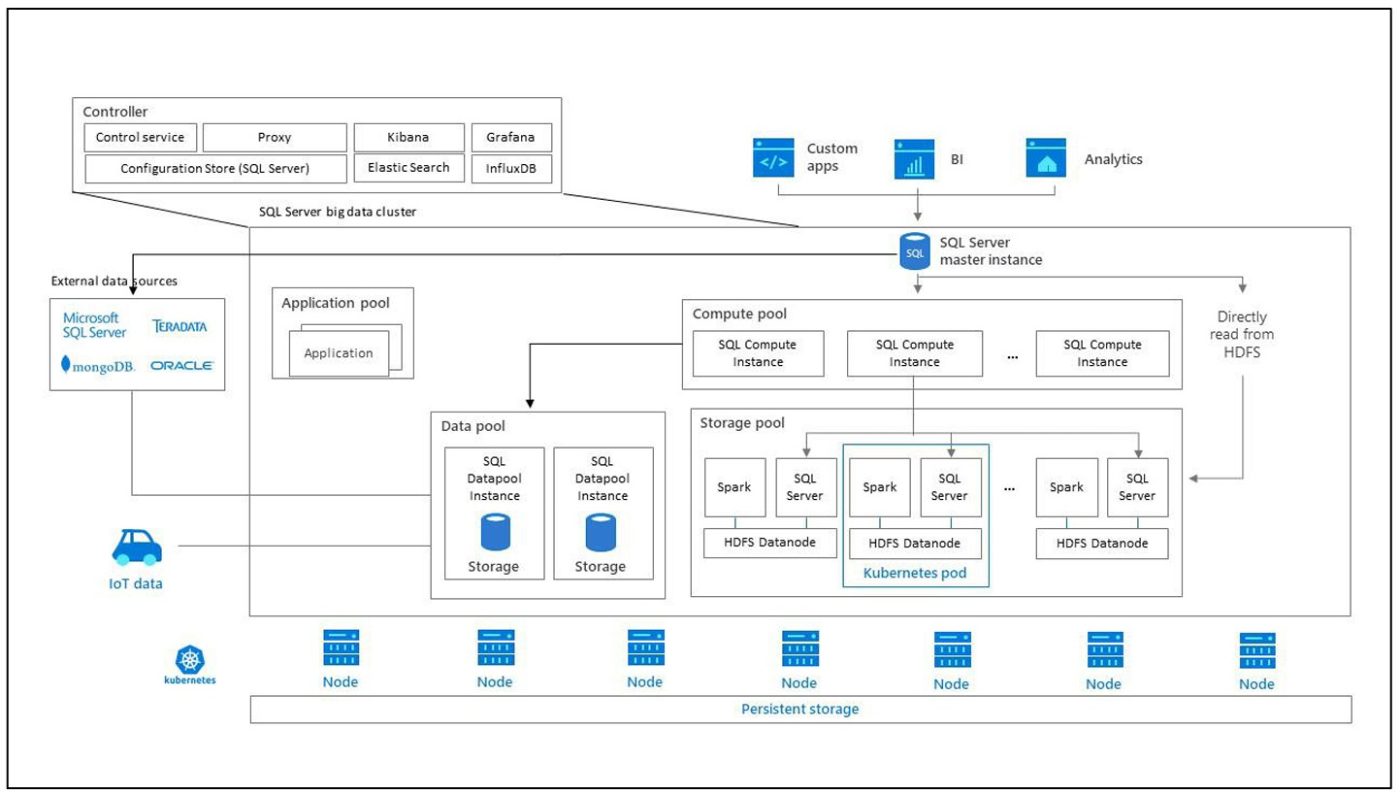
Contronller
コントローラは、クラスタの管理とセキュリティを提供します。これには、Kibana、Grafana、Elastic Searchなどの制御、構成、クラスターレイヤーサービスが含まれます。
計算プール
コンピューティングプールは、クラスターにコンピューティングリソースを提供します。これには、Linuxポッドで実行されているSQLServerノードが含まれます。計算されたプール内のポッドは、特定の処理操作のためにSQLComputeインスタンスに分割されます。
データプール
データプールは、データの永続性とキャッシュに使用されます。データプールには、Linux上でSQLServerを実行している1つ以上のポッドが含まれています。 SQLまたはSparkクエリからデータを取得するために使用されます。 SQL Serverビッグデータクラスターデータマートは、データプール内の永続性を維持します。
ストレージプール
ストレージプールには、Linux上のSQL Server、Spark、HDFSなどのストレージプールポッドが含まれます。 SQL Serverビッグデータクラスター内のすべてのストレージノードは、HDFSクラスターのメンバーです。
Bài viết liên quan:










Dịch vụ thiết kế Wesbite
