SQLServerSELECTステートメントとデータクエリ句
SQLの多くのバージョンはクエリでFROMを使用しますが、SQLServer2019を含むSQLServer2005以降のすべてのバージョンでは、FROM句を使用せずにSELECTステートメントを使用できます。
Mục lục
SELECTステートメント
SELECTステートメントを使用して、データを含むテーブルを表示できます。クエリのSELECTステートメントは、必要な情報をテーブルに表示します。 SELECTステートメントは、1つ以上のテーブルの行と列を取得します。 SELECTステートメントの出力は、結果セットと呼ばれる別のテーブルです。 SELECTステートメントは、2つのテーブルを結合するか、1つ以上のテーブルから列のサブセットを取得します。 SELECTステートメントは、クエリに使用される列を定義します。 SELECTステートメントの構文には、一連のコンマ区切り式を含めることができます。ステートメント内の各式は、結果セットの列です。列は、SELECtステートメントの式と同じ順序で表示されます。 SELECTステートメントはデータベースから行を取得し、1つ以上の行を選択できるようにします。
実行順序については、文頭に書かれていてもSELECT句は最後に実行されます。
構文:
SELECT <column_name1> [,column_name2] FROM <table_name>例えば:
SELECT [BusinessEntityID] ,[PersonType] ,[NameStyle] ,[Title] ,[FirstName] ,[MiddleName] ,[LastName] ,[Suffix] ,[EmailPromotion] ,[AdditionalContactInfo] ,[Demographics] ,[rowguid] ,[ModifiedDate] FROM [AdventureWorks2019].[Person].[Person]FROMなしで選択
SQLの多くのバージョンはクエリでFROMを使用しますが、SQLServer2019を含むSQLServer 2005以降のすべてのバージョンでは、FROM句を使用せずにSELECTステートメントを使用できます。
例えば:
SELECT LEFT ('Hello World',5) 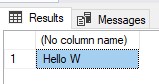
すべての列を表示
アスタリスク(*)キーワードは、表の列全体のデータを取得するためのSELECTステートメントに使用されます。これは、テーブル内のすべての列のリストを書き出す代わりに省略形として使用されます。
構文:
SELECT * FROM <table_name>例えば:
SELECT * FROM [AdventureWorks2019].[Person].[Person]*記号は、列が多すぎてすべての列名を思い出せない場合や、長すぎて書き留められない場合に非常に便利です。ただし、実際には、*記号を乱用しすぎないでください。乱用すると、データが冗長になるため、システムが非常にハードに実行されます。たとえば、ユーザー名を表示する関数を作成する場合、select usernameを書き込むだけで問題ありません。列を増やすとパフォーマンスが低下し、RAMの消費量が増えるため、必ずしもSELECT*である必要はありません。
SELECT以外の式
SELECTステートメントを使用すると、ユーザーはさまざまな式を指定して、結果セットを順序付けられた方法で表示できます。これらの式は、結果セットの列に異なる名前を割り当て、値を計算し、重複する値を削除します。
結果セットで定数を使用する
文字列定数は、文字列が連結されている場合に使用されます。それらは適切なフォーマットまたは読みやすさを助けます。これらの定数は、結果セットの個別の列として指定されていません。通常、サーバーを使用して定数値を組み合わせるよりも、アプリケーションが表示される結果に定数値を組み込む方が効率的です。たとえば、結果セットに「:」と「->」を含めて国名、国の市外局番、およびそれに対応するグループを表示するには、次の例にSELECTステートメントを示します。
USE AdventureWorks2019 SELECT Name+':'+CountryRegionCode+'->'+[Group] FROM Sales.SalesTerritory 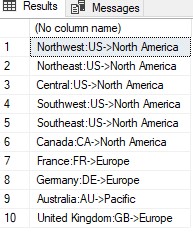
結果セットの列の名前を変更します
対応するタイトルを持つクエリの結果セットに表示される列は、AS句を使用して変更、名前変更、または新しい名前を割り当てることができます。ヘッダーをカスタマイズすることにより、ヘッダーはより理解しやすく、意味論的になります。
例えば:
USE AdventureWorks2019 SELECT Name+':'+CountryRegionCode+'->'+[Group] AS NameRegion FROM Sales.SalesTerritory 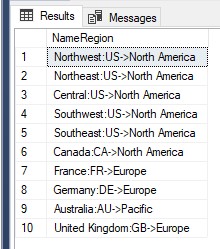
結果セットの値を計算します
SELECTステートメントには、1つ以上の列に演算子を適用することにより、数式を含めることができます。これにより、ベーステーブルには存在しないが、ベーステーブルに格納されている値から計算される値を含む結果セットが許可されます。
プロモーション表示に使用する結果セットの15%オフの例:
USE AdventureWorks2019 SELECT ProductID,StandardCost,StandardCost*0.16 AS Discount FROM Production.ProductCostHistory GO 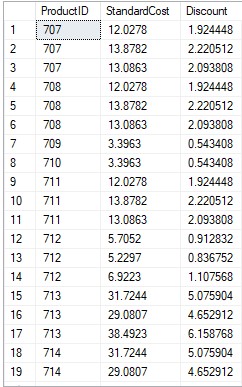
DISTINCTの使用
DISTINCTキーワードは、重複レコードの取得を防ぎます。 SELECTステートメントの結果セットから繰り返し行を削除します。たとえば、DISTINCTキーワードを使用せずにStandardCost列を選択すると、次のようにすべてのStandardCostレコードが1回だけ表示されます。
USE AdventureWorks2019 SELECT DISTINCT ProductID,StandardCost,StandardCost*0.16 AS Discount FROM Production.ProductCostHistory GOTOPとSELECTの使用
TOPキーワードは、結果セットの一部のみを表示します。レコードのセットは、数またはパーセンテージ(%)によって制限されます。TOP式は、INSERT、UPDATE、DELETEなどのステートメントでも使用できます。
構文:
SELECT [ALL|DISTINCT] [TOP expression [PERCENT] [NUMER]] FROM <table_name>例えば:
USE AdventureWorks2019 SELECT TOP 100 ProductID,StandardCost,StandardCost*0.16 AS Discount FROM Production.ProductCostHistory GOSELECTとINTOの組み合わせ
INTO句は、新しいテーブルを作成し、SELECTステートメントにリストされている行と列をそのテーブルに挿入します。
INTO句は、既存の行を新しいテーブルにも挿入します。 SELECTステートメントを使用してこの句を実行するには、ユーザーはターゲットデータベースでCREATETABLE権限を持っている必要があります。
構文:
SELECT <column_name1>,[, <column_name2> ...] INTO <new_table> FROM table_list例えば:
USE AdventureWorks2019 SELECT ProductModelID, Name INTO Production.ProductName FROM production.ProductModel GO 
SELECTとWHEREの組み合わせ
SELECTステートメントを含むWHERE句は、クエリによって取得されたレコードを条件付きで選択または制限(より理解されている場合はレコードのフィルター処理)するために使用されます。 WHERE句は、クエリによって返された行を調べるためのブール式を指定します。式がtrueの場合は行が返され、falseの場合は破棄されます。
構文:
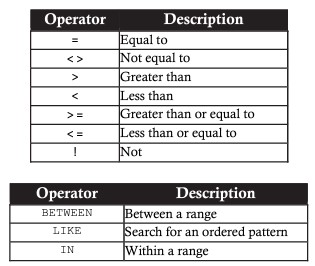
SELECT <column_name1> [, <column_name2> ...] FROM <table_name> WHERE <search_condition>SELECTの関係演算子:
WHERE句を使用してデータ値を表示する例指定された日付で終了
USE AdventureWorks2019 SELECT * FROM Production.ProductCostHistory WHERE EndDate ='2013-05-29' GO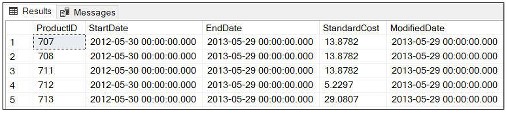
すべてのSQLクエリは、一重引用符を使用してテキスト値を囲みます。
例えば:
USE AdventureWorks2019 SELECT * FROM Person.Address WHERE City='Bothell' 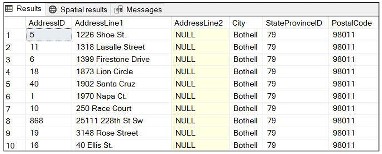
数値を囲むために一重引用符を使用する必要はありません
例えば:
USE AdventureWorks2019 SELECT * FROM HumanResources.Department WHERE DepartmentID < 10 GO 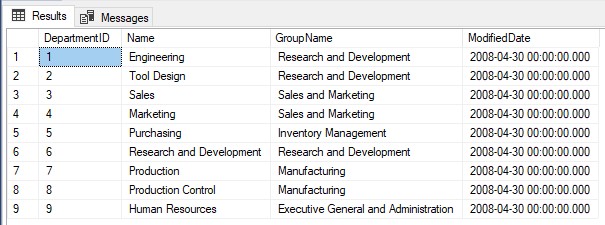
WHERE句は、ワイルドカード文字とともに使用できます。ワイルドカード文字は、正確で特定のクエリステートメントを作成するためにLIKEキーワードに使用される文字の概念です。
| ワイルドカード | 説明_ | 例えば |
| _ | 単一の文字を表す ドキュメント: https ://docs.microsoft.com/en-us/sql/t-sql/language-elements/wildcard-match-one-character-transact-sql?view = sql-server-2017 | 「Jr_」のようなサフィックスがあるPerson.Contactから*を選択します |
| % | 任意の長さの文字列表現 ドキュメント: https ://docs.microsoft.com/en-us/sql/t-sql/language-elements/percent-character-wildcard-character-s-to-match-transact-sql?view = sql-server- 2017 | LastNam like'B%'のPerson.Contactから*を選択します |
| [] | 角括弧で囲まれた領域内の単一の文字を表します ドキュメント: https ://docs.microsoft.com/en-us/sql/t-sql/language-elements/wildcard-character-s-to-match-transact-sql?view = sql-server-2017 | Select * from Sales.CurrencyRate where ToCurrencyCode like'C [AN] [DY]' |
| [^] | 角括弧内の文字を否定する単一の文字を表します。 ドキュメント: https ://docs.microsoft.com/en-us/sql/t-sql/language-elements/wildcard-character-s-not-to-match-transact-sql?view = sql-server-2017 | Select * from Sales.CurrencyRate where ToCurrencyCode like'A [^ R] [^ S]' |
WHERE句は、 AND、OR、NOTなどの論理演算子とともに使用することもできます。 WHERE。句の検索条件と組み合わせて使用される演算子
AND演算子は、2つ以上の条件を組み合わせ、両方の条件が満たされた場合にのみTRUEを返します。条件が満たされた場合、結果はすべてのレコードを返します。
例えば:
USE AdventureWorks2019 SELECT * FROM Person.Address WHERE AddressID > 900 AND City='Seattle' GOOR演算子はTRUEを返し、WHERE句の条件の1つを満たしている場合はレコードを表示します。
例えば:
USE AdventureWorks2019 SELECT * FROM Person.Address WHERE AddressID > 900 OR City='Seattle' GONOT演算子は、検索条件の否定です。
例えば:
USE AdventureWorks2019 SELECT * FROM Person.Address WHERE NOT AddressID = 5GROUPBY.句
GROUP BY句は、結果を1つ以上のサブセットに分割します。各サブセットには、共通の値と式があります。集計関数がGROUPBY句で使用されている場合、結果セットは集計ごとに単一の値を生成します
GROUP BYキーワードの後には、グループ化された列と呼ばれる列のリストが続きます。グループ化された各列は、結果セットの行数を制限します。グループ化された列ごとに、行は1つだけです。
GROUP BY句には、複数のグループ化された列を含めることができます。
SELECT <column_name1>, [, column_name2 , ...] FROM <table_name> GROUP BY <column_name>例えば:
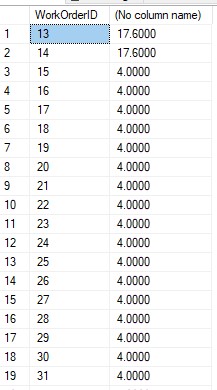
USE AdventureWorks2019 SELECT WorkOrderID,SUM(ActualResourceHrs) FROM Production.WorkOrderRouting GROUP BY WorkOrderID HAVING WorkOrderID < 50 GO結果はWorkOrderIDグループテーブルを返し、WorkOrderID<50のWorkOrderIDに基づいてActualResourceHrs列を合計します。
ORDERBY.句
結果セット内の列のソート順を指定します。クエリを1つ以上の列で並べ替えます。並べ替えは、昇順(ASC)または降順(DESC)のいずれかになります。デフォルトでは、レコードはASC順にソートされます。降順モードに切り替えるには、オプションのキーワードDESCを使用します。複数のフィールドを使用する場合、SQL Serverは左端のフィールドをプライマリの並べ替えレベルとして扱い、その他のフィールドを下位の並べ替えレベルとして扱います。
構文:
SELECT <column_name> FROM <table_name> ORDER BY <column_name> (ASC|DESC)例えば:
SELECT * FROM Sales.SalesTerritory ORDER BY SalesLastYear GO 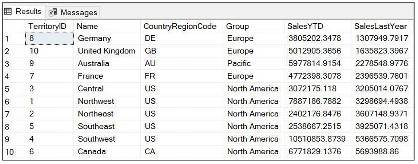
XMLの操作
Extensible Markup Language(XML)を使用すると、タグの開発者は独自の意味を持ち、他のプログラムはこれらのタグの意味を理解できます(HTMLタグに似ていますが、ブラウザーではなくデータストレージ用です)。 XMLは、開発者がWeb上でデータを保存、フォーマット、および管理するための推奨される媒体です。今日のアプリケーションには、ASP、.NETテクノロジ、XML、SQLサーバーなどのテクノロジが連携して機能しています。状況によっては、XMLデータをSQLServerに保存することが合理的な解決策です。
SQL ServerのネイティブXMLデータベースには、次のようないくつかの利点があります。
- パフォーマンスの向上:適切に実装されたXMLデータベースからのクエリは、ファイルシステムに保存されているドキュメントに対するクエリよりも高速です。さらに、データベースは通常、各ドキュメントを保存するときに解析します。
- 簡単なデータ処理:大きなドキュメントは簡単に処理できます(XMLが構造化されているため)
SQL Serverは、xmlデータ型を使用してXMLデータをネイティブに保存することをサポートしています。ネイティブXMLデータベースは、XMLドキュメントの論理モデル(そのドキュメント内のデータの説明として)を定義し、そのモデルに従ってドキュメントを格納および取得します。少なくとも、モデルには要素、属性、PCDATA、およびドキュメントの順序が含まれている必要があります。
XMLデータ型
一般的に使用されるデータ型に加えて、SQLServer2019はXMLデータ型をサポートしています。 XMLデータ型は、XMLドキュメントとセグメントをSQLServerデータベースに格納するために使用されます。 XMLセグメントは、構造から最上位要素が欠落しているXMLインスタンスです。
構文:
CREATE TABLE <table_name> ([column_list,] <column_name> xml [, column_list])例えば:
USE AdventureWorks2019 CREATE TABLE Person.PhoneBilling (Bill_ID int PRIMARY KEY, MobileNumber bigint UNIQUE, CallDetails xml) GOXMLスタイルの列は、作成時にテーブルからテーブルに追加することもできます。 XMLデータ型の列は、デフォルトの用語とNOTNULL制約をサポートします。
例えば:
AdventureWorks2019 INSERT INTO Person.PhoneBilling VALUES (100,98326505,'<Info><Call>Local</Call><Times>45 minuetes</Times><Charges>200</Charges></Info>') SELECT CallDetails FROM Person.PhoneBilling GO 
DECLAREステートメントは、XML型の変数を作成するために使用されます。 DECLAREステートメントの目的は、SQLServerで変数を宣言するために使用されます。
構文:
DECLARE @LOCAL_VẢIABLE datatype [= value]ローカル変数名は@記号で始まる必要があります。構文で指定されたvalueパラメーターは、宣言時に変数に初期値を割り当てるオプションのパラメーターです。変数に割り当てる初期値を指定しない場合、NULLとして初期化されます。
例えば:
DECLARE @xmlvar xml SELECT @xmlvar='<Employee name="Toan"/>'注: xmlデータ型は、主キー、外部キーとして使用したり、UNIQUE制約を使用したりすることはできません。
型付き(スタイル付き)XMLと型なし(スタイルなし)XMLという名前のxmlデータ型の列にXMLドキュメントを格納する方法は2つあります。スキーマが関連付けられているXMLインスタンスは、スタイル付きXMLインスタンスと呼ばれます。スキーマは、XMLドキュメントまたはバージョンのヘッダーです。データはtypecolumn.xmldataに格納されているときに検証できるため、XMLスキーマをバージョンまたは推奨されるXMLドキュメントに関連付けることにより、XMLドキュメントの構造とコンテンツの制限について説明します。
SQL Serverは、xml列に入力されたデータの検証を行いません。ただし、データが適切な標準で保存されることが保証されます。スタイルなしのXMLデータを作成し、データのニーズと範囲に応じてテーブルの列または変数に格納できます。
ドキュメント: https ://docs.microsoft.com/en-us/sql/relational-databases/xml/xml-schema-collections-sql-server?view = sql-server-ver16
型付きXMLを使用する場合の最初のステップは、スキーマを登録することです。構文:
CREATE XML SCHEMA COLLECTION <Schema_Collection_name> AS '[xmldefine]'例えば:
CREATE XML SCHEMA COLLECTION OrderSchemaCollection1 AS N'<?xml version="1.0"?> <xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:element name="Customer" /> </xsd:schema>' GO例として、データ型Orderのテーブルを作成します。
CREATE TABLE myOrder (orderID int identity not null, orderInfo xml (OrderSchemaCollection))新しく作成したXMLタイプを入力します。
insert into myOrder values ('<Customer></Customer>')さらに、SchemaColllactionを使用してXML変数を完全に作成できます。例えば:
use myDB DECLARE @order xml (OrderSchemaCollection1) SET @order = '<Customer></Customer>' select @order GO Bài viết liên quan:










Dịch vụ thiết kế Wesbite
