










Giới thiệu
hocvietcode.com là website chia sẻ và cập nhật tin tức công nghệ, chia sẻ kiến thức, kỹ năng. Chúng tôi rất cảm ơn và mong muốn nhận được nhiều phản hồi để có thể phục vụ quý bạn đọc tốt hơn !
Liên hệ quảng cáo: trienkhaiweb@gmail.com
最近、私はLSTMを使用して小さな小さなプロジェクトを行いましたが、ベトナム語の文書を読んで話すことについて深く理解することはあまり明確ではありません。この記事がありますhttps://dominhhai.github.io/vi/2017/10 / what-is-lstm /は外国のサイトから翻訳されたもので、かなり良いと思います。それから、私が行ったプロジェクトを通して、長い間使っていなかった将来、みんなと私自身のためにいくつかのことを共有し、それをもう一度読んで考えたいと思います。
Mục lục
LSTMについて説明する前に、以下に示すRNN(リカレントニューラルネットワーク)のルーツについて少し知っておく必要があると思います。
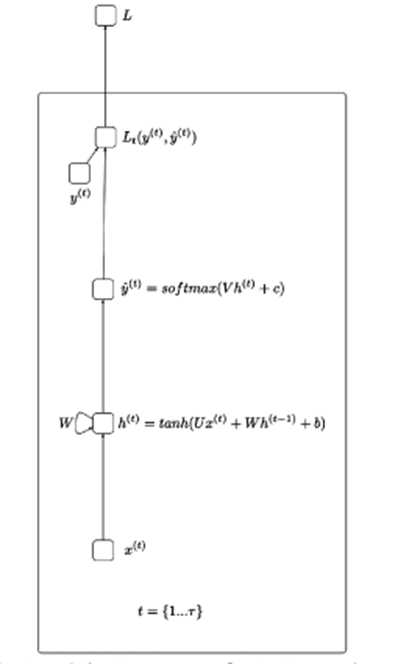
簡単に言えば、RNNは、音声、アクションなどの処理など、シーケンシャルシーケンスの形式でデータを処理するのに役立ちます…上の図のアイデアは、入力xが非表示のレイヤーを通過し、出力値を返すことです。(1つの配列にすることができます)損失関数を通過する出力からy_hatになります。
X(t):タイムステップtでの入力値
H(t):タイムステップtでの非表示状態
O(t):タイムステップtでの出力値
Y_hat:タイムステップtでのsoftmax関数による正規化された確率ベクトル
U、V、W:RNNの重み行列は、開始から非表示状態へ、非表示状態から出力へ、非表示状態から非表示状態への方向の接続に対応します。
B、c:偏差(バイアス)
LSTMは、RNNの勾配消失を克服するのに役立ちます。勾配を使用してニューロンをトレーニングし、入力データが長い場合、RNNは短期記憶の影響を受けるため、RNNは最初から送信された重要な情報を忘れる可能性があります。
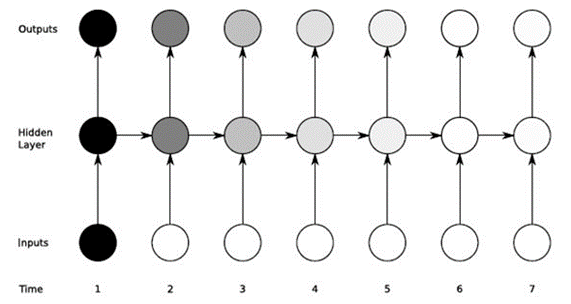
たとえば、映画シリーズを見るとき、私たちの脳は前の部分のコンテンツ情報を保存し、それを私たちが見ているエピソードと組み合わせてストーリーを作成します。
LSTMは、ゲートを内部にインストールし、セルの状態を全体で実行することにより、不要なデータポイントを削減するのに役立ちます。

各ゲートの動作とアクティブな機能を説明する記事や写真がたくさんあります。だからここで私はこの男を説明するために数学を使用しようとします。簡単にまとめると、LSTMは1つのセル状態と3つのゲートを使用して入力データを処理します。下の写真に載せたレシピ:


これは、タイムステップでのLSTMの操作です。つまり、これらの式は、別のタイムステップで再計算されます。また、重み(Wf、Wi、Wo、Wc、Uf、Ui、Uo、Uc)とバイアス(bf、bi、bo、bc)は変化しません。
たとえば、LSTMを10のタイムステップで展開するには、次のようにします。
sequence_len = 10
範囲(0、sequence_len)のiの場合:
#最初のステップにいる場合
#h(t-1)とc(t-1)を初期化します
# 無作為に
i == 0の場合:
ht_1 = random()
ct_1 = random()
そうしないと:
ht_1 = h_t
ct_1 = c_t
f_t =シグモイド(
matrix_mul(Wf、xt)+
matrix_mul(Uf、ht_1)+
bf
)。
i_t =シグモイド(
matrix_mul(Wi、xt)+
matrix_mul(Ui、ht_1)+
bi
)。
o_t =シグモイド(
matrix_mul(Wo、xt)+
matrix_mul(Uo、ht_1)+
bo
)。
cp_t = tanh(
matrix_mul(Wc、xt)+
matrix_mul(Uc、ht_1)+
紀元前
)。
c_t = element_wise_mul(f_t、ct_1)+
element_wise_mul(i_t、cp_t)
h_t = element_wise_mul(o_t、tanh(c_t))
一次数学で不可欠な問題は、データの次元です(これは、面接の質問のリストに含まれていることが多いため、将来再読する必要がある部分かもしれません)。
次のようなタイムステップでのLSTMの公式を使用します。
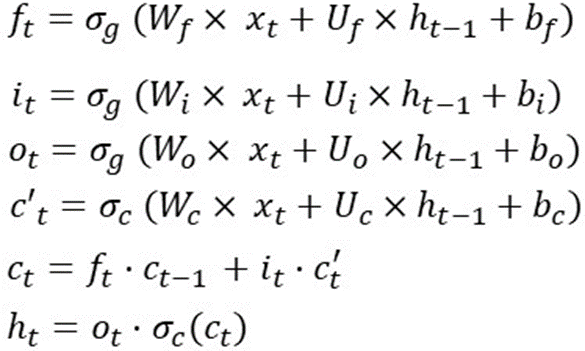
dim(o(t))が[12×1] => dim(h(t))であり、dim(c(t))が[12×1]であるとしましょう。これは、h(t)がo( t)およびtanh(c(t))。
また、x(t)の次元は[80×1] => W(f)は[12×80]です。これは、f(t)= [12×1]およびx(t)=[80×1]であるためです。
Bf、bi、bc、boのサイズは[12×1]です。
また、Uf、Ui、Uc、Uoのサイズは[12×12]です。
したがって、LSTMの総重量は4 * [12×80] + 4 * [12×12] + 4 * [12×1]=4464です。
上記の計算を見ると、LSTMは入力次元と出力次元の2つに関心があることがわかります(ブログによっては、LSTMユニットの数または隠れた次元と呼ばれる場合があります…)。
LSTMの重み行列サイズの要約は4*Output_Dim *(Output_Dim + Input_Dim + 1)です。
多くの人が混乱させるパラメータについてのメモがあります:

Kerasには、return_squence = False(デフォルト)の場合はreturn_sequence(true、falseを返す)のパラメーターがあります。それ以外の場合、Trueは多対多になります。
サイズ[5×126]の入力データXの例
モデルは次のとおりです。
モデル=Sequential()
model.add(LSTM(64、return_sequences = True、activation ='relu'、input_shape =(5,126)))
model.add(LSTM(128、return_sequences = True、activation ='relu'))
model.add(LSTM(64、return_sequences = False、activation ='relu'))
model.add(Dense(64、activation ='relu'))
model.add(Dense(32、activation ='relu'))
model.add(Dense(actions.shape [0]、activation ='softmax'))
隠し数が64の最初のLSTMレイヤーを通して見ることができます=>このレイヤーを通過した後のパラメーターの数は次のとおりです。
4 *((126 + 64)* 64 + 64)= 48896(次の2つのLSTMレイヤーについても同じであり、その出力は次のレイヤーの入力になります)。
密なレイヤー(output_dimがそのレイヤーの出力次元であるkerasのレイヤー)の場合、新しいパラメーターの数はoutput_dim * output_dim(前のレイヤーの)+1に等しくなります。
最初の密な層の例:パラメーターの数は次のとおりです:64 *(64 + 1)= 4160

この記事で要約すると、パラメーターの計算の観点からLSTMの動作を説明しようとしました。これは、機械学習モデルの設計と高速化に役立つ非常に重要なステップです。

hocvietcode.com là website chia sẻ và cập nhật tin tức công nghệ, chia sẻ kiến thức, kỹ năng. Chúng tôi rất cảm ơn và mong muốn nhận được nhiều phản hồi để có thể phục vụ quý bạn đọc tốt hơn !
Liên hệ quảng cáo: trienkhaiweb@gmail.com