Instrução SELECT do SQL Server e cláusulas de consulta de dados
Muitas versões do sql usam FROM em suas consultas, mas em todas as versões desde o SQL Server 2005, incluindo o SQL Server 2019, é possível usar instruções SELECT sem usar a cláusula FROM.
Mục lục
instrução SELECT
Uma tabela com seus dados pode ser visualizada usando a instrução SELECT. A instrução SELECT em uma consulta exibe as informações necessárias em uma tabela. A instrução SELECT recupera as linhas e colunas de uma ou mais tabelas. A saída da instrução SELECT é outra tabela chamada de conjunto de resultados. A instrução SELECT também une duas tabelas ou recupera um subconjunto de colunas de uma ou mais tabelas. A instrução SELECT define as colunas usadas para uma consulta. A sintaxe da instrução SELECT pode incluir uma série de expressões separadas por vírgula. Cada expressão na instrução é uma coluna no conjunto de resultados. As colunas aparecem na mesma ordem que a expressão na instrução SELECt. A instrução SELECT recupera linhas do banco de dados e permite selecionar uma ou mais linhas.
Em relação à sequência de execução, a cláusula SELECT será executada por último, mesmo que esteja escrita no início da frase
Sintaxe:
SELECT <column_name1> [,column_name2] FROM <table_name>Por exemplo:
SELECT [BusinessEntityID] ,[PersonType] ,[NameStyle] ,[Title] ,[FirstName] ,[MiddleName] ,[LastName] ,[Suffix] ,[EmailPromotion] ,[AdditionalContactInfo] ,[Demographics] ,[rowguid] ,[ModifiedDate] FROM [AdventureWorks2019].[Person].[Person]Selecionar sem DE
Muitas versões do SQL usam FROM em suas consultas, mas em todas as versões desde o SQL Server 2005, incluindo SQL Server2019, a instrução SELECT pode ser usada sem usar a cláusula FROM.
Por exemplo:
SELECT LEFT ('Hello World',5) 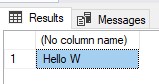
Mostrar todas as colunas
A palavra-chave asterisco (*) é usada para a instrução SELECT para recuperar os dados da coluna inteira na tabela. Ele é usado como um atalho em vez de escrever uma lista de todas as colunas na tabela.
Sintaxe:
SELECT * FROM <table_name>Por exemplo:
SELECT * FROM [AdventureWorks2019].[Person].[Person]O sinal * é muito conveniente no caso de haver muitas colunas e você não conseguir se lembrar de todos os nomes das colunas, ou se for muito longo para escrever. Porém, na prática, você não deve abusar muito do sinal * porque assim o sistema vai rodar muito porque os dados serão redundantes. Por exemplo, se você construir uma função que exibe nomes de usuário, basta escrever select username is ok, não necessariamente SELECT * porque remover mais colunas reduzirá o desempenho e consumirá mais memória RAM.
Expressões diferentes de SELECT
A instrução SELECT permite que o usuário especifique diferentes expressões para visualizar o conjunto de resultados de maneira ordenada. Essas expressões atribuem nomes diferentes a colunas no conjunto de resultados, calculam valores e removem valores duplicados.
Usando constantes em conjuntos de resultados
As constantes de string são usadas quando as colunas de caracteres são concatenadas juntas. Eles ajudam na formatação ou legibilidade adequada. Essas constantes não são especificadas como uma coluna separada no conjunto de resultados. Geralmente é mais eficiente para o aplicativo construir valores constantes nos resultados conforme eles são exibidos em vez de usar o servidor para combinar os valores constantes. Por exemplo, para incluir ':' e '->' no conjunto de resultados para exibir o nome do país, o código de área do país e seu grupo correspondente, a instrução SELECT é mostrada no exemplo a seguir:
USE AdventureWorks2019 SELECT Name+':'+CountryRegionCode+'->'+[Group] FROM Sales.SalesTerritory 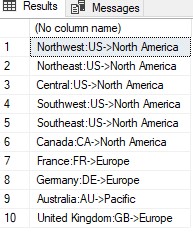
Renomear coluna no conjunto de resultados
As colunas exibidas no conjunto de resultados de consultas com o título correspondente podem ser alteradas, renomeadas ou podem receber um novo nome usando a cláusula AS. Ao personalizar os cabeçalhos, eles se tornam mais compreensíveis e semânticos.
Por exemplo:
USE AdventureWorks2019 SELECT Name+':'+CountryRegionCode+'->'+[Group] AS NameRegion FROM Sales.SalesTerritory 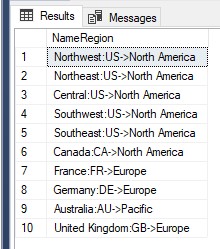
Calcular o valor no conjunto de resultados
A instrução SELECT pode conter expressões matemáticas aplicando operadores a uma ou mais colunas. Ele permite um conjunto de resultados contendo valores que não existem na tabela base, mas são calculados a partir dos valores armazenados na tabela base.
Exemplo de conjunto de resultados de 15% de desconto a ser usado para exibição promocional:
USE AdventureWorks2019 SELECT ProductID,StandardCost,StandardCost*0.16 AS Discount FROM Production.ProductCostHistory GO 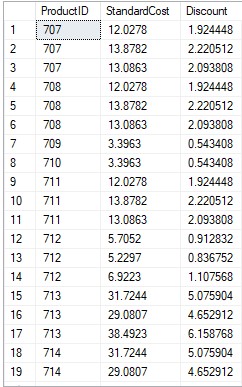
Usando DISTINCT
A palavra-chave DISTINCT impede a recuperação de registros duplicados. Ele remove as linhas repetidas do conjunto de resultados de uma instrução SELECT. Por exemplo, se a coluna StandardCost for selecionada sem usar a palavra-chave DISTINCT, ela exibirá cada registro StandardCost apenas uma vez, como por exemplo:
USE AdventureWorks2019 SELECT DISTINCT ProductID,StandardCost,StandardCost*0.16 AS Discount FROM Production.ProductCostHistory GOUsando TOP e em SELECT
A palavra-chave TOP mostrará apenas parte do conjunto de resultados. O conjunto de registros será limitado por número ou porcentagem (%), a expressão TOP também pode ser usada com instruções como INSERT, UPDATE, DELETE.
Sintaxe:
SELECT [ALL|DISTINCT] [TOP expression [PERCENT] [NUMER]] FROM <table_name>Por exemplo:
USE AdventureWorks2019 SELECT TOP 100 ProductID,StandardCost,StandardCost*0.16 AS Discount FROM Production.ProductCostHistory GOSELECT combinado com INTO
A cláusula INTO cria uma nova tabela e insere nela as linhas e colunas listadas na instrução SELECT.
A cláusula INTO também insere linhas existentes na nova tabela. Para executar esta cláusula com uma instrução SELECT, o usuário deve ter a permissão CREATE TABLE no banco de dados de destino.
Sintaxe:
SELECT <column_name1>,[, <column_name2> ...] INTO <new_table> FROM table_listPor exemplo:
USE AdventureWorks2019 SELECT ProductModelID, Name INTO Production.ProductName FROM production.ProductModel GO 
SELECT combinado com WHERE
A cláusula WHERE com uma instrução SELECT é usada para selecionar ou limitar condicionalmente (mais entendido, filtrar registros) os registros recuperados pela consulta. A cláusula WHERE especifica uma expressão booleana para examinar as linhas retornadas pela consulta. As linhas são retornadas se a expressão for verdadeira e descartadas se for falsa.
Sintaxe:
SELECT <column_name1> [, <column_name2> ...] FROM <table_name> WHERE <search_condition>Operadores relacionais em SELECT:
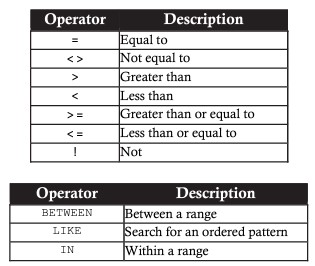
Exemplo usando a cláusula WHERE para exibir dados voiws Endate como data especificada
USE AdventureWorks2019 SELECT * FROM Production.ProductCostHistory WHERE EndDate ='2013-05-29' GO 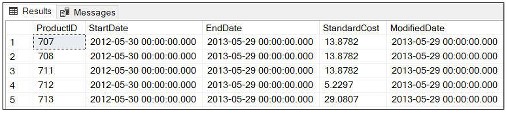
Todas as consultas SQL usam aspas simples para incluir valores de texto .
Por exemplo:
USE AdventureWorks2019 SELECT * FROM Person.Address WHERE City='Bothell' 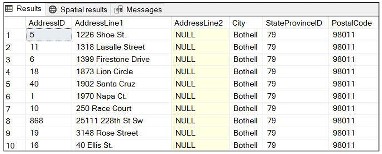
Valores numéricos não precisam usar aspas simples para incluir
Por exemplo:
USE AdventureWorks2019 SELECT * FROM HumanResources.Department WHERE DepartmentID < 10 GO 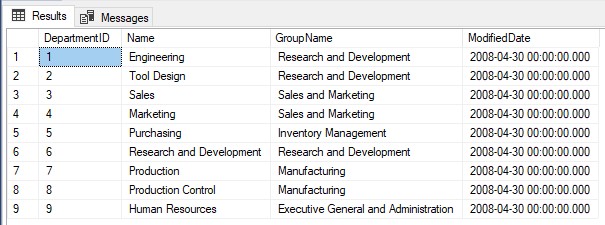
A cláusula WHERE pode ser usada com caracteres curinga , que é o conceito de caractere usado para a palavra-chave LIKE para criar uma instrução de consulta exata e específica.
| Curinga | Descrição _ | Por exemplo |
| _ | Representando um único caractere Documentos: https://docs.microsoft.com/en-us/sql/t-sql/language-elements/wildcard-match-one-character-transact-sql?view=sql-server-2017 | selecione * de Person.Contact onde Sufixo como 'Jr_' |
| % | Representação de string de qualquer comprimento Documentos: https://docs.microsoft.com/en-us/sql/t-sql/language-elements/percent-character-wildcard-character-s-to-match-transact-sql?view=sql-server- 2017 | selecione * de Person.Contact onde LastNam como 'B%' |
| [ ] | Representa um único caractere dentro da área delimitada por colchetes Documentos: https://docs.microsoft.com/en-us/sql/t-sql/language-elements/wildcard-character-s-to-match-transact-sql?view=sql-server-2017 | selecione * de Sales.CurrencyRate onde ToCurrencyCode como 'C[AN][DY]' |
| [^] | Representa um único caractere que nega os caracteres entre colchetes. Documentos: https://docs.microsoft.com/en-us/sql/t-sql/language-elements/wildcard-character-s-not-to-match-transact-sql?view=sql-server-2017 | selecione * de Sales.CurrencyRate onde ToCurrencyCode como 'A[^R][^S]' |
A cláusula WHERE também pode ser usada com operadores lógicos como AND, OR, NOT . Operadores usados em conjunto com condições de pesquisa na cláusula WHERE .
O operador AND combina 2 ou mais condições e retorna TRUE somente se ambas as condições forem atendidas, o resultado retornará todos os registros se a condição for satisfeita.
Por exemplo:
USE AdventureWorks2019 SELECT * FROM Person.Address WHERE AddressID > 900 AND City='Seattle' GOO operador OR retorna TRUE e exibe os registros se satisfizer uma das condições da cláusula WHERE.
Por exemplo:
USE AdventureWorks2019 SELECT * FROM Person.Address WHERE AddressID > 900 OR City='Seattle' GOO operador NOT é a negação da condição de pesquisa
Por exemplo:
USE AdventureWorks2019 SELECT * FROM Person.Address WHERE NOT AddressID = 5cláusula GROUP BY .
A cláusula GROUP BY particiona os resultados em um ou mais subconjuntos. Cada subconjunto possui valores e expressões comuns. Se uma função agregada for usada na cláusula GROUP BY, o conjunto de resultados produzirá valores únicos para cada agregado
A palavra-chave GROUP BY é seguida por uma lista de colunas, chamada de coluna agrupada. Cada coluna agrupada restringe o número de linhas do conjunto de resultados. Para cada coluna agrupada, há apenas uma linha.
A cláusula GROUP BY pode ter mais de uma coluna agrupada.
SELECT <column_name1>, [, column_name2 , ...] FROM <table_name> GROUP BY <column_name>Por exemplo:
USE AdventureWorks2019 SELECT WorkOrderID,SUM(ActualResourceHrs) FROM Production.WorkOrderRouting GROUP BY WorkOrderID HAVING WorkOrderID < 50 GOO resultado retornará uma tabela de grupo WorkOrderID e somará a coluna ActualResourceHrs com base em WorkOrderID com WorkOrderID < 50
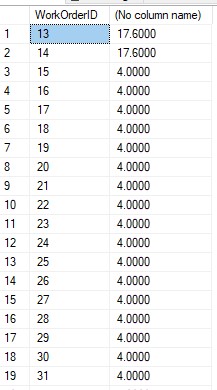
Cláusula ORDER BY .
Ele especifica a ordem de classificação das colunas em um conjunto de resultados. Ele classifica a consulta por uma ou mais colunas. A classificação pode ser em ordem crescente (ASC) ou decrescente (DESC). Por padrão, os registros são classificados na ordem ASC. Para alternar para o modo decrescente, use a palavra-chave opcional DESC. Ao usar vários campos, o SQL Server trata o campo mais à esquerda como o nível de classificação principal e os outros como o nível de classificação inferior.
Sintaxe:
SELECT <column_name> FROM <table_name> ORDER BY <column_name> (ASC|DESC)Por exemplo:
SELECT * FROM Sales.SalesTerritory ORDER BY SalesLastYear GO 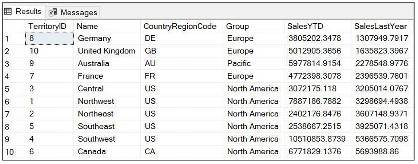
Trabalhando com XML
Extensible Markup Language (XML) permite que desenvolvedores de tags tenham seus próprios significados e que outros programas possam entender os significados dessas tags (semelhantes às tags HTML, mas para armazenamento de dados, não para navegadores). XML é o meio preferido para os desenvolvedores armazenarem, formatarem e gerenciarem dados na web. Os aplicativos hoje têm uma combinação de tecnologias como ASP, tecnologia .NET, XML, servidor SQL trabalhando em conjunto. Em algumas situações, armazenar dados XML no SQL Server é uma solução razoável.
O banco de dados XML nativo no SQL Server tem várias vantagens, como segue:
- Melhor desempenho: consultas de bancos de dados XML bem implementados são mais rápidas do que consultas em documentos armazenados no sistema de arquivos. Além disso, o banco de dados normalmente analisa cada documento ao armazená-lo.
- Fácil manuseio de dados: Documentos grandes podem ser manuseados facilmente (porque o XML é estruturado)
O SQL Server oferece suporte ao armazenamento de dados XML nativamente usando o tipo de dados xml. O banco de dados XML nativo define um modelo lógico para um documento XML – como uma descrição dos dados desse documento – e armazena e recupera o documento de acordo com esse modelo. No mínimo, o modelo deve incluir elementos, atributos, PCDATA e ordenação de documentos.
Tipo de dados XML
Além dos tipos de dados comumente usados, o SQL Server 2019 oferece suporte a tipos de dados XML. O tipo de dados XML é usado para armazenar documentos e segmentos XML em bancos de dados SQL Server. Um segmento XML é uma instância XML com um elemento de nível superior ausente em sua estrutura.
Sintaxe:
CREATE TABLE <table_name> ([column_list,] <column_name> xml [, column_list])Por exemplo:
USE AdventureWorks2019 CREATE TABLE Person.PhoneBilling (Bill_ID int PRIMARY KEY, MobileNumber bigint UNIQUE, CallDetails xml) GOAs colunas de estilo XML também podem ser adicionadas de uma tabela a uma tabela no momento da criação. As colunas de tipo de dados XML suportam termos DEFAULT, bem como restrições NOT NULL.
Por exemplo:
AdventureWorks2019 INSERT INTO Person.PhoneBilling VALUES (100,98326505,'<Info><Call>Local</Call><Times>45 minuetes</Times><Charges>200</Charges></Info>') SELECT CallDetails FROM Person.PhoneBilling GO 
A instrução DECLARE é usada para criar variáveis do tipo XML. A finalidade da instrução DECLARE é usada para declarar uma variável no SQL Server.
Sintaxe:
DECLARE @LOCAL_VẢIABLE datatype [= value]Os nomes de variáveis locais devem começar com um sinal @. O parâmetro value especificado na sintaxe é um parâmetro opcional que ajuda a atribuir um valor inicial à variável durante a declaração. Se você não especificar nenhum valor inicial a ser atribuído a uma variável, ela será inicializada como NULL
Por exemplo:
DECLARE @xmlvar xml SELECT @xmlvar='<Employee name="Toan"/>'Nota: O tipo de dados xml não pode ser usado como chave primária, chave estrangeira ou usar restrição UNIQUE.
Há duas maneiras de armazenar documentos XML em colunas com tipo de dados xml denominado XML tipado e não tipado. Uma instância XML que tem um esquema associado a ela é chamada de instância XML com estilo. Um esquema é um cabeçalho para um documento ou versão XML. Ele descreve as limitações de estrutura e conteúdo de documentos XML associando esquemas XML a versões ou documentos XML recomendados, pois os dados podem ser validados à medida que estão sendo armazenados na coluna type.xml data.
O SQL Server não faz nenhuma validação para os dados inseridos na coluna xml. No entanto, garante que os dados sejam armazenados com um bom padrão. Dados XML sem estilo podem ser criados e armazenados em colunas ou variáveis de tabela, dependendo das necessidades e do escopo dos dados.
A primeira etapa ao usar XML tipado é registrar o esquema. Sintaxe:
CREATE XML SCHEMA COLLECTION <Schema_Collection_name> AS '[xmldefine]'Por exemplo:
CREATE XML SCHEMA COLLECTION OrderSchemaCollection1 AS N'<?xml version="1.0"?> <xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:element name="Customer" /> </xsd:schema>' GOCrie uma tabela do tipo de dados Ordem conforme o exemplo:
CREATE TABLE myOrder (orderID int identity not null, orderInfo xml (OrderSchemaCollection))Insira o tipo XML recém-criado:
insert into myOrder values ('<Customer></Customer>')Além disso, podemos criar completamente uma variável XML usando o Schema Collaction. Por exemplo:
use myDB DECLARE @order xml (OrderSchemaCollection1) SET @order = '<Customer></Customer>' select @order GO Bài viết liên quan:











Dịch vụ thiết kế Wesbite
