Índice no SQL Server
Mục lục
Introdução ao índice
Um índice é uma estrutura de dados especial associada a uma tabela ou visualização para acelerar as consultas. Em poucas palavras, ao indexar um campo em uma tabela, os valores desse campo serão organizados e armazenados de forma estruturada, o que ajudará a consultar os dados de forma mais eficiente em termos de desempenho e velocidade. A lista de índices comuns no SQL Server é a seguinte:
| Tipo de índice | Descrever |
| Agrupado | Ele classifica e armazena as linhas de dados de uma tabela ou exibição em ordem com base nas chaves. O índice clusterizado implementado na estrutura B-Tree suporta a obtenção de dados de linha, com base em índices de valores-chave |
| Não agrupado | Índices não clusterizados são excluídos em uma tabela ou exibição que possui dados em uma estrutura clusterizada ou em um heap. Cada linha de índice no índice não clusterizado contém o valor da chave e um localizador de linha. O localizador aponta para a linha de dados no índice clusterizado ou o heap com o valor de chave. As linhas no índice são armazenadas na ordem dos valores de chave de índice, mas não há garantia de que as linhas de dados estejam em nenhuma ordem específica, a menos que um índice clusterizado seja criado na tabela. |
| Único | Um índice exclusivo garante que a chave de índice não contenha valores duplicados e, portanto, cada linha na tabela ou visualização seja de alguma forma única. A exclusividade pode ser uma propriedade de índices clusterizados e não clusterizados. |
| Armazenamento de colunas | Index Columnstore armazena e gerencia dados usando armazenamento de dados baseado em coluna na memória e processamento de consulta baseado em coluna O Index Columnstore funciona quando as cargas de trabalho de armazenamento de dados executam principalmente carregamento interno e filas somente leitura. Use o columnstore de índice para obter desempenho de consulta de até 10 vezes em relação ao armazenamento tradicional orientado a linhas e compactação de dados de até 8 vezes para tamanhos de dados não compactados |
| filtrado | Os índices clusterizados são otimizados para incluir consultas que selecionam a partir de um subconjunto de dados bem definido. Ele usa um predicado de filtro para indexar parte das linhas da tabela. Um índice filtrado bem projetado pode melhorar o desempenho da consulta, reduzir os custos de manutenção do índice e reduzir os custos de armazenamento do índice em comparação com os índices de tabela completa. |
| Espacial | Ele fornece a capacidade de realizar algumas operações mais eficientes em objetos espaciais dentro de uma coluna de tipo de dados de geometria. |
| XML | Devido aos grandes tamanhos de coluna XML, as consultas de pesquisa nessas colunas podem ser lentas. Você pode acelerar essas consultas criando um índice XML por coluna. O índice XML pode ser um índice clusterizado ou um índice não clusterizado. |
Existem também outros tipos de índices como Hash, otimização de memória não clusterizada, índice com coluna incluída, índice em coluna computada, texto completo.
O SQL Server usa índices semelhantes a como um livro é indexado. Por exemplo, considerando uma situação em que queremos encontrar todas as chaves “INSERT” em um livro de aprendizado de SQL, a abordagem imediata seria escanear cada página do livro começando na página inicial e, em seguida, marcar cada vez que a palavra “INSERT ” é encontrado, até o final do livro. Essa abordagem leva tempo e esforço. A segunda forma utilizada é usar o índice do livro e ir até a página onde os resultados falam sobre INSERT e encontrar aquela página, usá-la. O método 2 resulta semelhante ao método um, mas economiza mais tempo e esforço.
Quando o SQL Server não define um índice, ele se comportará como a primeira forma no exemplo, o SQL engine terá que acessar cada registro no banco de dados, em termos de banco de dados, esse comportamento é chamado de table scan ou apenas scan.
A varredura de tabela não é ineficiente, mas em algumas situações específicas precisaremos usar outra solução que é usar índices para aumentar o desempenho, pois conforme a tabela de dados cresce com o número de registros aumentando. -intensivo, nesta situação, os índices são sempre recomendados.
Visão geral do armazenamento de dados
Um livro contém páginas, dentro de parágrafos e frases, semelhante ao SQL Server armazenando dados em unidades chamadas páginas de dados. Essas páginas contêm dados em linhas.
Cada página do livro tem dimensões físicas. Da mesma forma, no SQL Server todas as páginas de dados têm o mesmo tamanho de 8 KB. Ou seja, um banco de dados contém 128 páginas de dados por megabyte (MB) de espaço de armazenamento.
Uma página começa com um cabeçalho de 96 bytes, que armazena informações do sistema sobre a página, incluindo:
- Número de páginas
- Estilo da página
- Quantidade de espaço livre na página
- O ID de atribuição do objeto para a página atribuída
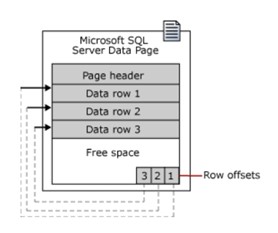
Nota: a página de dados é a menor unidade de armazenamento de dados. Uma unidade de alocação é uma coleção de páginas de dados agrupadas com base no tipo de página. O agrupamento tornará a governança de dados mais eficiente.
Arquivos de dados
Todas as tarefas de entrada e saída no banco de dados são tratadas na camada de página. Isso significa que o mecanismo de banco de dados lê ou grava páginas de dados. Um conjunto de oito páginas consecutivas é chamado de extensão .
O SQL Server armazena páginas de dados em arquivos chamados de arquivos de dados. O espaço alocado para o arquivo de dados é dividido pelo número de páginas de dados organizadas sequencialmente, as páginas iniciam em 0 , representação geométrica conforme mostrado abaixo.
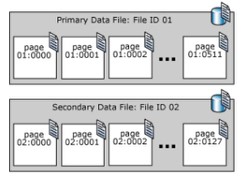
Existem 3 tipos de 3 arquivos de dados explicados da seguinte forma:
- Primário: O arquivo principal é criado automaticamente no momento da criação do banco de dados, este arquivo possui referências a todos os demais arquivos do banco de dados. A extensão recomendada e padrão para arquivos de dados primários é .mdf
- Secundário: são arquivos de dados opcionais definidos pelo usuário. Os dados podem ser distribuídos em várias unidades colocando cada arquivo em uma unidade diferente. A extensão recomendada para arquivos de dados secundários é .ndf
- Log de transações: os arquivos de log armazenam informações sobre o histórico de modificações no banco de dados. Essas informações são úteis para a recuperação de dados de backup, como uma falha repentina de energia ou a necessidade de mover o banco de dados para outro servidor. Há pelo menos um arquivo de log em cada banco de dados. A extensão recomendada para arquivos de log é .ldf
Requisito para índices
Para facilitar a recuperação rápida de dados de um banco de dados, o SQL Server fornece um recurso de indexação. Semelhante ao índice de um livro, um índice em um banco de dados SQL Server contém informações que permitem pesquisar dados um de cada vez. tabela.

Índice
Em uma tabela, os registros são armazenados na ordem em que foram inseridos, são armazenados no banco de dados sem serem ordenados, ou seja, são ordenados pelo histórico de entrada. Quando os dados são recuperados da tabela, toda a tabela precisará ser verificada, o que retarda o processo. Para acelerar o processo, fazemos algo chamado indexação.
Quando um índice é criado na tabela, ele cria uma versão classificada do registro, o que acelera a localização e a recuperação de dados durante uma pesquisa.
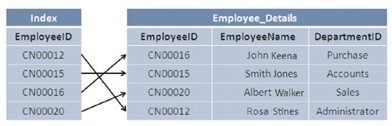
O índice é criado automaticamente quando as restrições PRIMARY KEY e UNIQUE são definidas na tabela, a indexação reduz as tarefas de leitura e gravação do disco e consome menos recursos do sistema.
Sintaxe:
CREATE INDEX <index_name> ON <table_name> (<column_name>)O índice aponta para a posição do registro na página de dados em vez de pesquisar na tabela. Algumas características do índice:
- Os índices aceleram uma consulta que une uma tabela ou trata de tarefas de classificação.
- Index implementa a exclusividade de linhas se definido quando você cria o índice.
- Os índices são criados e mantidos em classificação direta e reversa.
O roteiro
Por exemplo, em uma lista telefônica, haverá uma grande quantidade de dados classificados e acessados com frequência, os dados serão armazenados em ordem alfabética. Se os dados não forem classificados, é quase impossível encontrar um número de telefone específico rapidamente.
Da mesma forma, em uma tabela de banco de dados que possui um grande número de registros e precisa ser consultada com frequência, os dados serão classificados para consultas mais rápidas. Quando um índice é criado para uma tabela, o índice classifica os registros física ou logicamente. Portanto, localizar o registro especificado torna-se mais rápido e reduz a carga de recursos do sistema.
dados de acesso de grupo
Os índices são úteis quando os dados são acessados em grupos. Por exemplo, você deseja criar uma modificação que alterne os departamentos do grupo de RH com base nos departamentos em que o pessoal está trabalhando no banco de dados. Nesta situação é possível criar um índice para a coluna DepartmentName antes de acessar os registros.
Esse índice criará fragmentos de dados lógicos e agrupará registros em departamentos, o que limitará a quantidade de dados realmente verificados durante a recuperação de dados.
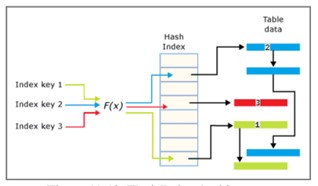
Arquitetura de índice
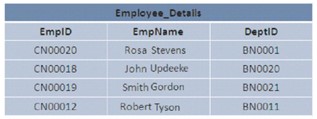
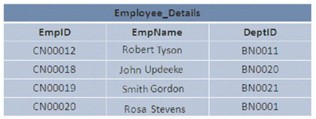
No SQL Server, os dados no banco de dados podem ser armazenados em um determinado arranjo ou aleatório. Se os dados são armazenados de forma ordenada, diz-se que os dados são representados em uma estrutura agrupada. Se os dados são armazenados aleatoriamente, é chamado de estrutura de heap.
A imagem ilustra 2 estruturas Heap e Clustered:
B-Árvore
No SQL Server, os índices são organizados em uma estrutura B-Tree, cada página em um índice B-tree é chamada de nó de índice. O nó mais alto é chamado de nó raiz. A nota inferior no índice é chamada de nós folha. Qualquer camada entre o nó raiz e o nó folha é chamada de nó intermediário.
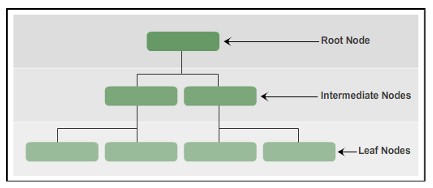
O índice B-Tree vai da parte superior do nó até a parte inferior por ponteiro.
Estrutura do índice B-Tree
Na estrutura B-Tree de um índice, o nó raiz inclui uma página de índice. A página de índice contém um ponteiro e aponta para a página de índice que representa a primeira camada intermediária. Essas páginas de índice, por sua vez, apontam para as páginas de índice presentes no próximo nível intermediário. Pode haver várias camadas intermediárias em um índice B-Tree. O nó folha no índice B-Tree tem uma página de dados que contém dados de registro ou contém uma página de dados que armazena registros de índice que apontam para registros de dados na tabela.
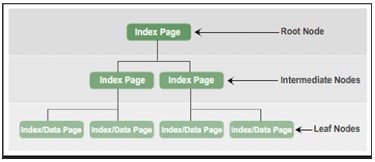
Em resumo, os tipos de nós no índice B-tree estão em conformidade:
- Nó Raiz: contém uma página de índice com um ponteiro para as páginas de índice na camada intermediária.
- Nós intermediários : contém páginas de índice com ponteiros para páginas de índice na camada intermediária ou páginas de índice ou dados na camada folha.
- Nós Folha: Contém páginas de dados ou páginas de índice que apontam para páginas de dados.
Estrutura de pilha
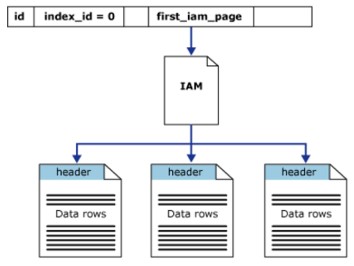
O heap é uma tabela sem um índice clusterizado. Isso significa que, na estrutura heap, as páginas de dados e os registradores não são ordenados. O único link entre as páginas de dados são as informações registradas na página Index Allocation Map (IAM).
Veja mais sobre o termo estrutura de heap na estrutura de dados: https://en.wikipedia.org/wiki/%C4%90%E1%BB%91ng_(c%E1%BA%A5u_tr%C3%BAc_d%E1 %BB% AF_li%E1%BB%87u)#:~:text=In%20khoa%20h%E1%BB%8Dc%20m%C3%A1y%20t%C3%ADnh,%C4%91%C6%B0% E1%BB %A3c%20g%E1%BB%8Di%20l%C3%A0%20max%2Dheap.
O heap tem uma linha em sys.partitions, com index_id = 0 para cada partição usada pelo heap. Por padrão, um heap tem sua própria partição, quando o heap possui várias partições, cada partição terá uma estrutura de heap que contém os dados definidos. Por exemplo, o heap tem 4 partições, haverá 4 estruturas de heap, cada uma em uma partição.
No mínimo, cada heap terá um IN_ROW_DATA alocado por unidade de partição. O heap também tem LOB_DATA alocado por unidade de partição, se contiver uma coluna de objeto grande (LOB). Ele também terá uma alocação ROW_OVERFLOW_DATA por unidade de partição, se não contiver colunas de comprimento conhecido, o limite máximo de tamanho é de 8060 registros.
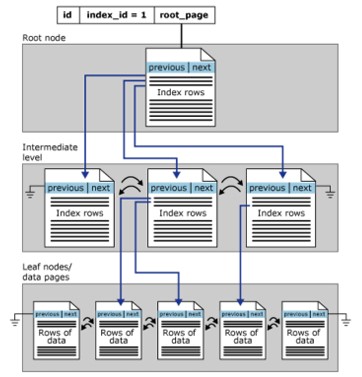
Estrutura de índice clusterizado
Os índices agrupados são organizados em um formato B-Tree. Cada página no índice B-Tree é chamada de nó de índice. Semelhante em conceito, o nó superior do índice clusterizado também é o nó raiz e o nó inferior é o nó folha,
- Os nós folha contêm as páginas de dados básicos da tabela, as camadas raiz e intermediária contêm as páginas de índice que contêm as linhas de índice. Cada índice contém um valor de chave e um ponteiro para uma página intermediária na árvore B ou uma linha de dados na camada folha do índice.
- Por padrão, um índice clusterizado tem uma única partição. Quando um índice clusterizado tem várias partições, cada partição será uma estrutura B-Tree contendo o valor de uma partição especificada.
- O índice clusterizado também possui um LOB_DATA alocado para cada partição se estiver contido em uma coluna LOB (objeto grande). E também possui uma alocação ROW_OVERFLOW_DATA em cada partição única.
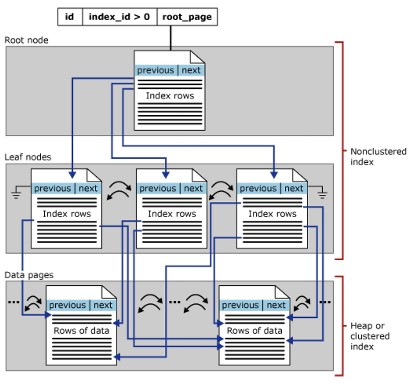
Estrutura de índice não agrupado
Um índice não clusterizado tem as mesmas estruturas B-Tree que um índice clusterizado, mas com as seguintes diferenças:
- As linhas de dados da tabela não são armazenadas fisicamente na ordem determinada por suas chaves indiferenciadas.
- Na estrutura de índice não clusterizado, a camada folha conterá linhas de índice.
- Índices não clusterizados são úteis quando você precisa de várias maneiras de localizar dados.
- Quando um índice clusterizado é recriado ou a opção DROP_EXISTING é usada, o SQL Server cria os índices não clusterizados existentes,
- Uma tabela pode ter até 888 índices não clusterizados
- Crie um índice clusterizado antes de criar um índice não clusterizado.
Índice de armazenamento de colunas (índice de armazenamento de colunas)
O índice Columnstore é um recurso do SQL Server que visa armazenar, recuperar e gerenciar dados usando dados colunares , que são chamados de columnstore.
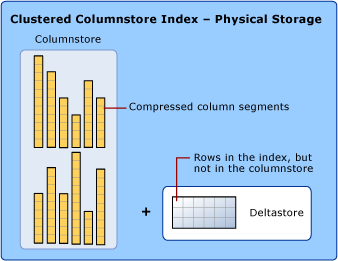
O índice Columnstore usa dois tipos de armazenamento de dados: formato rowstore e columnstore.
O índice Columstore é usado principalmente pelos seguintes motivos:
- Custos de armazenamento reduzidos
- Melhorar o desempenho
Os detalhes dos formatos columnstore,rowstore,deltastore são os seguintes:
- Columnstore : os dados são organizados logicamente em tabelas com linhas e colunas armazenadas fisicamente no formato de dados do grupo de colunas.
- Rowstore : Os dados são organizados logicamente como uma tabela com linhas e colunas e, em seguida, armazenados fisicamente em um formato de dados de grupo de linhas.
- Deltastore : Mantém a posição das linhas quando elas têm poucos dados para compactar em columnstore. Deltastore armazena linhas no formato rowstore.
Índice de Hash
O índice de hash consiste em uma matriz de ponteiros e cada elemento na matriz é chamado de balde de hash.
- Cada bucket tem 8 bytes de tamanho, usado para armazenar o local de memória da chave em uma estrutura de entrada de lista de links.
- Cada entrada é um valor para a chave de índice, que é o endereço correspondente da linha na tabela com otimização de memória.
- Cada entrada aponta para a próxima entrada em uma lista de links, todas encadeadas (o que pode ser interpretado como um bloqueio de cadeia para o bucket atual).
O número de buckets terá que ser definido no momento da definição e ter algumas das seguintes propriedades:
- Links de lista curta são mais rápidos do que links de lista longa.
- Pode haver no máximo 1.073.741.824 buckets no índice de hash.
Índice XML
Um índice XML pode ser criado para colunas do tipo de dados XML. Eles indexarão tags, valores e caminhos dentro de instâncias XML dentro de colunas e aumentarão o desempenho da consulta. Seu aplicativo pode ter uma vantagem com um índice XML nos seguintes casos:
As consultas de coluna XML são comuns na carga de trabalho. O custo do recurso de manutenção do índice xml durante as alterações de dados deve ser considerado.
Quando os valores XML são relativamente grandes e as partes acessadas são relativamente pequenas, a construção do índice evita a necessidade de analisar todos os dados em tempo de execução e é benéfica para pesquisas de índice para processamento de consultas.
Existem dois tipos de índices XML:
- Índice XML primário
- Índice XML secundário
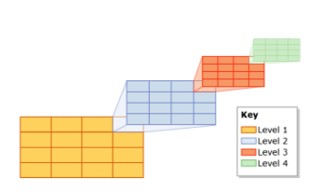
Índice Espacial (índice espacial)
No SQL Server, os índices espaciais usam árvores B, o que significa que os índices devem ser representados em duas dimensões espaciais no arranjo linear da árvore B. Portanto, antes de ler os dados dentro do índice espacial, o SQL Server implementa um modelo de estratificação espacial hierárquica uniforme. O processo de indexação separa o espaço em uma hierarquia de grade de quatro níveis.
Índice de texto completo
A criação e manutenção de um índice de texto completo envolve a indexação usando um processo conhecido como agregação, também conhecido como rastreamento.
Tipos de coleta de informações:
- População completa
- Preenchimento automático/manual com base no rastreamento de alterações
- População incremental feroz no carimbo de data/hora
Criar índice clusterizado
A instrução de índice CREATE CLUSTERED permite que o usuário crie um índice CLUSTERED para uma coluna e tabela especificadas.
Sintaxe:
CREATE CLUSTERED INDEX index_name ON table_name (column1,column2,...);Por exemplo:
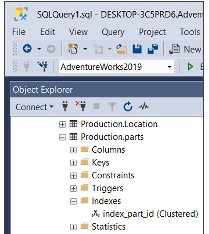
USE AdventureWorks2019 CREATE TABLE Production.Parts( part_id INT NOT NULL, part_name VARCHAR(100) ) CREATE CLUSTERED INDEX ix_parts_id ON Production.parts (part_id);RENOMEAR ÍNDICE
sp_rename é um procedimento armazenado do sistema que permite renomear qualquer objeto que o usuário criou no banco de dados atual, incluindo tabelas, índices e colunas.
Sintaxe:
EXEC sp_rename index_name,new_index_name, N'INDEX';Por exemplo:
EXEC sp_rename N'Production.parts.ix_parts_id', N'index_part_id',N'INDEX';Ou clique com o botão direito do mouse no índice no explorador de objetos e selecione a opção renomear
DESATIVAR ÍNDICE
Para desabilitar o índice, a instrução ALTER INDEX é usada.
Sintaxe
ALTER INDEX index_name ON table_name DISABLE;Por exemplo:
ALTER INDEX index_part_id ON Production.Parts DISABLE; select * from Production.PartsApós desabilitar o índice, ao consultar os dados receberá um erro:
The query processor is unable to produce a plan because the index 'index_part_id' on table or view 'Parts' is disabled.ATIVAR ÍNDICE
Para habilitar a indexação, a instrução ALTER INDEX é usada.
Sintaxe:
ALTER INDEX index_name ON table_name REBUILD;Por exemplo:
ALTER INDEX index_part_id ON Production.Parts REBUILD;REDUZIR ÍNDICE
A instrução DROP INDEX removerá o índice do banco de dados atual.
Sintaxe:
DROP INDEX [IF EXISTS] index_name ON table_name;Por exemplo:
DROP INDEX IF EXISTS index_part_id ON Production.Parts;Índice não agrupado
Um índice não clusterizado é uma estrutura de dados que aumenta a velocidade de recuperação de dados de uma tabela. Ao contrário de um índice clusterizado, um índice não clusterizado classifica e armazena os dados aos poucos das linhas de dados em uma tabela.
Sintaxe:
CREATE [NONCLUSTERED] INDEX index_name ON table_name(column1,column2,...);Por exemplo:
CREATE NONCLUSTERED INDEX index_customer_storeid ON Sales.Customer(StoreID);Índice único
O índice exclusivo garante que as colunas indexkey não contenham valores duplicados.
Pode conter uma ou mais colunas, se o índice único tiver uma coluna, o valor da coluna será único, no caso de um índice único com muitas colunas, a combinação desses valores de coluna é única.
Observação: o índice exclusivo pode ser agrupado ou não agrupado.
Sintaxe para criar um índice exclusivo:
CREATE UNIQUE INDEX index_name ON table_name(column_list);Por exemplo:
CREATE UNIQUE INDEX AK_Customer_rowguid ON Sales.Customer(rowguid);Índice filtrado
O índice filtrado é um índice não clusterizado que permite determinar quais linhas são adicionadas ao índice.
Sintaxe:
CREATE INDEX index_name ON table_name(column_list) WHERE predicate;Por exemplo:
CREATE INDEX index_cust_personID ON sales.Customer(PersonID) WHERE PersonID IS NOT NULL;Tabelas e índices particionados
O SQL Server oferece suporte a dois tipos de tabelas e partições de índice (partições). Os dados de uma tabela particionada e indexada são divididos em uma unidade opcional que pode abranger vários grupos de arquivos no banco de dados. Os dados são particionados horizontalmente, agrupando assim as linhas mapeadas (unidas) em uma partição separada.Todas as partições de uma única tabela ou índice devem estar no mesmo banco de dados. A tabela ou índice é tratado como um objeto ao consultar ou atualizar dados.
O padrão do SQL Server 2019 é compatível com até 15.000 partições.
Benefícios das divisórias:
- Converta ou consulte dados de forma rápida e eficiente.
- Ao lidar com tarefas de persistência em uma ou mais partições, as tarefas são mais eficientes porque seu destino está apenas no conjunto de dados da partição, em vez de na tabela inteira.
- Aumente o desempenho de consultas, dados sobre o tipo de consultas que você executa com frequência e configuração de hardware.
O exemplo cria uma tabela de amostra com as seguintes informações:
CREATE TABLE testing_table(receipt_id BIGINT, date DATE) Especifica como exatamente a tabela será particionada, neste caso a coluna de data, juntamente com
intervalo de valores será adicionado em cada partição. Em relação aos limites da partição, você pode especificar LEFT ou RIGHT (lado esquerdo ou direito)
CREATE PARTITION FUNCTION partition_function (int) AS RANGE LEFT FOR VALUES (20200630,20200731,20200831);Isso significa dividido em 4 partições da seguinte forma:
- Partição 1: todos os registros com data <= 2020-06-30
- Partição 2: todos os registros com data > 2020-06-30 e data <= 2020-07-31
- Partição 3: todos os registros com data > 31-07-2020 e data <= 31-08-2020
- Partição 4: todos os registros com data > 31-08-2020
O código abaixo permitirá que você identifique a região onde cada registro é colocado
(SELECT 20200613 date, $PARTITION.partition_function(2020613) AS PartitionNumber) UNION (SELECT 20200713 date, $PARTITION.partition_function(2020713) AS PartitionNumber) UNION (SELECT 20200813 date, $PARTITION.partition_function(20200813) AS PartitionNumber) UNION (SELECT 20200913 date, $PARTITION.partition_function(20200913) AS PartitionNumber)
Índice XML
Os dados XML são armazenados em um tipo de coluna cujo tipo de dados XML é um tipo de dados que consome muito tamanho, chamados de objetos binários grandes (BLOBs).
Para representar dados xml, o tamanho do tipo de dados pode ser de até 2 GB.
O índice XML é criado na coluna contendo dados xml e armazenado na tabela e no banco de dados.
Por exemplo:
CREATE PRIMARY XML INDEX PXML_PRoduct_Model_Catalog_Description ON Production.ProductModel (CatalogDescription);O índice XML primário contém todos os dados na coluna XML. Para fornecer mais desempenho à consulta XML, você pode adicionar índices secundários. Os índices XML secundários também usam o mesmo conjunto de dados, pois é o índice primário subjacente, mas cria um índice mais específico. , com base no índice primário.
Por exemplo:
CREATE XML INDEX IXML_ProductModel_CatalogDescription_Path ON Production.ProductModel (CatalogDescription) USING XML INDEX PXML_ProductModel_CatalogDescription FOR PATH;Índice de armazenamento de colunas
Sintaxe:
CREATE COLUMNSTORE INDEX IX_SalesOrderDetail_ProductIDOrderQty_ColumnStore ON Sales.SalesOrderDetail (ProductID,OrderQty);A criação desse índice melhorará o agrupamento por consulta ao usar funções agregadas, mas teste novamente com seu ambiente, pois em seu SSMS atualmente em execução este erro de tempo limite de comando.
SELECT ProductID,SUM(OrderQty) FROM Sales.SalesOrderDetail GROUP BY ProductId;
Bài viết liên quan:

Dịch vụ thiết kế Wesbite

