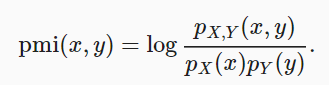
Método de seleção de recursos em Machine Learning.
Na verdade, nem todos os dados são claros, os recursos são úteis para o modelo. Por exemplo, quando queremos prever o preço de uma casa, não importa se o proprietário é um menino ou uma menina. Portanto, é muito importante escolher recursos que sejam úteis ao modelo, ajudando a reduzir o número de dimensões dos dados de entrada.
Basicamente, usaremos probabilidade para calcular a relação entre cada feição e o campo alvo a ser previsto. Mas a ideia é que, usar qualquer fórmula ou medida para determinar se aquela característica não é boa ainda é uma grande sabedoria. Neste artigo, você e eu vamos aprender através de algumas fórmulas e cálculos!
Mục lục
Método de seleção de recursos
Os algoritmos de seleção de recursos podem ser divididos em três categorias: métodos de filtro, métodos de wrapper e métodos incorporados.
Filtro
Esse cara tem as seguintes características:
- Depende das características dos dados
- Fornecerá desempenho inferior aos métodos wrapper ou métodos incorporados.
- Métodos: Variância , Correlação , Seleção Univariada , Seleção Multivariada .
Sobre recursos constantes, quase constantes e duplicados.
Características constantes : exibem apenas um valor para todas as observações no conjunto de dados.
O método mais simples para lidar com recursos constantes. Vamos definir um limite (limiar) para a variação, os recursos que não atenderem a esse limite serão descartados. (Pode usar sklearn para processar)
de sklearn.feature_selection importar VarianceThreshold sel = VarianceThreshold(threshold=0) # fit encontra os recursos com variação zero. sel.fit(X_train) # método get_support() retorna quais recursos são retidos. retidos_features = sel.get_support()
Ela retornará uma sequência bool, basta olhar para ela para saber quais características não satisfazem a condição.
Recursos quase constantes : Semelhante aos recursos constantes acima, só podemos ajustar o limite para tornar a condição mais rigorosa (por exemplo, limite = 0,01, o recurso será descartado quando tiver 99% de valor).
Características duplicadas : São características semelhantes, por exemplo, uma característica original e outra característica é o codificador de rótulo da característica original, então essas duas características são equivalentes, podemos descartar uma característica. Ou várias linhas idênticas.
Método:
- Para conjunto de dados pequeno: em pandas, há uma função para avaliar se um dataframe contém linhas duplicadas. Quanto à checagem das colunas, ainda usamos a função duplicada(), basta transpor a matriz.
- Com grande conjunto de dados: Se usar transposição com grandes dados definitivamente consome muita memória e é inviável. Assim, podemos usar o loop para encontrar colunas duplicadas ou usar a biblioteca numpy.
for_, idx = np.unique(df.to_numpy(), axis=1, return_index=True) df_uniq = df.iloc[:, np.sort(idx)]
Correlação
Usar a correlação entre duas ou mais variáveis também é uma boa maneira de remover recursos com baixa correlação. A remoção de recursos altamente correlacionados ajuda o modelo linear a funcionar melhor, evitando viés entre os recursos.
- Podemos testar o recurso com um alvo de baixa correlação, podemos descartar o recurso.
- Ou verifique a correlação entre recurso e recurso se dois recursos tiverem alta correlação entre si, talvez esses dois recursos tenham a mesma informação e possamos descartar 1 recurso para reduzir a dimensionalidade dos dados de entrada.
Como determinar o coeficiente de correlação .
Coeficiente de correlação de Pearson
soma((x1 -x1.média) * (x2 - x2.média) * (xn - xn.média)) / var(x1) * var(x2) * var(xn)
- O coeficiente de Pearson tem um valor no intervalo [-1,1]
- A ideia é calcular a correlação entre as feições, se 2 feições tiverem uma correlação maior que o threshold que eu estabeleci, eu descarto uma dessas 2 feições.
corrmat = X_train.corr()
# enredo
figo, ax = plt.subplots()
fig.set_size_inches(11,11)
sns.heatmap(corrmat)
correlação def(df, limite):
col_corr = set()
corrmat = df.corr()
for i in range(len(corrmat.columns)):
para j no intervalo(i):
# interessado em valores de coeficiente abs
if abs(corrmat.iloc[i, j]) > limite:
col_corr.add(corrmat.columns[i])
retornar col_corr
corr_feats = correlação(X_train, 0,8)
X_train.drop(labels=corr_feats, axis=1, inplace=True)Medidas estatísticas
Existem alguns métodos e critérios para selecionar recursos de acordo com métodos estatísticos, como segue:
- Ganho de informações
- ROC-AUC/RMSE univariado
Para cada um dos métodos acima, haverá 2 etapas da seguinte forma:
- Avalie os recursos de acordo com um determinado critério: Cada recurso terá uma avaliação independente de outros recursos ao considerar sua relação com o destino.
- Selecionando feições de alta classificação: Podemos aplicar modelos de classificação ou regressão para avaliar uma característica de alta classificação?. E, claro, o quanto saber se a classificação é alta ou baixa depende de você.
Algumas ressalvas: podemos aplicar recursos duplicados ou correlacionados antes de realizar esta etapa. E esse método também tem uma grande desvantagem de poder haver 2 recursos combinados, isso afetará o destino e se aplicarmos esse método apenas a cada recurso em termos de tagert, pode levar a erros. Portanto, é necessário aplicar mais métodos para avaliar entre características e alvos.
Informação mútua (ganho de informação)
Esse método compara a probabilidade de que xey ocorram simultaneamente na distribuição e combina com o caso em que as duas distribuições são independentes.
informação mútua = soma{i,y} P(xi, yj) * log(P(xi,yj)/P(xi)*P(yj))Se x e y forem independentes, a informação mútua será 0.
Podemos usar a biblioteca do python para selecionar recursos:
- Use
sklearn.feature_selection.mutual_info_regressionno modelo de regressão. - E
mutual_info_classifpara selecionar com classificação de modelo.
Execute o cálculo de informações mútuas entre variáveis e alvos. Retorna informações mútuas para cada recurso. Quanto menor o valor, menor a informação sobre esse recurso com o destino. (O pré-processamento é recomendado antes de aplicar este método).
ROC-AUC/RMSE univariado
A ideia é calcular o ROC-AUC de cada recurso e depois usar o modelo de aprendizado de máquina para prever o alvo. Aqui podemos usar a árvore de decisão e avaliar de acordo com ROC-AUC ou RMSE. A partir daí, selecionaremos recursos com métricas altas.
# usa o conjunto de dados bnp-paribas roc_vals = [] for feat em X_train.columns: clf = DecisionTreeClassifier() clf.fit(X_train[feat].fillna(0).to_frame(), y_train) y_scored = clf.predict_proba(X_test[feat].fillna(0).to_frame()) roc_vals.append(roc_auc_score(y_test, y_scored[:,1])))
rocvals = pd.Series(roc_vals) rocvals.index = X_train.columns rocvals.sort_values(ascendente=Falso) # número de recursos mostra um valor roc-auc maior que aleatório. len(rocvals[rocvals>0.5])
Resumo:
Através deste estudo, você e eu aprendemos alguns métodos de seleção de recursos, reduzindo o número de dimensões de entrada para tornar o modelo de treinamento mais fácil.
Bài viết liên quan:











Dịch vụ thiết kế Wesbite
