Modelo entidade-relacional (modelo ER) e normalização de dados (normalização)
Um modelo de dados é um grupo de ferramentas conceituais usadas para descrever dados, seus relacionamentos e seus significados. Eles também incluem restrições de consistência que os dados devem seguir. No modelo Entidade – Relacionamento, o relacionamento de rede ou o modelo hierárquico são todos exemplos de modelos de dados, veja o artigo Introdução aos modelos de banco de dados. , introduza o Conceito RDBMS (Related database management system) para entender melhor. O desenvolvimento de cada banco de dados começa com as etapas básicas de análise de dados para encontrar o modelo de dados mais adequado para representar os dados.
Mục lục
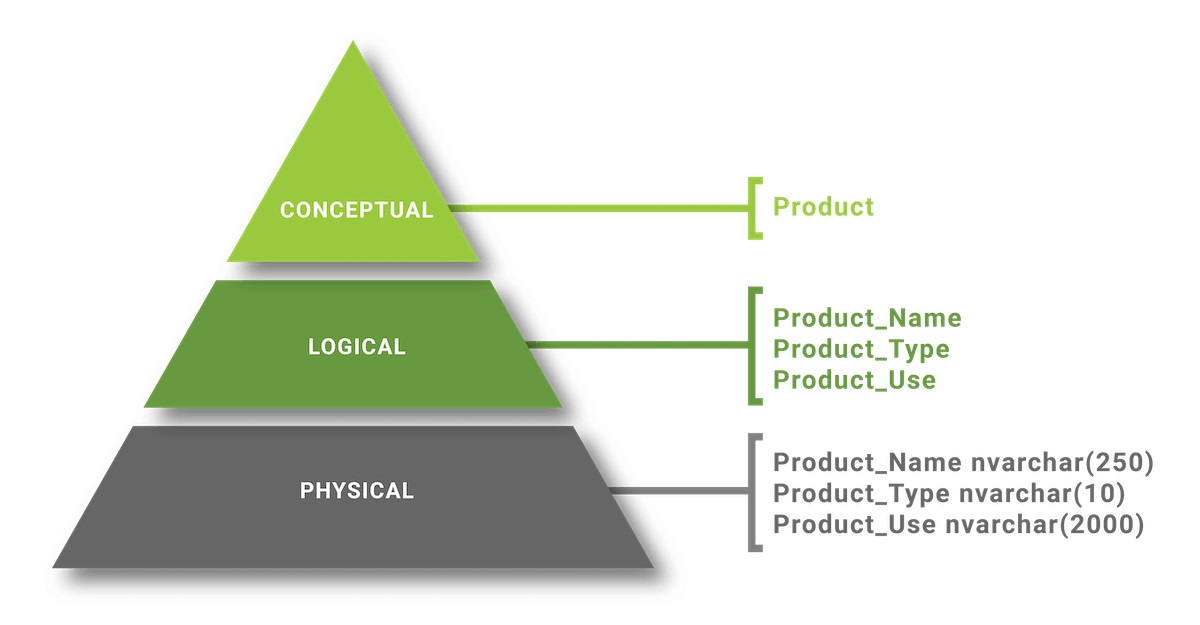
Modelagem de dados
O processo de aplicar um modelo de dados apropriado aos dados, a fim de organizá-los e estruturá-los, é conhecido como modelagem de dados .
A modelagem de dados também é essencial para o desenvolvimento de banco de dados, bem como para o planejamento e design de qualquer projeto. Construir um banco de dados sem um modelo de dados é como desenvolver um projeto sem um plano ou design. O modelo de dados ajuda os desenvolvedores de banco de dados a definir os relacionamentos de tabelas, chave primária, chave estrangeira , procedimento armazenado, gatilhos . é gatilho de evento)… no banco de dados.
As etapas de modelagem de dados são as seguintes:
- Modelagem Conceitual de Dados : Os dados são modelados por relacionamentos em dados de nível superior. O objetivo deste modelo é organizar, delimitar e definir conceitos e regras e processos de negócio . Uma vez que o modelo de dados conceitual é criado, ele pode ser adaptado e transformado em um modelo de dados lógico.
- Modelagem de dados lógicos : os dados modelados descrevem os dados e seus relacionamentos em detalhes. Os dados modelados criam modelos lógicos do banco de dados. O principal objetivo do modelo é desenvolver um mapa técnico de regras e estruturas de dados. O modelo de dados lógico servirá como base para a criação de um modelo de dados físico.
- Modelagem de Dados Físicos: Este modelo descreve como o sistema será implementado usando um sistema de gerenciamento de banco de dados específico. Esse modelo geralmente é criado por administradores de dados e desenvolvedores com o objetivo principal de implementar o banco de dados real.
Modelo Entidade-Relacionamento – Modelo ER
Os modelos de dados podem ser classificados em 3 grupos diferentes:
- Modelo lógico baseado em objeto
- Modelo lógico baseado em registros
- Modelo físico
Os modelos Entidade-Relacionamento (ER) pertencem à primeira categoria – modelos lógicos baseados em objetos .
O modelo é baseado em uma ideia simples de contato com a realidade. Os dados podem ser pensados como objetos do mundo real chamados objetos e os relacionamentos que existem entre eles. Por exemplo, dados sobre funcionários que trabalham para uma organização podem ser considerados como uma coleção de funcionários e uma coleção de diferentes departamentos (departamentos) que compõem a organização. Tanto os funcionários quanto os departamentos são objetos do mundo real. Funcionário de um departamento. Assim, uma relação de 'pertencimento' associa um funcionário a um departamento específico.

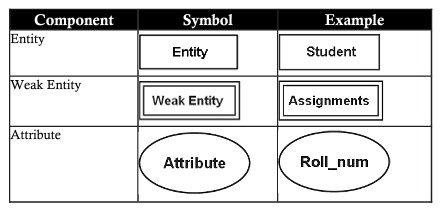
Um modelo ER contém cinco componentes básicos:
| Entidade (entidade) | Uma entidade é um objeto do mundo real que existe fisicamente e é distinguível de outros objetos. Por exemplo: pessoal, departamentos, alunos, clientes, contas ….. pode ser chamado de entidade |
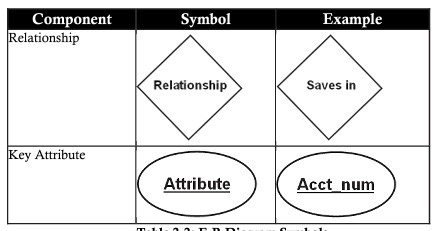
| Relacionamento (relacionamento) | Um relacionamento é uma associação ou associação que existe entre uma ou mais entidades. Por exemplo: pertencer, possuir, trabalhar, economizar, comprar…. |
| Atributos (atributos) | Um atributo é um recurso que uma entidade possui. Os atributos ajudam a distinguir uma entidade da outra. Exemplo para 2 atributos aluno e cliente, a mesma pessoa mas possuem atributos diferentes quando representados no banco de dados: – Entidade aluno tem atributos student_id, nome, idade, marca. – O cliente da entidade tem atributos customer_id,name,age,phone,address |
| Conjunto de entidades (conjunto de entidades) | Um conjunto de entidades é uma lista (conjunto) de objetos semelhantes. Por exemplo, a lista de alunos de uma escola (de acordo com um padrão comum com os mesmos atributos) é chamada de conjunto de entidades do aluno. |
| Conjunto de relacionamento | Uma lista (conjunto) de relacionamentos entre dois ou mais conjuntos de entidades é chamada de conjunto de relacionamentos. Por exemplo, os alunos estudam muitos assuntos diferentes, o conjunto de todos os relacionamentos de "aprendizagem de assunto" que existem entre 2 entidades aluno e assunto pode ser chamado de conjunto de relacionamentos de "aprendizagem". assuntos" |
Um relacionamento de associação entre uma ou mais entidades e pode ter 3 tipos de relacionamentos da seguinte forma:
Auto-relacionamentos
A relação entre uma entidade e objetos semelhantes é chamada de auto-relação . Por exemplo, um gerente e um membro de uma equipe são funcionários e pertencem ao mesmo conjunto de entidades. Os membros da equipe trabalham para a gerência, portanto, existe um relacionamento "trabalho para" entre duas entidades de RH diferentes, mas essas pessoas estão no mesmo conjunto de entidades.
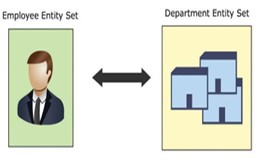
Relações binárias
O relacionamento que existe entre entidades localizadas em 2 conjuntos de entidades diferentes é chamado de relacionamento binário . Por exemplo, um funcionário pertence a um departamento. Existe um relacionamento entre duas entidades localizadas em dois conjuntos de entidades diferentes. A entidade de RH está no conjunto de entidades (funcionário), a entidade de departamento está no conjunto de entidades (departamento).
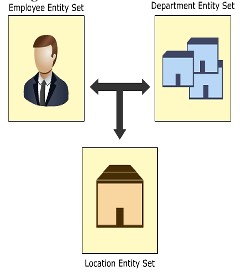
Relacionamento ternário (relacionamento de 3 pessoas)
Simplificando, esse relacionamento é um relacionamento de 3 entidades participantes, que é chamado de relacionamento ternário . Por exemplo, um funcionário trabalha para o departamento financeiro de uma determinada filial da organização. Aqui, existem 3 entidades diferentes: pessoal, departamento, filial e pessoal será associado ao departamento por meio do conjunto de entidades que representa a filial.
Os relacionamentos também podem ser classificados de acordo com as cardinalidades de mapeamento. Os diferentes tipos de mapeamento são distinguidos da seguinte forma:
Um para um (mapeamento de um para um)
Esse mapeamento existe quando o objeto de um conjunto de entidades pode ser associado a apenas uma instância de outro conjunto de entidades. Por exemplo, o número de identificação do cidadão de um cidadão, que será vinculado direta e exclusivamente ao código de licença de motocicleta de um cidadão. Não é possível que um cidadão com um número de identificação tenha vários códigos de licença de motocicleta. É chamado de uma luz distante ou um relacionamento um-para-um.

Um para muitos (mapeamento de um para muitos)
Esse tipo de mapeamento é usado quando uma entidade em um conjunto de entidades está associada a mais de uma entidade em outro conjunto de entidades. Por exemplo, se houver muitos alunos em uma turma, um mapeamento de um para muitos geralmente é usado para representar esse mapeamento. As pessoas costumam chamar isso de relacionamento de 1 para muitos ou mapeamento de 1 para muitos.
Muitos para um (mapeamento de muitos para um)
Esse tipo de mapeamento é usado quando várias entidades em um conjunto de entidades estão associadas a uma entidade de outro conjunto de entidades. Entendemos que esse mapeamento é o oposto de um mapeamento de um para muitos. Por exemplo, uma classe tem muitos alunos.
Muitos para muitos (mapeamento de muitos para muitos)
Esse tipo de mapeamento é usado quando várias entidades de um conjunto de entidades estão associadas a muitas entidades de outro conjunto de entidades.
Por exemplo, uma loja tem muitos produtos à venda, o pedido de cada cliente ao comprar incluirá muitos produtos diferentes, podemos ver que 1 pedido pode ter muitos produtos, mas um produto também aparece em muitos pedidos, este é o melhor exemplo de muitos -para-muitos mapeamento.
Além disso, o modelo ER também adere a alguns conceitos como segue:
Chave primária (chave primária)
A chave primária é um atributo usado para determinar a exclusividade de uma entidade para um conjunto de entidades. Na estrutura do banco de dados, geralmente é sempre aconselhável ter uma coluna usada como chave primária na tabela (conjunto de entidades).
Conjuntos de entidades fracos
Conjuntos de entidades que não possuem um atributo para definir uma chave primária são chamados de conjuntos de entidades fracos.
Conjuntos de entidades fortes
Conjuntos de entidades que possuem atributos para definir chaves primárias são chamados de conjuntos de entidades fortes.
Diagrama de relacionamento de entidade (Diagrama ER)
Um diagrama ER é uma representação gráfica de um modelo ER. No diagrama ER, use símbolos para representar efetivamente os diferentes componentes do modelo ER .
Os atributos no modelo ER podem ser classificados da seguinte forma:
Multivalorado (multivalorado)
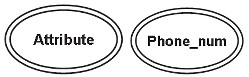
Um atributo multivalorado é ilustrado por uma elipse de duas linhas, que possui mais de um valor para pelo menos uma instância de sua entidade. Esse atributo pode ter um limite superior e um limite inferior especificados para qualquer valor de entidade individual.
Por exemplo, o atributo phone_number pode armazenar vários valores para uma entidade. (Uma pessoa pode ter mais de um número de telefone)
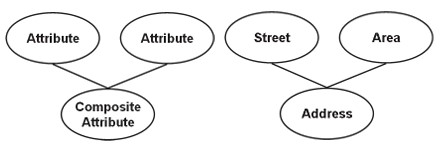
Composto (sintético)
Um atributo composto em si pode conter dois ou mais atributos, os subatributos são propriedades básicas e têm seus próprios significados independentes.
Por exemplo, o atributo de endereço geralmente é um atributo composto, por exemplo, ao representar um endereço de empresa 6/203 Truong Chinh – Thanh Xuan – HN, 6/203 Truong Chinh será o endereço, Thanh Xuan o salvará em District, Hanoi é cidade
Derivado (atributo derivado)
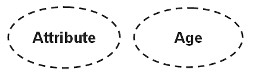
Propriedades derivadas são atributos cujo valor depende completamente de outro atributo e são representados por uma elipse composta de elipses.
O atributo idade de uma pessoa é o melhor exemplo de atributos derivados. Para uma entidade de pessoa específica, a idade de uma pessoa pode ser determinada a partir da data atual e da data de nascimento da pessoa.
As etapas para estruturar o diagrama ER são as seguintes:
- Colete todos os dados que tiveram que ser modelados.
- Defina dados que podem ser modelados como entidades do mundo real.
- Identifique os atributos para cada entidade.
- Classifique conjuntos de entidades em conjuntos de entidades fracos ou fortes.
- Classifique os atributos de entidade como atributos-chave, atributos multivalorados, atributos compostos, atributos derivados, etc.
- Identifique as relações entre os diferentes fatores de manipulação.
- Usando símbolos diferentes, desenhe os elementos de sedução, suas propriedades e seus relacionamentos. Use sysbols apropriados ao plotar propriedades.
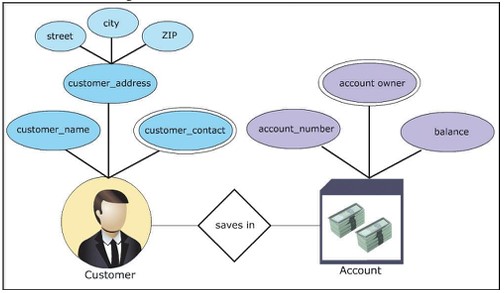
Por exemplo, construir um banco de dados simulando um banco, com gerenciamento de clientes e contas. O diagrama ER para o cenário pode ser construído da seguinte forma:
- Coleta de dados: esse negócio precisa de uma lista de contas e clientes que desejam depositar dinheiro.
- Identificar entidade: existem 2 entidades cliente, conta
- Defina propriedades:
- Cliente: nome, endereço, contato
- Conta: id, proprietário, saldo
- Classificação do conjunto de entidades
- cliente: conjunto de entidades fraco
- conta: conjunto de entidades forte
- Classificar propriedades
- conjunto de entidades do cliente: endereço – composto, contato – multivalorado
- conjunto de entidades conta: id – chave primária, proprietário – multivalores
- Definir relacionamento: cliente deposita dinheiro na conta, o relacionamento será "depósito"
- gráfico Desenhe o modelo ER .
Normalização (normalizar dados)
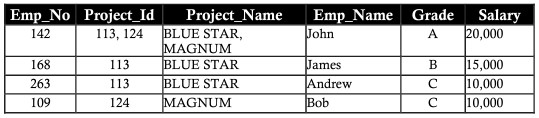
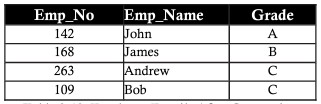
Normalmente, todos os bancos de dados são identificados por um grande número de colunas e registros. Esta abordagem tem algumas limitações. Considere o exemplo a seguir em que duas entidades são salvas na mesma tabela de funcionários em projetos. Inclua os detalhes do funcionário, bem como os detalhes do projeto em que está trabalhando:
Os conceitos de problemas encontrados quando os dados não são normalizados são os seguintes:
Anomalia de repetição
Colunas como project_id, project_name, salário possuem dados em registros repetidos, essa repetição dificulta tanto o desempenho de recuperação de dados quanto a capacidade de armazenamento. Essa repetição de dados é chamada de anomalia de repetição
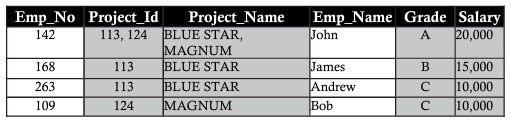
Anomalia de inserção
Suponha que o novo membro do departamento seja uma nova funcionária chamada Ann. Ann não tem um projeto atribuído no momento. Insira os detalhes dela na tabela com células em branco nas colunas denominadas Project_id, Project_name. Deixar as colunas em branco leva a alguns problemas mais tarde. A anomalia criada pela operação de inserção é chamada de anomalia de inserção.
Excluir anomalia (excluir anomalia/anomalia)
Suponha que Bob seja retirado do projeto MAGNUM. Exclua um registro de projeto MAGNUM cujo nome do funcionário seja Bob, incluindo o número do funcionário (employee_number), classificação (grau) e salário (salário). A perda de dados afeta os detalhes das informações pessoais de Bob, essa perda pode ser vista na tabela abaixo. Os dados perdidos devido à exclusão acima são chamados de anomalia de exclusão.

Atualizando anomalia
Suponha que John tenha recebido um aumento ou um corte salarial. As mudanças no salário ou nota de John precisam ser refletidas em todos os projetos em que John trabalha. Isso é chamado de anomalia de atualização.
A tabela que detalha os funcionários do departamento é chamada de tabela não normalizada. Essas limitações sugerem que a normalização é necessária.
A nomarlização é um processo de remoção de redundâncias e dependências indesejadas. Inicialmente, Codd (1972) descreveu três formas de normalização (1NF, 2NF e 3NF), todas baseadas em dependências entre os atributos da relação. A quarta forma normal (4FN) e a quinta forma normal (5FN) são baseadas na associação multivalorada e dependente e foram introduzidas posteriormente.
Primeira Forma Normal (1FN)
Os passos para completar o 1NF são os seguintes:
- Crie tabelas separadas para cada grupo de dados relacionados
- As colunas da tabela precisam armazenar valores primos (podem entender valores primitivos)
- Todos os atributos de chave primária precisam ser definidos
Considerando o exemplo da tabela acima, precisamos normalizar a tabela dividindo claramente as duas entidades projeto e funcionário
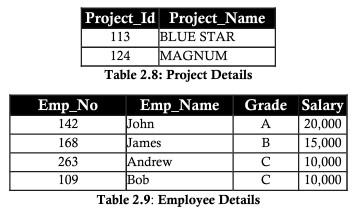
Segunda Forma Normal (2FN)
As tabelas são chamadas de 2NF se os seguintes requisitos forem atendidos:
- Atenda aos requisitos da 1NF
- não há dependências nas tabelas
- As tabelas são vinculadas por meio de chaves estrangeiras.
Considerando o exemplo acima, utilizamos o 2NF para fazer a ligação entre a tabela de projetos e a tabela de funcionários (para saber a qual funcionário o projeto está atribuído) por meio de uma tabela intermediária.
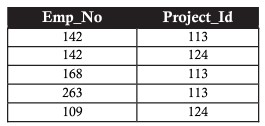
Terceira Forma Normal (3FN)
Para completar a normalização 3NF, os seguintes requisitos devem ser atendidos:
- A tabela deve atender aos requisitos da 2NF
- as tabelas não devem ter colunas dependentes nelas
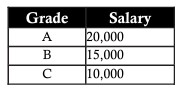
Continuando o exemplo acima, na tabela de funcionários, vemos que a coluna Salário depende da coluna Nota conforme a fórmula geral: A – 20.000 | B – 15.000 | C – 10.000. Então, para normalizar esses dados, vamos dividir a tabela de funcionários, que armazena apenas a nota, e uma tabela que mostra a nota e o salário. Ao fazer isso, você pode adicionar e atualizar notas posteriormente para atender facilmente às suas necessidades sem afetar os dados gerais.

Desnormalização
Ao normalizar os dados, os dados redundantes são minimizados. Isso significa que o tamanho do espaço de armazenamento de banco de dados necessário no banco de dados será reduzido. No entanto, eles também têm algumas limitações, como segue:
- As instruções de consulta se tornarão mais complexas ao conectar dados entre tabelas diferentes
- Na verdade, a instrução de consulta pode envolver mais de 3 tabelas, dependendo das necessidades de informação (aumentando a complexidade na escrita de instruções de consulta, programadores y/c ou DBAs altamente especializados)
Se as instruções de consulta de junção forem usadas com muita frequência, o desempenho do banco de dados diminuirá, o tempo de processamento da CPU aumentará, afetando a velocidade do programa. Portanto, em alguns casos, dados redundantes ainda podem ser usados para aumentar o desempenho do banco de dados, o que significa aceitar armazenamento de dados redundantes (sacrificar a capacidade de armazenamento para aumentar o desempenho). consulta), chamada de desnormalização (desnormalização de dados)
Operadores Relacionais
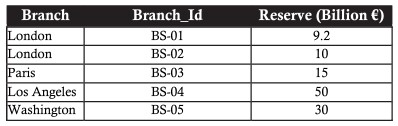
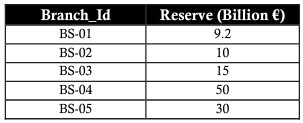
O modelo relacional é baseado em uma base sólida de álgebra relacional. A álgebra relacional consiste em um conjunto de operadores que operam em relações. Cada operador recebe uma ou duas relações como entrada e cria uma nova relação como saída. Considere a tabela de dados bancários de exemplo com as seguintes filiais:
SELECIONAR (seleção)
O operador SELECT é usado para recuperar dados que satisfaçam as condições exigidas. O caractere sigmóide (ð) é usado para representar uma seleção.
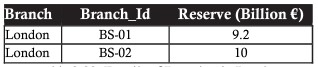
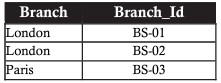
O exemplo abaixo é uma tabela ao selecionar registros com filial em Londres
Ou uma transação que exija a abertura de agências com reversões superiores a 20 bilhões de euros

PROJETO (projeção)
O operador PROJECT é usado para fazer referência aos detalhes de uma tabela relacional. O operador PPROJECT exibe apenas os campos obrigatórios e deixa de fora os campos não obrigatórios na coluna. O operador PROJETO é representado pelo caractere pi “π”.
O exemplo abaixo usa o operador PROJECT para obter o id e reverter para uma empresa sem obter o nome da filial:
PRODUTO (multiplicação/produto)
O operador PRODUCT é utilizado para combinar superficialmente informações de duas tabelas relacionadas, representadas pelo caractere "x".
Por exemplo, temos uma tabela de empréstimos como esta:

Use o operador PRODUCT usado para combinar as tabelas de agências e empréstimos para representar reservas totais e empréstimos totais:
A multiplicação combina cada registro da primeira tabela com todos os registros da segunda tabela, ou seja, cria todas as combinações possíveis entre os registros das duas tabelas.
UNIÃO (associação)
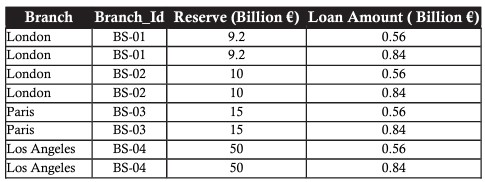
Digamos que, dados os dados da amostra do banco acima, a administração queira contratar agências que tenham reservas ou empréstimos de menos de 20 bilhões de euros. A tabela resultante deve conter agências com reservas ou empréstimos inferiores a 20 bilhões de euros, ou ambas as colunas que atendam aos critérios.
Esta visualização é a combinação entre dois conjuntos de dados, os passos por sua vez são os seguintes:
- Arrecadação de sucursais com reservas inferiores a 20 mil milhões de euros
- Conjunto de sucursais com crédito inferior a 20 mil milhões de euros
- Mesclar os 2 conjuntos, garantindo que a agência com as mesmas reservas e empréstimos abaixo de 20 bilhões de euros apareça apenas uma vez
INTERSEÇÃO (Intersecção)
Suponha que queiramos saber qual desses ramos tem tanto baixas reservas quanto baixos empréstimos. A solução seria usar o operador INTERSECT de interseção. O operador INTERSECT produz os dados corretos em todas as tabelas às quais é aplicado. Ele é baseado na teoria dos conjuntos de interseção e é representado pelo símbolo " " . O resultado será o cruzamento de duas tabelas que incluem a lista de sucursais que cumprem tanto os critérios de reserva como de empréstimo com menos de 20 mil milhões de euros.

DIFERENÇA (Milagroso)
Voltando ao exemplo acima, se quisermos saber qual agência tem reservas baixas mas não tem empréstimos, a solução é usar o (DIFERENÇA). A notação é denotada pelo caractere "-", sua saída ainda é uma união de 2 tabelas diferentes, mas a diferença é que ela apenas recupera o valor correto de uma tabela, não da outra, portanto, as agências com reservas baixas, mas sem empréstimos, não ser retirado.

JUNTE
A concatenação é uma extensão da multiplicação que permite a seleção do resultado da multiplicação. Por exemplo, se as reservas e empréstimos das agências forem menores com o PRODUTO acima, os dados serão redundantes e precisarão ser agregados e reduzidos. A saída do JOIN retornará apenas as agências recém-listadas que tenham reservas inferiores a 20 bilhões de euros e capital de empréstimo.

DIVIDIR (Divisão/quociente)
Suponha que queremos ver novamente o valor da agência e as reservas de todas as agências que possuem empréstimos. Essa situação precisa usar a permissão DIVIDE para lidar. Basta dividir a tabela Branch Reverse Details (2.19) pela lista de branches e a coluna Branch_id da tabela BranchLoanDetails (2.23). O resultado é como mostrado abaixo

Nota: as propriedades da tabela de divisão devem ser sempre um subconjunto da tabela dividida. A tabela resultante sempre deixa as propriedades da tabela dividida em branco e os registros não correspondem aos registros na tabela dividida.
Bài viết liên quan:











Dịch vụ thiết kế Wesbite
