Pipeline em aprendizado de máquina
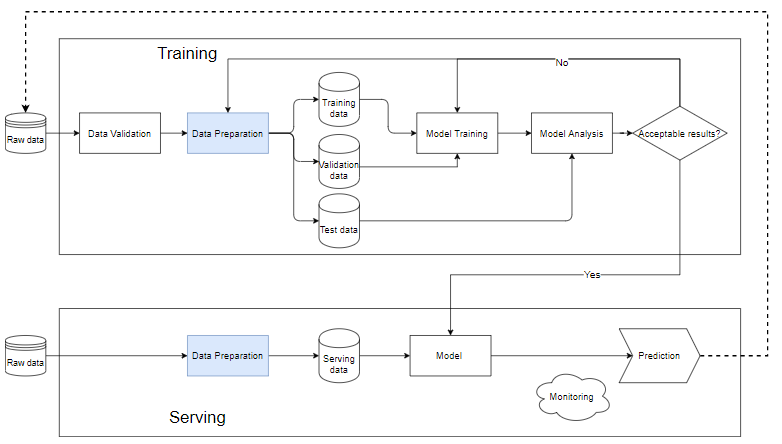
O pipeline no ML é uma maneira de automatizar o fluxo de trabalho de criação de um modelo de aprendizado de máquina. Quase todo sistema de aprendizado de máquina possui componentes como o diagrama abaixo, é um pipeline de aprendizado de máquina.
Mục lục
O que é um pipeline no aprendizado de máquina?
Bloco de treinamento
- Validação de dados: é a etapa de teste de dados, determinando se os dados recém-adicionados estão satisfeitos com os dados do banco de dados. Devido ao fato de que novos dados sempre serão adicionados para executar o trem.
- Depois que os dados brutos são limpos para a etapa de preparação de dados, eles são divididos em um conjunto de dados de treinamento, um conjunto de dados de treinamento e um conjunto de dados de validação. dados de teste para determinar a qualidade do modelo após o processo de treinamento.
- Os dados de treinamento são colocados no bloco "treinamento do modelo" para treinar o modelo.
- Após o treinamento, realizamos a análise no bloco "análise do modelo" para analisar a qualidade. Verifique se as métricas no conjunto de teste são boas, os resultados previstos e os resultados reais são equivalentes, a velocidade de previsão,…
- Quando os dados são passados pelo bloco de análise do modelo, o modelo será usado para executar os dados reais na etapa "Servindo". Caso contrário, precisamos revisar o modelo ou filtrar os dados.
Servindo . Bloquear
- Quando o modelo ainda é stub, devemos usar um pequeno conjunto de dados, executar o teste, se a qualidade for aceitável, podemos fazê-lo em todos os dados.
- A Preparação de Dados ajuda a limpar e criar dados que terão que ser os mesmos do modelo no bloco de treinamento.
- Cada problema diferente requer um sistema de monitoramento e alerta diferente. Normalmente, independentemente dos dados de entrada, o modelo ainda produzirá um resultado previsível, possivelmente aleatório. Se esses resultados não forem monitorados e alarmados com cuidado, levando a mudanças repentinas na qualidade do modelo e nas reações dos usuários, a reputação e a receita da empresa serão afetadas.
Por que construir pipelines?
- Os sistemas de aprendizado de máquina geralmente consistem em muitos componentes pequenos, como processamento de dados, treinamento de modelos, avaliação de modelos, previsão com novos dados, etc. Sem construir um pipeline completo com cada componente separado Obviamente, haverá muitos problemas. Separar seu sistema passo a passo e juntá-lo novamente em um pipeline facilita a localização de erros ao treinar o modelo.
- Construir um pipeline também nos ajuda a trabalhar melhor em equipe. Se houver um grupo grande, podemos dividi-lo em pequenos grupos: um grupo especializado em limpeza de dados, um grupo especializado em criar recursos, outro grupo constrói e treina o modelo e outro grupo se concentra na avaliação e monitora a atividade do modelo. Esses blocos de trabalho, se separados e especializados, ajudarão as equipes a detalhar para melhorar a qualidade de cada bloco sem se preocupar em quebrar o código de outra equipe.
Exemplo simples
Aqui apresentarei um pipeline completo, não entrarei em cada linha de comando, mas quero usar este exemplo para fornecer uma visão geral de um pipeline. Você pode ver o código completo aqui
O primeiro passo é importar as bibliotecas necessárias.
from pathlib import Path import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.ensemble import RandomForestClassifier from sklearn.impute import KNNImputer, SimpleImputer from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.pipeline import Pipeline from sklearn.preprocessing import OneHotEncoder, RobustScalerCarregar dados
titanic_path = ( "https://github.com/CongSon01/titanic_pipeline/" ) df_train_full = pd.read_csv(titanic_path + "train.csv") df_test = pd.read_csv(titanic_path + "test.csv")
Descarte os dados ausentes, não traz eficiência ao modelo.
df_train_full.drop(columns=["Cabin"]) df_test.drop(columns=["Cabin"]);Antes de entrar na etapa de criação de recursos, precisamos dividir os dados de treinamento/teste. Aqui, os 10% aleatórios dos dados rotulados originais são extraídos como dados de validação , os 90% restantes são mantidos como dados de treinamento . A coluna Sobreviveu é a coluna de rótulo que é dividida em uma variável separada contendo o rótulo:
df_train, df_val = train_test_split(df_train_full, test_size=0.1) X_train = df_train.copy() y_train = X_train.pop("Survived") X_val = df_val.copy() y_val = X_val.pop("Survived")Os recursos de processamento com tipos de dados categóricos ou numéricos terão métodos de processamento diferentes. Primeiro lidamos com dados categóricos.
cat_cols = ["Embarked", "Sex", "Pclass"] cat_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="most_frequent")), ("onehot", OneHotEncoder(handle_unknown="ignore", sparse= False )), ] )Em seguida, aplicamos num_transformer a dois recursos numéricos:
num_cols = ["Age", "Fare"] num_transformer = Pipeline( steps=[("imputer", KNNImputer(n_neighbors=5)), ("scaler", RobustScaler())] )Combinando dois processadores obtemos um processador completo. A classe ColumnTransformer do scikit-learn ajuda a combinar transformadores:
preprocessor = ColumnTransformer( transformers=[ ("num", num_transformer, num_cols), ("cat", cat_transformer, cat_cols), ] )Por fim, combinamos o processador específico do pré-processador com um classificador simples que é frequentemente usado com dados tabulares, RandomForestClassifier, para obter um pipeline full_pp que inclui processamento de dados e modelos. Full_pp é ajustado aos dados de treinamento (X_train, y_train) e usado para aplicar aos dados de teste.
# Full training pipeline full_pp = Pipeline( steps=[("preprocessor", preprocessor), ("classifier", RandomForestClassifier())] ) # training full_pp.fit(X_train, y_train) # training metric y_train_pred = full_pp.predict(X_train) print( f"Accuracy score on train data: { accuracy_score(list(y_train), list(y_train_pred)) : .2f } " ) # validation metric y_pred = full_pp.predict(X_val) print( f"Accuracy score on validation data: { accuracy_score(list(y_val), list(y_pred)) : .2f } " )Pontuação de precisão nos dados do trem: 0,98 Pontuação de precisão nos dados de validação: 0,83
Assim, todo o sistema fornece 98% de precisão no conjunto de treinamento e 83% no conjunto de teste. Essa diferença prova que ocorreu overfitting (falarei sobre isso nos próximos artigos).
Bài viết liên quan:











Dịch vụ thiết kế Wesbite
