
Pré-processamento de dados em Machine Learning, exemplo concreto.
O pré-processamento de dados é uma etapa indispensável no Machline Learning porque, como você sabe, os dados são uma parte muito importante, afetando diretamente o Modelo de Treinamento. Portanto, é muito importante pré-processar os dados antes de colocá-los no modelo, ajudando a remover ou compensar os dados ausentes.
Neste artigo, ajudarei você a entender como os dados são processados antes de entrar no modelo por meio de um exemplo específico, não apenas teoria seca.
O primeiro é definitivamente um conjunto de dados para você praticar.
Mục lục
Preparar dados.
Você pode obter os dados seguindo o link abaixo. Então simplesmente são dados compostos por 10 linhas e 4 colunas, depois você vai entender porque eu escolhi os dados de 10 linhas para executar. Dados estatísticos sobre o comportamento de compra de carros de várias pessoas em vários países, com diferentes idades e salários. Há também alguns dados perdidos.
dataset = pd.read_csv("data.csv") Country Age Salary Purchased 0 France 44.0 72000.0 No 1 Spain 27.0 48000.0 Yes 2 Germany 30.0 54000.0 No 3 Spain 38.0 61000.0 No 4 Germany 40.0 NaN Yes 5 France 35.0 58000.0 Yes 6 Spain NaN 52000.0 No 7 France 48.0 79000.0 Yes 8 Germany 50.0 83000.0 No 9 France 37.0 67000.0 YesSeparação de dados
Manipulação de funções .iloc[] em pandas.core para dividir os dados, determinar quais são os recursos e o que é saída.
Exemplo: X = dataset.iloc[:3, :-1] // corta das 3 primeiras linhas e solta a última coluna.
Salário da Idade do País
0 France 44.0 72000.0 1 Spain 27.0 48000.0 2 Germany 30.0 54000.0 E para processar os dados, você precisa converter para array numpy com a função X = dataset.iloc[:3, :-1].values.
Pré-processamento de dados
Aqui estão alguns dos conceitos que usei neste artigo:
- Lidando com dados ausentes
- Padronização (Distribuição Padrão)
- Manipulando Variáveis Catógicas
- Codificação One-Hot
- Multicolinearidade
1. Lidando com dados ausentes
Em qualquer tipo de conjunto de dados no mundo existem poucos valores nulos. Isso realmente não é bom quando você deseja usar modelos como regressão ou classificação ou qualquer outro modelo. Nota: Em Python, NULL também é representado por NAN. Portanto, eles podem ser usados alternadamente .
Você pode implementar seu próprio código percorrendo os elementos de cada coluna para ver qual coluna tem o equivalente a isnull() e process.
Neste exemplo, mostrarei como usar a biblioteca Sklearn para ajudá-lo a lidar facilmente com dados ausentes. SimpleImputer é uma classe de Sklearn que suporta a manipulação de dados perdidos que são numéricos e os substitui por uma média da coluna, a frequência dos dados mais visíveis,…
from sklearn.impute import SimpleImputer #Create an instance of Class SimpleImputer: np.nan is the empty value in the dataset imputer = SimpleImputer(missing_values=np.nan, strategy='mean') #Replace missing value from numerical Col 1 'Age', Col 2 'Salary' imputer.fit(X[:, 1:3]) #transform will replace & return the new updated columns X[:, 1:3] = imputer.transform(X[:, 1:3])
2. Processamento de dados categóricos
Codificar variáveis independentes : nos ajuda a converter uma coluna contendo Strings em vetor 0 e 1
- Usando a classe ColumnTransformer do sklearn e OneHotEncoder.
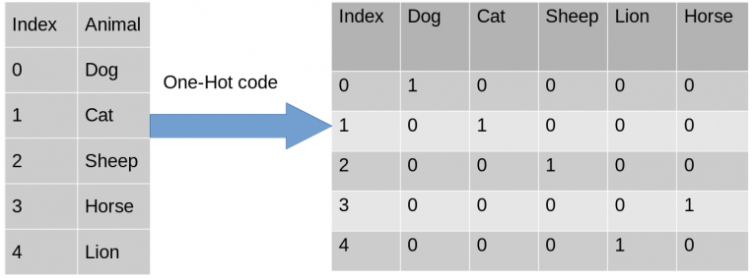
from sklearn.compose import ColumnTransformer from sklearn.preprocessing import OneHotEncoderCrie uma tupla (transformação de codificação 'encoder', instância da classe OneHotEncoder, [colunas querem transformar) e outras colunas com as quais você não deseja fazer nada, você pode usar resto="passthrough" para ignorá-las.
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [0])] , restante="passthrough" )Ajustar e transformar com entrada = instância X e ct da classe ColumnTransformer
#ajuste e transforme com entrada = X #np.array: precisa converter a saída de fit_transform() da matriz para np.array X = np.array(ct.fit_transform(X))
Após a conversão, obtemos France = [1.0,0.0,0.0] que já é um hot.
Codificar Variáveis Dependentes : Ou seja, temos que codificar os rótulos de saída para que a máquina entenda.
- Use o Label Encoder para codificar rótulos
de sklearn.preprocessing import LabelEncoder le = LabelEncoder() #output of fit_transform do Label Encoder já é um Numpy Array y = le.fit_transform(y) #y = [0 1 0 0 1 1 0 1 0 1]
Dividindo conjunto de treinamento e conjunto de teste
- Use train_test_split do Sklearn-Model Selection para fatiar dados de trem e teste.
- Use o parâmetro: test_size=… para dividir os dados do conjunto de teste em todos os dados.
- random_state = 1: Ajuda a usar o conjunto aleatório interno do python.
de sklearn.model_selection importar train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0,2, random_state = 1)
Dimensionamento de recursos
Por que o FS acontece: Quando fazemos mineração de dados, pode haver alguns recursos maiores que outros, portanto, recursos menores definitivamente serão ignorados quando fizermos o ML Model.
# Nota 1: FS não precisa ser aplicado a modelos Multi-Regression porque quando y prediz = b0 + b1*x1 + b2*x2 + … + bn*xn então (b0, b1, …, bn) ) são coeficientes para compensar a diferença, portanto, nenhum FS é necessário.
# Nota 2: Para a Codificação de Recursos Categóricos, não há necessidade de aplicar FS.

#Nota3: O FS deve ser feito após a divisão dos conjuntos de treinamento e teste. Porque se usarmos FS antes de dividir os conjuntos de treinamento e teste, os dados perderão sua exatidão.
Então, como recurso de dimensionamento .
Existem duas técnicas para fazer isso:
- Padronização: Transforma os dados para que a média seja 0 e o desvio padrão seja 1.
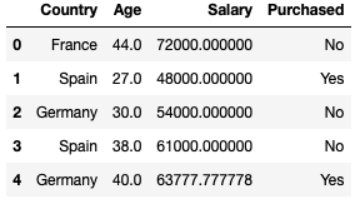
Nesses dados, você pode ver que Idade e Salário são bastante diferentes, portanto, os dados de Idade não podem ser usados no modelo. Portanto, precisamos normalizar os dados para reduzi-los a um número menor e ainda garantir a correlação dos dados.
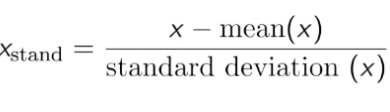
Você pode usar o StandardScaler to Std do sklearn.preprocessing para os dados.
de sklearn.preprocessing importação StandardScaler sc = StandardScaler() X_train[:,3:] = sc.fit_transform(X_train[:,3:]) #use apenas Transform para usar o MESMO escalonador como o conjunto de treinamento X_test[:,3:] = sc.transform(X_test[:,3:])
- Normalização: Faz com que o conjunto de dados flutue entre 0 e 1.
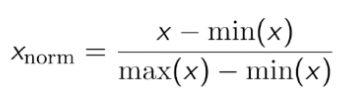
Bài viết liên quan:











Dịch vụ thiết kế Wesbite
