Recursos avançados do SQL no SQL Server 2019
Mục lục
Avisos de truncamento detalhados (avisos de truncamento detalhados)
Este é um dos novos recursos aprimorados no SQL Server 2019 para oferecer. Economiza tempo ao relatar, adicionar novos, atualizar grandes quantidades de dados.
Por exemplo:
Etapa 1 – criar banco de dados de exemplo 2017
USE [master] GO CREATE DATABASE [SampleDB2017] GO ALTER DATABASE [SampleDB2017] SET COMPATIBILITY_LEVEL = 140 GOEtapa 2 – adicione algumas tabelas de registros ao banco de dados acima
USE [SampleDB2017] GO CREATE TABLE [dbo].[tbl_Color]( [ColorID] int IDENTITY not null, [ColorName] varchar(3) NULL ) GO INSERT INTO dbo.tbl_Color (ColorName) values ('Red'), ('Blue'),('Green') GOCom versões mais antigas, o erro retornará da seguinte forma:
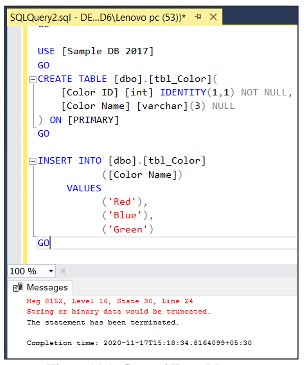
O erro ocorre quando o registro ‘Green’ é inserido na coluna com dados nvarchar(3) mesmo que o erro seja mostrado, mas se o número de registros for grande, será difícil determinar qual erro é encontrado ao inserir qual registro , na versão de sessão 2019, a mensagem de erro é corrigida e mostrada com mais detalhes, facilitando a identificação de erros.
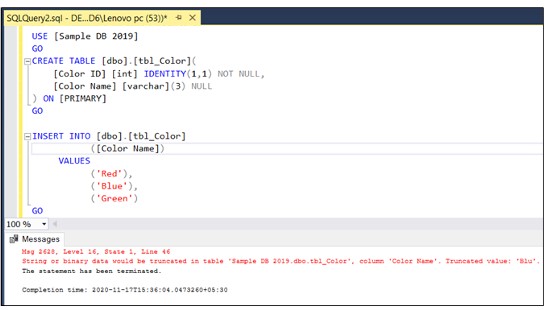
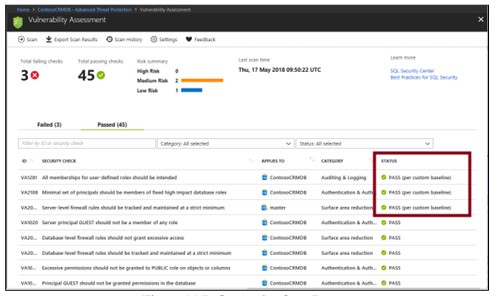
Avaliação de vulnerabilidade
É um negócio fácil de configurar que descobre, reverte ou reduz vulnerabilidades de banco de dados.
Os administradores de banco de dados podem usá-lo para desenvolver proativamente a segurança do banco de dados.
Os Ativos de Vulnerabilidade fazem parte do Azure Defensive for SQL, que é um pacote unificado para recursos avançados de segurança do SQL. Ele pode ser acessado e administrado por meio do Azure Defender para o portal SQL.
Observe a vulnerabilidade do SQL usada no Banco de Dados SQL do Azure, Instância Gerenciada do SQL do Azure, Azure Synapse Analytics (SQL Data Warehouse).
O SQL Vulnerability Asset inclui etapas para melhorar a segurança do banco de dados, pode ajudá-lo a:
- Atenda aos requisitos de conformidade com os requisitos de relatório de varredura de banco de dados
- Atenda aos padrões de privacidade de dados
- Monitore ambientes de banco de dados dinâmicos onde as alterações são difíceis de rastrear
As regras são baseadas nas melhores práticas da Microsoft e se concentram em problemas de segurança que representam o maior risco para seu banco de dados e seus dados valiosos. Os resultados da verificação incluem etapas acionáveis para resolver cada problema e fornecer cenários de reparo personalizados aplicáveis.
Você pode personalizar um relatório de vulnerabilidade para o ambiente definindo uma linha de base para:
- Configurar permissões
- Configuração do recurso
- Configurações do banco de dados
Etapas para implantar a avaliação de vulnerabilidade:
Executar verificação
Nota: o processo de digitalização é leve e seguro, leva apenas alguns segundos e somente leitura todo o processo de digitalização, não haverá alterações em seu banco de dados.
Ver relatório
Quando a verificação for concluída, o relatório será exibido automaticamente no portal do Azure
Os resultados incluem avisos sobre desvios das práticas recomendadas e instantâneos de suas configurações relacionadas à segurança, como funções e diretrizes do banco de dados e permissões.
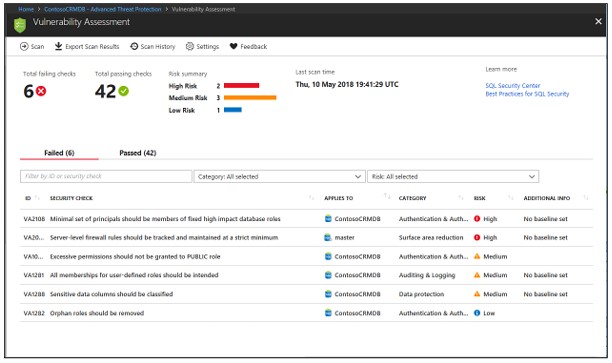
Analisar resultados e resolver problemas
Verifique os resultados novamente e identifique no relatório se há algum problema em seu ambiente.
Mergulhe em cada resultado de falha para entender o impacto da detecção e por que cada verificação de segurança falha.
Use as informações de correção acionáveis fornecidas pelo relatório para resolver o problema.
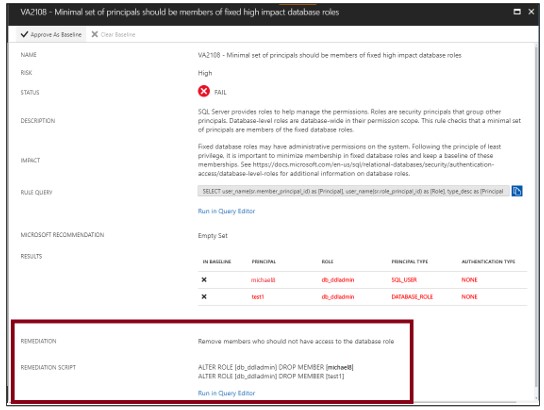
Definir linha de base
Ao revisar os resultados de sua avaliação, você pode marcar resultados específicos como uma linha de base aceitável. Os resultados que correspondem à linha de base são considerados aprovados nas varreduras subsequentes. Depois de estabelecer sua segurança de linha de base, a avaliação de vulnerabilidade relata apenas desvios da linha de base.
Os resultados que correspondem à linha de base são considerados aprovados nas varreduras subsequentes. Depois de estabelecer a data da linha de base de segurança, a avaliação de vulnerabilidade relata apenas os desvios da linha de base.
Execute uma nova verificação para ver seus relatórios de rastreamento personalizados.
Depois de instalar as linhas de base de regra, execute uma verificação para ver relatórios personalizados, a avaliação de vulnerabilidade relatará apenas problemas de segurança que se desviam da linha de base aprovada.
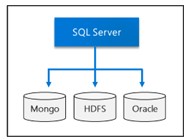
Clusters de Big Data
No SQL Server 2019 Big Data Cluster permite implantar clusters escaláveis do SQL Server, Spark e Hadoop Distributed File System (HDFS)…
O Big Data Cluster é usado principalmente para:
- Implante clusters de contêiner do SQL Server, Spark e HDFS escaláveis em execução no Kubernetes.
- Leia, escreva, processe big data de T-SQL ou Spark SQL.
- Combine e analise facilmente dados relacionais de grande valor com big data de grande valor.
- Consultar uma fonte de dados externa.
- Armazene big data em HDFS gerenciado pelo SQL Server.
- Consulte dados de várias fontes de dados externas por meio do cluster.
- Use dados para IA, ML ou outras tarefas analíticas.
- Implante e execute aplicativos no Big Data Cluster, virtualize dados com o PolyBase.
- Consulte dados de fontes de dados externas do SQL Server, Oracle Teradata, MongoDB, ODBC com tabelas externas.
- Forneça alta disponibilidade para as principais instâncias do SQL Server e todos os bancos de dados usando a família de tecnologia Always On Availability.
Virtualização de dados (virtualização de dados)
Os clusters de Big Data do SQL Server podem consultar fontes de dados externas sem mover ou copiar dados.
Data Lake
O Data Lake é um repositório de contêineres que contém grandes quantidades de dados brutos em seu formato nativo.
É um pool de armazenamento HDFS escalável.
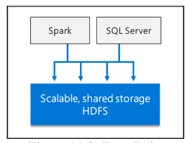
Data mart de expansão horizontal
Fornece computação e armazenamento em escala para melhorar o desempenho de qualquer análise de dados.
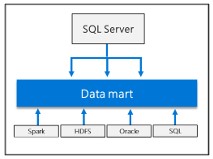
Integrando IA e Machine Learning
Permite a execução de tarefas de IA e aprendizado de máquina com dados armazenados em pools de armazenamento HDSF e pools de dados.
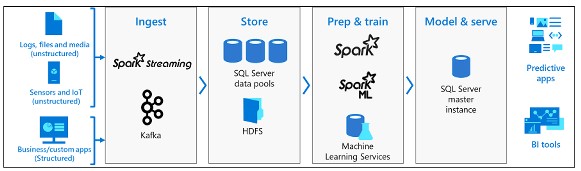
O cluster de big data do SQL Server é um cluster de contêineres Linux hospedados pela plataforma Kubernetes.
O termo Kubernetes
Kubernetes é uma orquestração de contêineres de código aberto que pode dimensionar implantações de contêiner sob demanda. Alguns termos importantes do Kubernetes:
| Termos | Descrever |
| Conjunto | O cluster Kubernetes é uma coleção de máquinas, entendidas como nós, um nó controla o cluster e o designa como o nó mestre, os nós restantes são nós do trabalhador. O mestre do Kubernetes é responsável por distribuir o trabalho entre os trabalhadores e monitorar a integridade do cluster. |
| Nó | Um nó que executa o aplicativo está contido no contêiner. Pode ser uma máquina física ou uma máquina virtual. Um cluster Kubernetes pode conter nós de máquina física e virtual. |
| Cápsula | Os pods são a implementação atômica do Kubernetes. Um bucket é um agrupamento lógico de um ou mais contêineres e recursos relacionados necessários |
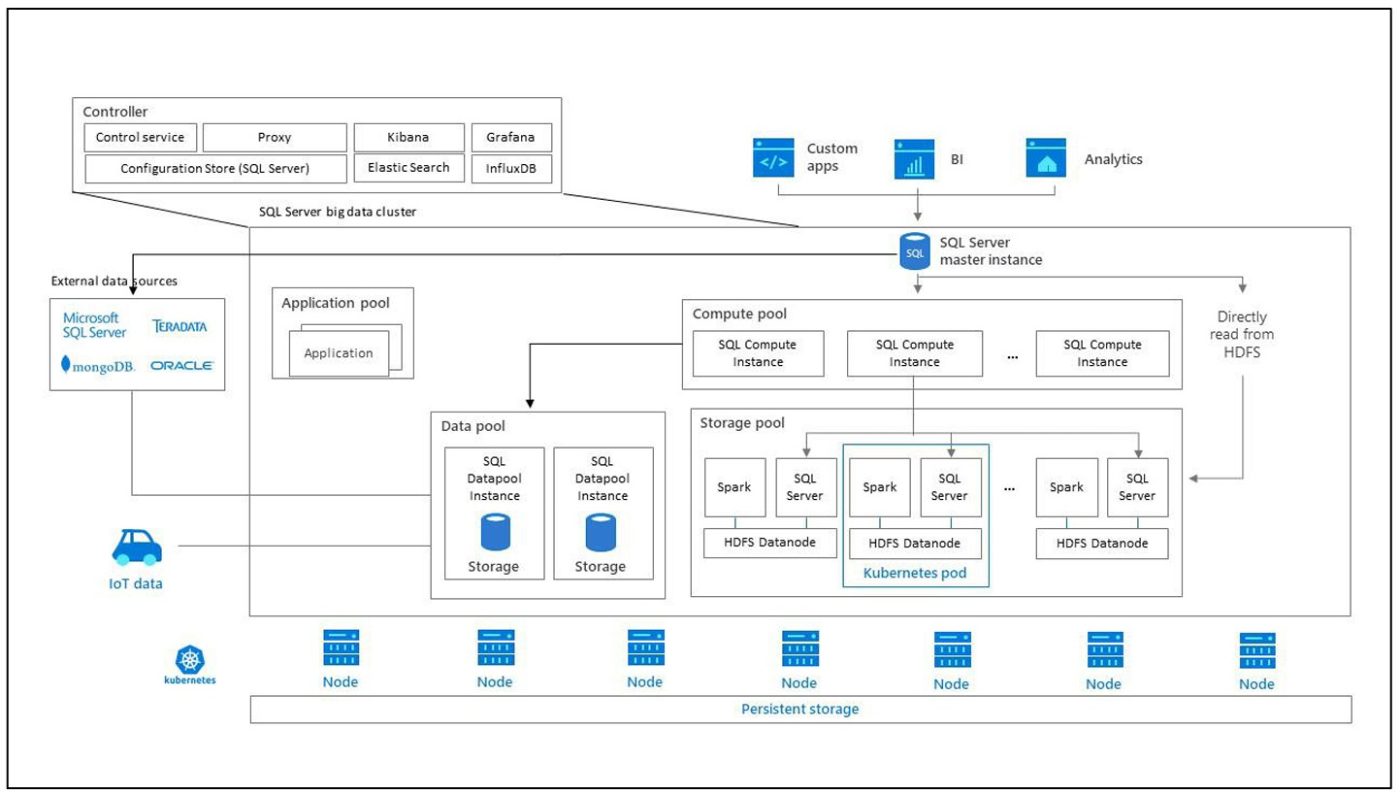
Controlador
O controlador fornece administração e segurança para o cluster. Inclui serviços de controle, configuração e camada de cluster, como Kibana, Grafana e Elastic Search.
Conjunto de computação
O pool de computação fornece recursos de computação para o cluster. Inclui nós do SQL Server executados em pods do Linux. Os pods em um pool computado são divididos em instâncias SQL Compute para operações de processamento específicas.
Conjunto de dados
O conjunto de dados é usado para persistência de dados e armazenamento em cache. O pool de dados contém um ou mais pods executando o SQL Server no Linux. Ele é usado para obter dados de consultas SQL ou Spark. Os data marts de cluster de big data do SQL Server mantêm a persistência no pool de dados.
Conjunto de armazenamento
O pool de armazenamento inclui pods de pool de armazenamento, incluindo SQL Server no Linux, Spark e HDFS. Todos os nós de armazenamento no cluster bigdata do SQL Server são membros do cluster HDFS.
Bài viết liên quan:

Dịch vụ thiết kế Wesbite

