
Use a validação K-fold para avaliar o modelo com mais eficiência.
O modelo de treinamento não depende apenas do modelo que você usa, mas também envolve muitas outras coisas, incluindo a quantidade de dados. Um conjunto de dados modesto inevitavelmente levará a uma avaliação ineficiente do modelo. Portanto, a validação cruzada K-fold é um truque muito legal para nos ajudar a lidar com isso.
Mục lục
E se avaliarmos o modelo com poucos dados?
Certamente todos estão familiarizados com como dividir dados de trem, validação e teste, certo?
Por enquanto, você só precisa se preocupar com o conjunto de treinamento e o conjunto de val, e o conjunto de teste nos permitirá avaliar o modelo após a conclusão do treinamento para ver como o modelo lidará com os dados na prática.
Normalmente você verá que muitas vezes dividimos train / val na proporção de 80/20 (80% dos dados do trem, 20% dos dados de teste). Essa divisão é muito boa quando nossos dados são grandes. Quanto aos dados pequenos, isso definitivamente fará com que seu modelo tenha um desempenho ruim. Como alguns dos dados úteis para o processo de treinamento foram lançados por nós para validação e teste, o modelo não pode aprender com esses dados. Sem mencionar que se nossos dados não são garantidos como aleatórios, alguns rótulos estão presentes na validação e no teste, mas não no conjunto de treinamento. E, claro, avaliar o modelo com base nesse resultado não é bom. É como se ele não estudasse matemática, mas o fizesse aprender aprendizado de máquina.
Então precisamos da validação cruzada K-Fold.
O que é a validação cruzada K?
O K-Flod CV nos ajudará a avaliar um modelo de forma mais completa e precisa quando nosso conjunto de treinamento não for grande.
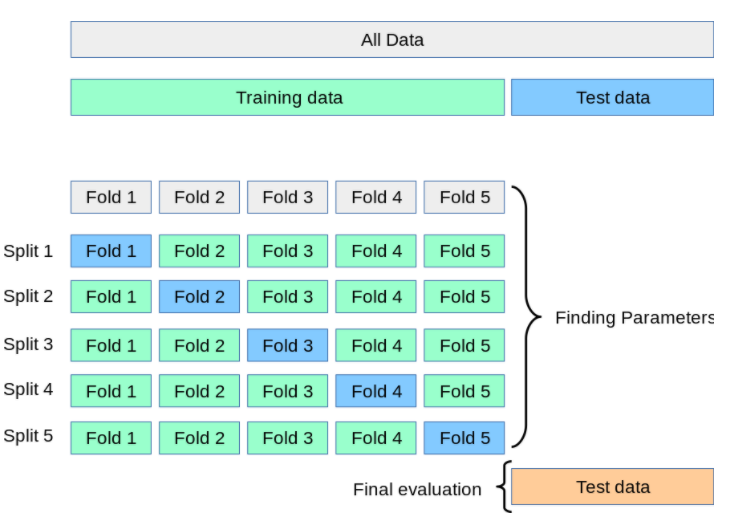
A parte dos dados de treinamento será dividida em K partes (K é um número inteiro que geralmente é muito difícil de escolher 10). Em seguida, treine o modelo K vezes, cada vez que o trem escolherá 1 parte como dados de validação e a subparte K-1 será o conjunto de treinamento. O resultado final será a média dos resultados da avaliação de K tempos de treino. É também por isso que esta avaliação é mais objetiva.
Depois que a avaliação for concluída e você encontrar a Precisão em um nível "aceitável", prossiga para a previsão apenas com o conjunto de dados de teste.
Pratique com Keras
Ok teoria básica feita. Agora pra praticar! Sempre usamos o conjunto de dados CIFAR10 em keras para praticar.
Importar bibliotecas.
from tensorflow.keras.datasets
import cifar10
from tensorflow.keras.models
import Sequential from tensorflow.keras.layers
import Dense, Flatten, Conv2D, MaxPooling2D from sklearn.model_selection
import KFold import numpy as np
Escreva uma função para carregar dados:
def load_data():
# Load dữ liệu CIFAR đã được tích hợp sẵn trong Keras
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# Chuẩn hoá dữ liệu
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_test = X_test / 255
X_train = X_train / 255 # Do CIFAR đã chia sẵn train và test nên ta nối lại để chia K-Fold
X = np.concatenate((X_train, X_test), axis=0)
y = np.concatenate((y_train, y_test), axis=0)
return X, y
Construir modelos em Keras
def get_model():
model = Sequential()
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(no_classes, activation='softmax')) # Compile model
model.compile(loss="sparse_categorical_crossentropy", optimizer="Adam", metrics=['accuracy'])
return model
Também usamos a biblioteca KFold do Sklearn para compartilhar
kfold = KFold(n_splits=num_folds, shuffle= True )
# K-fold Cross Validation model evaluation
fold_idx = 1
for train_ids, val_ids in kfold.split(X, y):
model = get_model()
print ("Bắt đầu train Fold ", fold_idx)
# Train model
model.fit(X[train_ids], y[train_ids], batch_size=batch_size, epochs=no_epochs, verbose=1) # Test và in kết quả
scores = model.evaluate(X[val_ids], y[val_ids], verbose=0) print ("Đã train xong Fold ", fold_idx) # Thêm thông tin
accuracy và loss vào list accuracy_list.append(scores[1] * 100) loss_list.append(scores[0]) # Sang Fold tiếp theo
fold_idx = fold_idx + 1
A ideia é que vamos usar o KFold para obter o conjunto de índices de trem e o conjunto de índices de val em cada dobra, e então extrair os elementos de acordo com esse conjunto de índices em train, val para ser mais adequado. Os resultados de precisão e perda serão salvos na lista para exibir a média.
resumo
Em vez de avaliar o modelo face a face com o conjunto train e o conjunto val, conseguimos avaliar o modelo de forma mais eficiente com o K-Fold CV. Além do K-Fold CV, você pode tentar o Stratified K-Fold, isso é melhor porque é uma extensão do K-Fold CV.
Bài viết liên quan:











Dịch vụ thiết kế Wesbite
