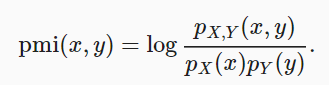
Feature selection method in Machine Learning.
In fact, not all data is clear, the features are useful for the model. For example, when we want to predict the price of a house, it doesn't matter whether the landlord is a boy or a girl. Therefore, it is quite important to choose features that are useful to the model, helping to reduce the number of input data dimensions.
Basically, we will use probability to calculate the relationship between each feature and the target field to be predicted. But the idea is that, using any formula or measure to determine if that feature is not good is still a great wisdom. In this article, you and I will learn through some formulas and calculations!
Mục lục
Feature selection method
Feature selection algorithms can be divided into three categories: filter methods, wrapper methods, and embedded methods.
Filter
This guy has the following characteristics:
- Depends on the characteristics of the data
- Will give lower performance than wrapper methods or embedded methods.
- Methods: Variance , Correlation , Univariate selection , Multivariate selection .
About Constant, quasi-constant, duplicated features.
Constant features : display only one value for all observations in the dataset.
The simplest method to handle constant features. We will set a threshold (threshold) for the variance, features that do not meet that threshold will be discarded. (Can use sklearn to process)
from sklearn.feature_selection import VarianceThreshold sel = VarianceThreshold(threshold=0) # fit finds the features with zero variance. sel.fit(X_train) # get_support() method returns which features are retained. retained_features = sel.get_support()
It will return a bool sequence, we just need to look at it to know which features do not satisfy the condition.
Quasi-constant features : Similar to the constant features above, it's just that we can adjust the threshold to make the condition more stringent (for example, threshold = 0.01, the feature will be dropped when it has 99% value. alike).
Duplicated features : Are similar features, for example, one original feature and another feature is the label encoder of the original feature, then those two features are equivalent, we can drop one feature. Or multiple identical rows.
Method:
- For small dataset: In pandas there is a function to evaluate if a dataframe contains duplicated rows. As for checking columns, we still use the duplicated() function, just transpose the matrix.
- With big dataset: If using transpose with large data is definitely very memory consuming and not feasible. So we can use loop to find duplicated columns or use numpy library.
for_, idx = np.unique(df.to_numpy(), axis=1, return_index=True) df_uniq = df.iloc[:, np.sort(idx)]
Correlation
Using the correlation between two or more variables is also a good way to remove features with low correlation. The removal of highly correlated features helps the linear model work better, avoiding bias between features.
- We can test the feature with a low correlation target we can drop the feature.
- Or check the correlation between feature and feature if two features have high correlation with each other, maybe those two features have the same information and we can drop 1 feature to reduce the dimensionality of the input data.
How to determine correlation coefficient .
Pearson's correlation coefficient
sum((x1 -x1.mean) * (x2 - x2.mean) * (xn - xn.mean)) / var(x1) * var(x2) * var(xn)
- Pearson's coefficient has a value in the range [-1,1]
- The idea is to calculate the correlation between features, if 2 features have a correlation greater than the threshold that I set, I will drop one of those 2 features.
corrmat = X_train.corr()
# plot
fig, ax = plt.subplots()
fig.set_size_inches(11,11)
sns.heatmap(corrmat)
def correlation(df, threshold):
col_corr = set()
corrmat = df.corr()
for i in range(len(corrmat.columns)):
for j in range(i):
# interested in abs coefficient values
if abs(corrmat.iloc[i, j]) > threshold:
col_corr.add(corrmat.columns[i])
return col_corr
corr_feats = correlation(X_train, 0.8)
X_train.drop(labels=corr_feats, axis=1, inplace=True)Statistical measures
There are a few methods and criteria for selecting features according to statistical methods as follows:
- Information Gain
- Univariate ROC-AUC/RMSE
For each of the above methods, there will be 2 steps as follows:
- Evaluate features according to a certain criterion: Each feature will have an independent evaluation of other features when considering its relationship with the target.
- Selecting high ranking fetures: Can we apply classification or regression models to evaluate a high ranking feature?. And of course, how much to know if the ranking is high or low depends on you.
A few caveats: we can apply duplicated or corelated features before doing this step. And this method also has a big disadvantage that there can be 2 features combined together, it will affect the target and if we only apply this method to each feature in terms of tagert, it can lead to mistakes. Therefore, it is necessary to apply more methods to evaluate between features and targets.
Mutual information (information Gain)
This method compares the probability that x and y occur simultaneously across the distribution and combines with the case when the two distributions are independent.
mutual information = sum{i,y} P(xi, yj) * log(P(xi,yj)/P(xi)*P(yj))If x and y are independent then mutual information will be 0.
We can use python's library to select features:
- Use
sklearn.feature_selection.mutual_info_regressionon the regression model. - And
mutual_info_classifto select with model classification.
Perform mutual information calculation between variables and targets. Returns mutual information for each feature. The smaller the value, the lower the information about that feature with the target. (Preprocessing is recommended before applying this method).
Univariate ROC-AUC/RMSE
The idea is to calculate the ROC-AUC of each feature and then use the machine learning model to predict the target. Here we can use decision tree and evaluate according to ROC-AUC or RMSE. From there, we will select features with high metrics.
# use bnp-paribas dataset roc_vals = [] for feat in X_train.columns: clf = DecisionTreeClassifier() clf.fit(X_train[feat].fillna(0).to_frame(), y_train) y_scored = clf.predict_proba(X_test[feat].fillna(0).to_frame()) roc_vals.append(roc_auc_score(y_test, y_scored[:,1]))
rocvals = pd.Series(roc_vals) rocvals.index = X_train.columns rocvals.sort_values(ascending=False) # number of features shows a roc-auc value higher than random. len(rocvals[rocvals>0.5])
Summary:
Through this study, you and I have learned some methods of feature selection, reducing the number of input dimensions to make training model easier.