Pipeline in machine learning
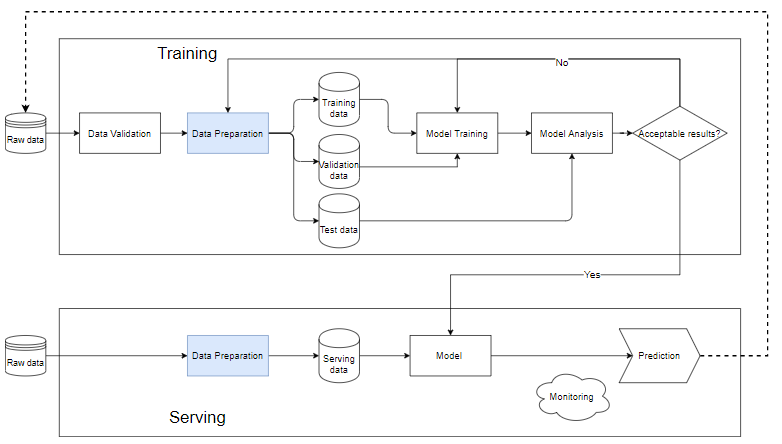
Pipeline in ML is a way to automate the workflow of creating a machine learning model. Almost every Machine Learning system has components like the diagram below, it is a machine learning pipeline.
Mục lục
What is a pipeline in machine learning?
Training block
- Data validation: Is the step of testing data, determining whether the newly added data is satisfied with the data in the database. Because of the fact new data will always be added to execute train.
- After the raw data is cleaned to the Data Prepration step, it is then split into a training data set, a training data set and a validation data set. test data to determine the quality of the model after the training process.
- The training data is put into the "model training" block to train the model.
- After training, we perform the analysis in the "model analysis" block to analyze the quality. Check if the metrics on the test set are good, the predicted results and the actual results are equivalent, the prediction speed,…
- When the data is passed through the model analysis block, the model will be used to run the actual data in the "Serving" step. Otherwise we need to review the model or filter the data.
Serving . Block
- When the model is still stub, we should use a small dataset, run the test, if the quality is acceptable, we can do it on the whole data.
- Data Preparation helps to clean and create data that will have to be the same as the model in the training block.
- Each different problem requires a different monitoring and alerting system. Usually, regardless of the input data, the model will still produce a predictable, possibly random, outcome. If these results are not monitored and alarmed carefully, leading to sudden changes in model quality and user reactions, the company's reputation and revenue will be affected. serious.
Why build pipelines?
- Machine learning systems often consist of a lot of small components such as data processing, model training, model evaluation, prediction with new data, etc. Without building a complete pipeline with each component separate Obviously, there will be a lot of problems. Separating your system step by step and putting it back together in a pipeline makes it easier to find errors when training the model.
- Building a pipeline also helps us work together better as a team. If there is a large group, we can divide it into small groups: one group specializes in data cleaning, one group specializes in creating features, another group builds and trains the model, and another group focuses on evaluation. and monitor the activity of the model. These blocks of work, if separated and specialized, will help teams drill down to improve the quality of each block without worrying about breaking other team's code.
Simple example
Here I will introduce a complete pipeline, I will not go into each command line, but want to use this example to give you an overview of a pipeline. You can see the full code here
The first step is to import the necessary libraries.
from pathlib import Path import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.ensemble import RandomForestClassifier from sklearn.impute import KNNImputer, SimpleImputer from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.pipeline import Pipeline from sklearn.preprocessing import OneHotEncoder, RobustScalerLoad data
titanic_path = ( "https://github.com/CongSon01/titanic_pipeline/" ) df_train_full = pd.read_csv(titanic_path + "train.csv") df_test = pd.read_csv(titanic_path + "test.csv")
Drop the missing data, does not bring efficiency to the model.
df_train_full.drop(columns=["Cabin"]) df_test.drop(columns=["Cabin"]);Before going into the feature building step, we need to split the training/test data. Here, the random 10% of the original labeled data is extracted as validation data , the remaining 90% is kept as training data . The Survived column is the label column that is split into a separate variable containing the label:
df_train, df_val = train_test_split(df_train_full, test_size=0.1) X_train = df_train.copy() y_train = X_train.pop("Survived") X_val = df_val.copy() y_val = X_val.pop("Survived")Processing features with categorical or numeric data types will have different processing methods. We first deal with categorical data.
cat_cols = ["Embarked", "Sex", "Pclass"] cat_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="most_frequent")), ("onehot", OneHotEncoder(handle_unknown="ignore", sparse= False )), ] )Next we apply num_transformer to two numeric features:
num_cols = ["Age", "Fare"] num_transformer = Pipeline( steps=[("imputer", KNNImputer(n_neighbors=5)), ("scaler", RobustScaler())] )Combining two processors we get a complete processor. The scikit-learn ColumnTransformer class helps to combine transformers:
preprocessor = ColumnTransformer( transformers=[ ("num", num_transformer, num_cols), ("cat", cat_transformer, cat_cols), ] )Finally, we combine the preprocessor-specific processor with a simple classifier that is often used with tabular data, RandomForestClassifier, to get a full_pp pipeline that includes both data processing and models. Full_pp is fitted to the training data (X_train, y_train) then used to apply to the test data.
# Full training pipeline full_pp = Pipeline( steps=[("preprocessor", preprocessor), ("classifier", RandomForestClassifier())] ) # training full_pp.fit(X_train, y_train) # training metric y_train_pred = full_pp.predict(X_train) print( f"Accuracy score on train data: { accuracy_score(list(y_train), list(y_train_pred)) : .2f } " ) # validation metric y_pred = full_pp.predict(X_val) print( f"Accuracy score on validation data: { accuracy_score(list(y_val), list(y_pred)) : .2f } " )Accuracy score on train data: 0.98 Accuracy score on validation data: 0.83
Thus, the whole system gives 98% accuracy on the training set and 83% on the test set. This difference proves that overfitting has occurred (I will talk about it in the following articles).