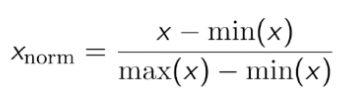Data preprocessing in Machine Learning, concrete example.
Data preprocessing is an indispensable step in Machline Learning because as you know, data is a very important part, directly affecting the Training Model. Therefore, it is very important to preprocess the data before putting it into the model, helping to remove or compensate for the missing data.
In this article, I will help you understand how the data is processed before entering the model through a specific example, not just dry theory.
The first is definitely a data set for you to practice.
Mục lục
Prepare data.
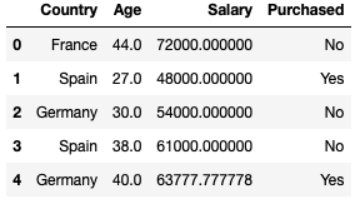
You can get the data by following the link below. Then simply this is data consisting of 10 rows and 4 columns, later you will understand why I chose the data of 10 rows to execute. Statistical data on car buying behavior of a number of people across countries, with different ages and salaries. There are also some lost data.
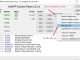
dataset = pd.read_csv("data.csv") Country Age Salary Purchased 0 France 44.0 72000.0 No 1 Spain 27.0 48000.0 Yes 2 Germany 30.0 54000.0 No 3 Spain 38.0 61000.0 No 4 Germany 40.0 NaN Yes 5 France 35.0 58000.0 Yes 6 Spain NaN 52000.0 No 7 France 48.0 79000.0 Yes 8 Germany 50.0 83000.0 No 9 France 37.0 67000.0 YesData Separation
Function handling .iloc[] in pandas.core to slice the data, determine what are features and what is output.
Example: X = dataset.iloc[:3, :-1] // cut from the top 3 rows and drop the last column.
Country Age Salary
0 France 44.0 72000.0 1 Spain 27.0 48000.0 2 Germany 30.0 54000.0 And to process data, you have to convert to numpy array with function X = dataset.iloc[:3, :-1].values.
Data preprocessing
Here are some of the concepts I used in this article:
- Handling Missing Data
- Standardization (Standard Distribution)
- Handling Categorical Variables
- One-hot Encoding
- Multicollinearity
1. Handling Missing Data
On any kind of dataset in the world there are few null values. That's really not good when you want to use models like regression or classification or any other model. Note: In Python, NULL is also represented by NAN. Therefore they can be used interchangeably .
You can implement your own code by looping through the elements of each column to see which column has the equivalent of isnull() and process.
In this example I will show you how to use Sklearn library to help you easily deal with missing data. SimpleImputer is a class of Sklearn that supports handling missing data that is numeric and replaces them with an average of the column, the frequency of the most visible data,…
from sklearn.impute import SimpleImputer #Create an instance of Class SimpleImputer: np.nan is the empty value in the dataset imputer = SimpleImputer(missing_values=np.nan, strategy='mean') #Replace missing value from numerical Col 1 'Age', Col 2 'Salary' imputer.fit(X[:, 1:3]) #transform will replace & return the new updated columns X[:, 1:3] = imputer.transform(X[:, 1:3])
2. Categorical data processing
Encode Independent Variables : Helps us convert a column containing Strings into vector 0 & 1
- Using sklearn's ColumnTransformer class and OneHotEncoder.
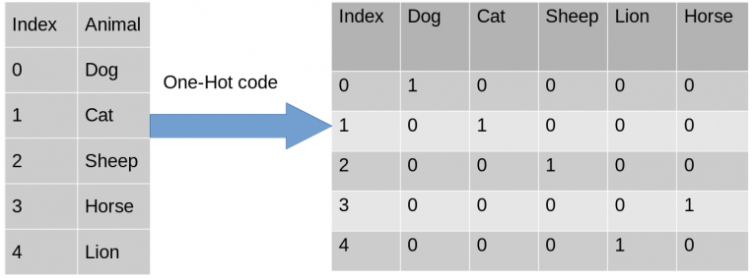
from sklearn.compose import ColumnTransformer from sklearn.preprocessing import OneHotEncoderCreate a tuple ('encoder' encoding transformation, instance of class OneHotEncoder, [cols want to transform) and other cols you don't want to do anything with, you can use remainder="passthrough" to skip them.
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [0])] , remainder="passthrough" )Fit and transform with input = X and ct instance of class ColumnTransformer
#fit and transform with input = X #np.array: need to convert output of fit_transform() from matrix to np.array X = np.array(ct.fit_transform(X))
After converting we get France = [1.0,0.0,0.0] which is already one-hot.
Encode Dependent Variables : That is, we have to encode the output labels for the machine to understand.
- Use Label Encoder to encode labels
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() #output of fit_transform of Label Encoder is already a Numpy Array y = le.fit_transform(y) #y = [0 1 0 0 1 1 0 1 0 1]
Splitting Training set and Test set
- Use Sklearn-Model Selection's train_test_split to slice train and test data.
- Use parameter: test_size=… to split test set data over all data.
- random_state = 1: Helps to use python's built-in random set.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 1)
Feature Scaling
Why does FS happen: When we do data mining, there may be some features that are larger than others so smaller features will definitely be ignored when we do ML Model.
# Note 1: FS does not need to be applied to Multi-Regression models because when y predicts = b0 + b1*x1 + b2*x2 + … + bn*xn then (b0, b1, …, bn) ) are coefficients to compensate for the difference so no FS is needed.
# Note 2: For the Categorical Features Encoding, there is no need to apply FS.

#Note3: FS must be done after splitting Training and Test sets. Because if we use FS before splitting training & test sets, the data will lose its correctness.
So how to feature scaling .
There are two techniques to do this:
- Standardization: Transforms the data so that the mean is 0 and the standard deviation is 1.
On this data you can see that Age and Salary are quite different, so Age data may not be used in the model. Therefore, we need to normalize the data to reduce them to a smaller number and still ensure the correlation of the data.
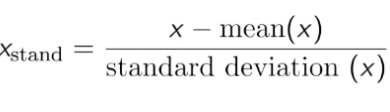
You can use sklearn.preprocessing's StandardScaler to Std for the data.
from sklearn.preprocessing import StandardScaler sc = StandardScaler() X_train[:,3:] = sc.fit_transform(X_train[:,3:]) #only use Transform to use the SAME scaler as the Training Set X_test[:,3:] = sc.transform(X_test[:,3:])
- Normalisation: Causes the data set to fluctuate between 0 and 1.