Introduction to Machine Learning
Mục lục
Why learn Machine Learning?
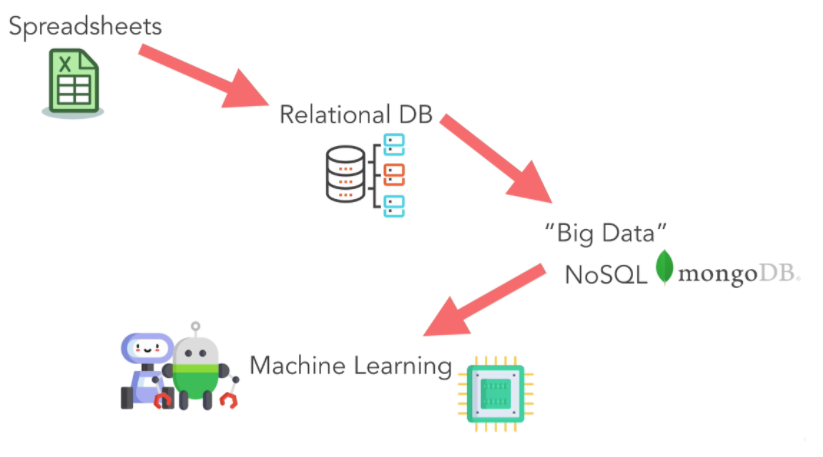
- Spread Sheets (Excel, CSV): As a place to store the necessary business data, it is one of the most useful tools available today. Helps us analyze and represent the data a business needs.
- Relational DB (MySQL): Is a better data storage place than Spread Sheets and is executed through query statements, from which business can use statements to search and process data.
- Big Data (NoSQL): FB, Amazon, Shopee, … due to large user data, it is called big data and here the data is not strictly organized, so it is necessary to use machine learning instead of children. decision makers.
Several areas are related to machine learning.
Artificial Intelligence AI?
Artificial intelligence or artificial intelligence (AI) is a branch of computer science. An intelligence created by humans with the goal of helping computers to automate intelligent behaviors like humans.
Machine Learning
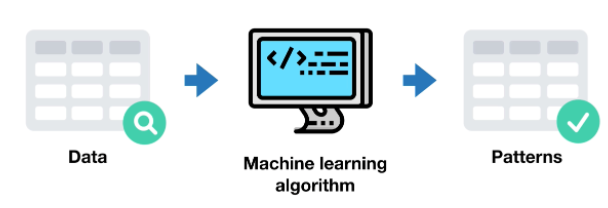
As a sub-branch of AI, machine learning uses algorithms ( Algorithms ) or computer programs to learn different data and then uses the algorithm and what it learned earlier to make a prediction. guess or reclassify based on similar data.
Example: Categorization or product analysis.
Difference between Machine Learning and Normal Algorithms
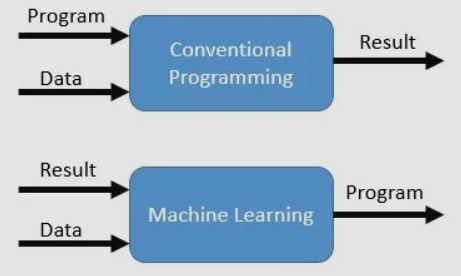
- Normal Algorithm: use input + algorithm -> result (output).
- Machine Algorithm: Start with input and output -> from there determine the relationship between I/P and O/P.
Some problems in machine learning

Supervised: Data containing labels
eg: Like dog and cat data,…
Unsupervised: Unlabeled data like an excel file without column headers.
- Clustering: Helps us to cluster groups. eg: Clustering customers according to customer preferences.
- Association Rule Learning: Associating multiple attributes to predict customer behavior. eg What to buy in the future.
Reinforcement: Teach the Machine to try and fail so there will be rewards for it to improve next time. eg: applied in alpha go – world famous chess machine.
Deep Learning
Deep Learning is a subset of Machine Learning, capable of being different in some important respects from traditional shallow Machine Learning, allowing computers to solve a wide range of unsolvable complex problems.
Data Science
Data Analysis: Analyze data from there to make the necessary reports.
Data Science: Run tests on data sets to find out useful information about that data.
How Machine Learning Works

Step 1 : Identify the problem – convert the customer's sentence to the problem of machine learning.
You must determine what your problem needs to be solved?
- Supervised
- Unsupervised
- Classificaiton
- Regression
Step 2 : Data: What is the existing data type?
Step 3 : Evaluation
- Determine when the algorithm is correct.
- Indicators that need attention help us evaluate the project.
Step 4: Data features (features)
- What features does your data have and what features do you need to use to build the model? From there turn the features into patterns.
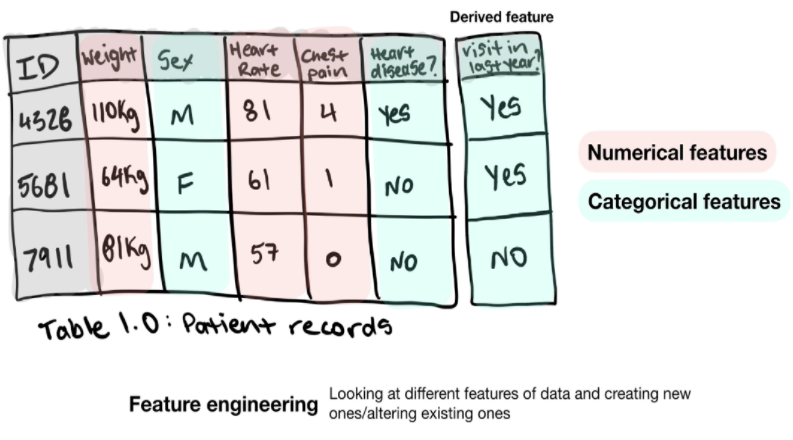
- There are 3 main types of features:
- Categorical features: Can be gender, or yes/no.
- Continuous (or numerical) features: A numeric value such as the message span or the number of times an action is executed.
- Derived features (the type of features you create from data): Often called feature engineering. For example, when you get velocity and time from your initial data, you can create a Derived feature that is the distance traveled.
Step 5 : Models
These days, there are many libraries to help you solve problems, it is important to determine when to use which model?
- Supervised Learning: (Input & Output) Data + Label → Classifications, Regressions Model,…
- Un-Supervised Learning: Only Input) Data → Clustering,…
- Reinforment Learning: Completing and Rewarding: Must find a way to update ML scores.
Step 6 : Test, evaluate.
Please review the model and use algorithmic evaluation methods to see if your model is correct, and how accurate is it?
| Classification | Regression | Recommendation |
|---|---|---|
| Accuracy | Mean Absolute Error (MAE) | Precision at KY |
| Precision | Mean Squared Error (MSE) | |
| Recall | Root Mean Squared Error (RMSE) |
Some common problems in machine learning processing.

Overfitting
When the training data set is good and the test data is good, your general model is not good.
Solution : Hai try to use simpler model and make sure your test data has the same type as training data.
Underfitting
Training data performance is poor so your data was not properly learned in the first place. Leads to underfitting.
Solution: Try dividing data training and data testing again and try adjusting the parameters of the data.