Use K-fold validation to evaluate the model more effectively.
The training model not only depends on the model you use, it also involves a lot of other things including the amount of data. A modest data set will inevitably lead to an inefficient model evaluation. So K-fold cross validation is a pretty cool trick to help us handle that.
Mục lục
What if we evaluate the model with little data?
Surely everyone is familiar with how to divide train, valdiation and test data right?
For now, you only need to care about the Training set and the val set, and the test set will let us evaluate the model after the training is complete to see how the model will handle the data in practice.
Usually you will see that we often divide train / val in the ratio of 80/20 (80% of train data, 20% of test data). Such division is quite good when our data is large. As for small data, it will definitely make your model perform poorly. Since some of the data useful for the training process has been thrown by us for validation and testing, the model cannot learn from that data. Not to mention if our data is not guaranteed to be random then some labels are present in validation and test but not in training set. And of course, evaluating the model based on that result is not good. It's like he didn't study math but made him learn machine learning.
Then we need K-Fold Cross Validation.
What is K Cross Validation?
K-Flod CV will help us evaluate a model more fully and accurately when our training set is not large.
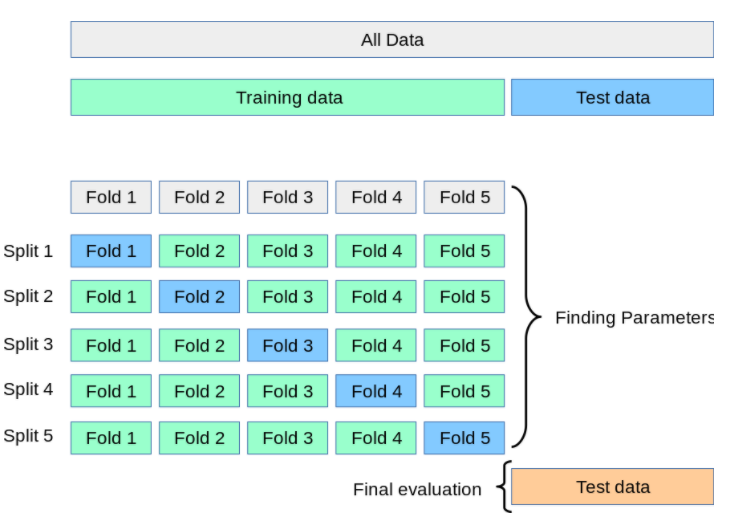
The training data part will be divided into K parts (K is an integer that is often too difficult to choose 10). Then train the model K times, each time train will choose 1 part as validation data and K-1 subpart will be the training set. The final result will be the average of the evaluation results of K training times. That is also why this assessment is more objective.
After the evaluation is complete and you find Accuracy at an "acceptable" level, you proceed to predict with the test data set only.
Practice with Keras
Ok basic theory done. Now to practice! We always use the CIFAR10 dataset in keras for practice.
Import libraries.
from tensorflow.keras.datasets
import cifar10
from tensorflow.keras.models
import Sequential from tensorflow.keras.layers
import Dense, Flatten, Conv2D, MaxPooling2D from sklearn.model_selection
import KFold import numpy as np
Write a function to load data:
def load_data():
# Load dữ liệu CIFAR đã được tích hợp sẵn trong Keras
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# Chuẩn hoá dữ liệu
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_test = X_test / 255
X_train = X_train / 255 # Do CIFAR đã chia sẵn train và test nên ta nối lại để chia K-Fold
X = np.concatenate((X_train, X_test), axis=0)
y = np.concatenate((y_train, y_test), axis=0)
return X, y
Build models in Keras
def get_model():
model = Sequential()
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(no_classes, activation='softmax')) # Compile model
model.compile(loss="sparse_categorical_crossentropy", optimizer="Adam", metrics=['accuracy'])
return model
We also use Sklearn's KFold library to share
kfold = KFold(n_splits=num_folds, shuffle= True )
# K-fold Cross Validation model evaluation
fold_idx = 1
for train_ids, val_ids in kfold.split(X, y):
model = get_model()
print ("Bắt đầu train Fold ", fold_idx)
# Train model
model.fit(X[train_ids], y[train_ids], batch_size=batch_size, epochs=no_epochs, verbose=1) # Test và in kết quả
scores = model.evaluate(X[val_ids], y[val_ids], verbose=0) print ("Đã train xong Fold ", fold_idx) # Thêm thông tin
accuracy và loss vào list accuracy_list.append(scores[1] * 100) loss_list.append(scores[0]) # Sang Fold tiếp theo
fold_idx = fold_idx + 1
The idea is that we will use KFold to get the train index set and val index set at each fold, and then extract the elements according to that index set into train, val to be more suitable. Accuracy and loss results will be saved in the list to display the average.
summary
Instead of evaluating the model face-to-face with the train set and val set, we were able to evaluate the model more efficiently with the K-Fold CV. Besides K-Fold CV you can try Stratified K-Fold, this is better because it is an extension of K-Fold CV.