










Giới thiệu
hocvietcode.com là website chia sẻ và cập nhật tin tức công nghệ, chia sẻ kiến thức, kỹ năng. Chúng tôi rất cảm ơn và mong muốn nhận được nhiều phản hồi để có thể phục vụ quý bạn đọc tốt hơn !
Liên hệ quảng cáo: trienkhaiweb@gmail.com
Recentemente, fiz um pequeno pequeno projeto usando LSTMs, mas ler documentos vietnamitas para entender profundamente sobre a fala não é muito claro, existe este artigo https://dominhhai.github.io/vi/2017/10/what-is-lstm / é traduzido de um site estrangeiro, o que eu acho muito bom. Então, através do projeto que fiz, gostaria de estar aqui para compartilhar algumas coisas para todos e para mim no futuro quando não o usar por muito tempo e depois ler novamente para pensar.
Mục lục
Antes de explicar sobre as LSTMs, acho que devo saber um pouco sobre as raízes das RNN (Recurrent Neural Networks) ilustradas abaixo:
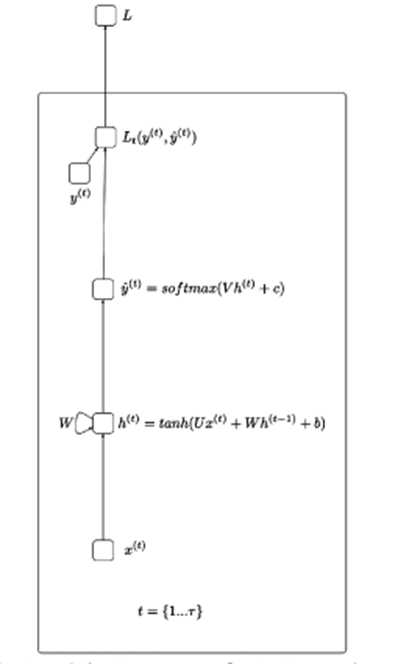
Simplificando, o RNN ajuda a processar dados na forma de uma sequência sequencial – como processamento de fala, ações,… A ideia da figura acima é que a entrada x passará pelas camadas ocultas e retornará o valor de saída (pode ser 1 array) Da saída que passa pela função de perda será y_hat.
X(t): Valor de entrada no passo de tempo t
H(t): Estado oculto no passo de tempo t
O(t): Valor de saída no passo de tempo t
Y_hat: Vetor de probabilidade normalizado através da função softmax no passo de tempo t
U, V, W: As matrizes de peso no RNN correspondem às conexões na direção do início ao estado oculto, do estado oculto à saída e do estado oculto ao estado oculto.
B, c: Desvio (viés)
O LSTM ajuda a superar o gradiente de fuga de RNN. Como usamos gradientes para treinar neurônios e o RNN é afetado pela memória de curto prazo quando os dados de entrada são longos, o RNN pode esquecer informações importantes transmitidas desde o início.
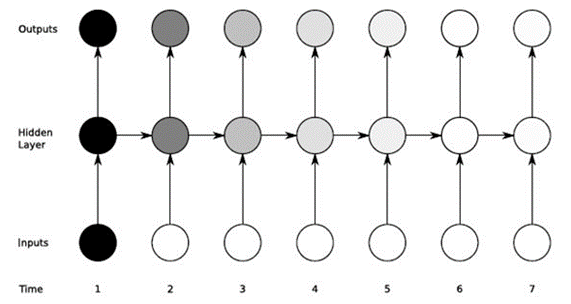
Por exemplo, ao assistir a uma série de filmes, nosso cérebro salvará as informações de conteúdo das partes anteriores e as combinará com o episódio que estamos assistindo para criar uma história.
O LSTM ajuda a reduzir pontos de dados desnecessários por ter portas instaladas internamente e ter um estado de célula em execução por toda parte.

Existem muitos artigos e imagens que explicam o funcionamento de cada portão e as funções ativas. Então aqui eu tento usar a matemática para explicar esse cara. Para resumir rapidamente, o LSTM usa 1 estado de célula e 3 portas para processar os dados de entrada. A receita eu coloco na foto abaixo:


Esta é a operação do LSTM em uma etapa de tempo, o que significa que essas fórmulas serão recalculadas quando em outra etapa de tempo. E os pesos (Wf, Wi, Wo, Wc, Uf, Ui, Uo, Uc) e viés (bf, bi, bo, bc) não mudam.
Por exemplo, para implantar o LSTM em 10 etapas de tempo, você pode fazer o seguinte:
sequência_len = 10
para i no intervalo (0,sequence_len):
# se estamos no passo inicial
# inicializa h(t-1) e c(t-1)
# aleatoriamente
se i==0:
ht_1 = aleatório()
ct_1 = aleatório()
senão:
h_1 = h_t
ct_1 = c_t
f_t = sigmóide (
matrix_mul(Wf, xt) +
matrix_mul(Uf, ht_1) +
namorado
)
i_t = sigmóide (
matrix_mul(Wi, xt) +
matrix_mul(Ui, ht_1) +
bi
)
o_t = sigmoide (
matrix_mul(Wo, xt) +
matrix_mul(Uo, ht_1) +
bo
)
cp_t = tanh (
matrix_mul(Wc, xt) +
matrix_mul(Uc, ht_1) +
bc
)
c_t = element_wise_mul(f_t, ct_1) +
element_wise_mul(i_t, cp_t)
h_t = element_wise_mul(o_t, tanh(c_t))
Um problema indispensável em matemática linear é a dimensionalidade dos dados (essa pode ser a parte que eu terei que reler no futuro porque muitas vezes está na lista de perguntas da entrevista).
Com as fórmulas do LSTM em um timestep da seguinte forma:
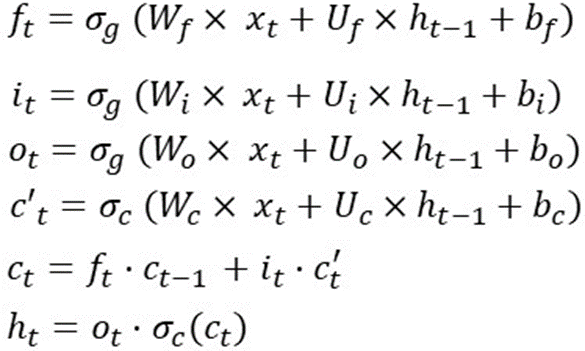
Digamos que dim(o(t)) é [12×1] => dim(h(t)) e dim(c(t)) é [12×1] porque h(t) é uma multiplicação elemento por elemento entre o( t) e tanh(c(t)).
E x(t) tem dimensões de [80×1] => W(f) é [12×80] porque f(t) = [12×1] e x(t)=[80×1]
Bf, bi, bc, bo têm dimensões de [12×1]
E Uf, Ui, Uc, Uo têm dimensões de [12×12]
Portanto, o peso total do LSTM é: 4*[12×80] + 4*[12×12] + 4*[12×1] = 4464.
Observando o cálculo acima, pode-se ver que os LSTMs estão interessados em duas coisas: Dimensão de entrada e Dimensão de saída (alguns blogs podem chamá-lo de número de unidades LSTM ou dimensão oculta,…).
Resumindo o tamanho da matriz de peso de LSTM é 4*Output_Dim*(Output_Dim + Input_Dim + 1)
Há uma nota sobre o parâmetro que muitas pessoas confundem:

No Keras existe um parâmetro que é return_sequence (retorna true, false) quando return_squence=False (padrão) é muitos para um e caso contrário True será de muitos para muitos.
Exemplo com dados de entrada X de tamanho [5×126]
Os modelos são os seguintes:
modelo = Sequencial()
model.add(LSTM(64, return_sequences=True, ativação='relu', input_shape=(5.126)))
model.add(LSTM(128, return_sequences=True, ativação='relu'))
model.add(LSTM(64, return_sequences=Falso, ativação='relu'))
model.add(Dense(64, ativação='relu'))
model.add(Dense(32, ativação='relu'))
model.add(Dense(actions.shape[0], ativação='softmax'))
Pode ser visto através da primeira camada LSTM com um número oculto de 64 => O número de params após passar por esta camada é:
4*((126+64)*64+64) = 48896 (o mesmo para as 2 camadas LSTM seguintes e sua saída será a entrada da próxima camada).
Para camadas Densas (é uma camada em keras com output_dim sendo a dimensão de saída dessa camada) então o número de novos parâmetros é igual a output_dim * output_dim (da camada anterior dita)+1
Exemplo com a primeira camada densa: o número de parâmetros é: 64*(64+1)=4160

Para resumir neste artigo, tentei explicar o funcionamento do LSTM da perspectiva do cálculo de parâmetros, este é um passo muito importante para ajudá-lo a projetar e acelerar o modelo de aprendizado de máquina.

hocvietcode.com là website chia sẻ và cập nhật tin tức công nghệ, chia sẻ kiến thức, kỹ năng. Chúng tôi rất cảm ơn và mong muốn nhận được nhiều phản hồi để có thể phục vụ quý bạn đọc tốt hơn !
Liên hệ quảng cáo: trienkhaiweb@gmail.com