













Giới thiệu
hocvietcode.com là website chia sẻ và cập nhật tin tức công nghệ, chia sẻ kiến thức, kỹ năng. Chúng tôi rất cảm ơn và mong muốn nhận được nhiều phản hồi để có thể phục vụ quý bạn đọc tốt hơn !
Liên hệ quảng cáo: [email protected]
Recently, I did a small small project using LSTMs, but reading Vietnamese documents to understand deeply about speaking is not very clear, there is this article https://dominhhai.github.io/vi/2017/10 /what-is-lstm/ is translated from a foreign site, which I think is quite good. Then, through the project I did, I would like to be here to share some things for everyone and myself in the future when I haven't used it for a long time and then read it again to think.
Mục lục
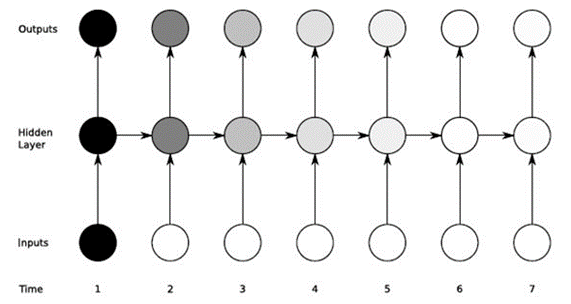
Before explaining about LSTMs, I think I should know a little about the roots of the RNN (Recurrent Neural Networks) illustrated below:
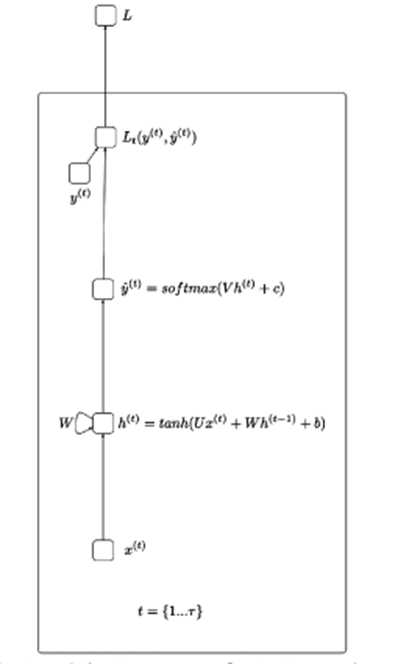
Simply put, RNN helps to process data in the form of a sequential sequence – such as processing speech, actions,… The idea of the above figure is that the input x will go through the hidden layers and return the output value. (can be 1 array) From the output going through the loss function will be y_hat.
X(t): Input value at time step t
H(t): Hidden state at time step t
O(t): Output value at time step t
Y_hat: Normalized probability vector through softmax function at time step t
U, V, W: The weight matrices in the RNN correspond to the connections in the direction from the beginning to the hidden state, from the hidden state to the output, and from the hidden state to the hidden state.
B, c: Deviation (bias)
LSTM helps to overcome Vanishing gradient of RNN. Since we use gradients to train neurons and RNN is affected by short term memory when input data is long, RNN may forget important information transmitted right from the start. head.
For example, when watching a movie series, our brain will save the content information of the previous parts and combine it with the episode we are watching to create a story.
LSTM helps to reduce unnecessary data points by having gates installed internally and having a cell state running throughout.

There are many articles and pictures that explain the operation of each gate and active functions. So here I try to use math to explain this guy. To summarize quickly, LSTM uses 1 cell state and 3 gates to process input data. The recipe I put in the picture below:


This is the operation of the LSTM in a time step, which means that these formulas will be recalculated when in another time step. And the weights (Wf, Wi, Wo, Wc, Uf, Ui, Uo, Uc) and bias (bf, bi, bo, bc) do not change.
For example, to deploy LSTM on 10 timesteps, you can do the following:
sequence_len = 10
for i in range (0,sequence_len):
# if we are on the initial step
# initialize h(t-1) and c(t-1)
# randomly
if i==0:
ht_1 = random()
ct_1 = random()
else:
ht_1 = h_t
ct_1 = c_t
f_t = sigmoid (
matrix_mul(Wf, xt) +
matrix_mul(Uf, ht_1) +
bf
)
i_t = sigmoid (
matrix_mul(Wi, xt) +
matrix_mul(Ui, ht_1) +
bi
)
o_t = sigmoid (
matrix_mul(Wo, xt) +
matrix_mul(Uo, ht_1) +
bo
)
cp_t = tanh (
matrix_mul(Wc, xt) +
matrix_mul(Uc, ht_1) +
bc
)
c_t = element_wise_mul(f_t, ct_1) +
element_wise_mul(i_t, cp_t)
h_t = element_wise_mul(o_t, tanh(c_t))
An indispensable problem in linear math is the dimensionality of the data (this may be the part that I will have to re-read in the future because it is often on the list of interview questions).
With the formulas of the LSTM at a timestep as follows:
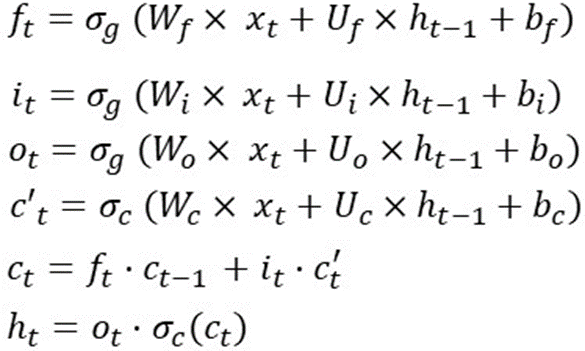
Let's say dim(o(t)) is [12×1] => dim(h(t)) and dim(c(t)) is [12×1] because h(t) is an element-by-element multiplication between o(t) and tanh(c(t)).
And x(t) has dimensions of [80×1] => W(f) is [12×80] because f(t) = [12×1] and x(t)=[80×1]
Bf, bi, bc, bo have dimensions of [12×1]
And Uf, Ui, Uc, Uo have dimensions of [12×12]
So the total weight of the LSTM is: 4*[12×80] + 4*[12×12] + 4*[12×1] = 4464.
Looking at the calculation above, it can be seen that LSTMs are interested in two things: Input dimension and Output dimensionality (some blogs may call it number of LSTM units or hidden dimention,…).
Summarizing the weight matrix size of LSTM is 4*Output_Dim*(Output_Dim + Input_Dim + 1)
There is a note about the parameter that many people confuse:

In Keras there is a parameter that is return_sequence (returns true, false) when return_squence=False (default) it is many to one and otherwise True will be from many to many.
Example with input data X of size [5×126]
Models are as follows:
model = Sequential()
model.add(LSTM(64, return_sequences=True, activation='relu', input_shape=(5,126)))
model.add(LSTM(128, return_sequences=True, activation='relu'))
model.add(LSTM(64, return_sequences=False, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(actions.shape[0], activation='softmax'))
It can be seen through the first LSTM layer with a hidden number of 64 => The number of params after passing this layer is:
4*((126+64)*64+64) = 48896 (same for the following 2 LSTM layers and its output will be the input of the next layer).
For Dense layers (is a layer in keras with output_dim being the output dimension of that layer) so the number of new parameters is equal to output_dim * output_dim (of the previous layer said)+1
Example with the first dense layer: the number of parameters is: 64*(64+1)=4160

To summarize in this article, I have tried to explain the workings of LSTM from the perspective of calculating parameters, this is a pretty important step to help you design and accelerate the machine learning model.
hocvietcode.com là website chia sẻ và cập nhật tin tức công nghệ, chia sẻ kiến thức, kỹ năng. Chúng tôi rất cảm ơn và mong muốn nhận được nhiều phản hồi để có thể phục vụ quý bạn đọc tốt hơn !
Liên hệ quảng cáo: [email protected]