
Aggregation Pipeline – Các pipeline tổng hợp
Trong buổi học này, chúng ta sẽ tìm hiểu:
- Giải thích Aggregation Pipeline trong MongoDB
- Mô tả các giai đoạn (stages) trong aggregation pipeline
- Giải thích các biểu thức (expressions) có thể sử dụng trong aggregation pipeline
Aggregation trong MongoDB giúp nhóm nhiều document lại với nhau, áp dụng một số thao tác xử lý và trả về một kết quả tổng hợp. Điều này giúp thu được những thông tin hữu ích phục vụ cho việc ra quyết định trong kinh doanh.
Một trong các phương pháp thực hiện data aggregation trong MongoDB là aggregation pipeline.
Trong bài viết này sẽ giải thích:
- Aggregation pipeline trong MongoDB là gì
- Các stage khác nhau trong aggregation pipeline
- Các expression có thể sử dụng trong aggregation pipeline
Mục lục
4.1 Các giai đoạn của Aggregation Pipeline
Trong MongoDB, pipeline là một chuỗi các stage xử lý dữ liệu.
Trong pipeline:
- Stage đầu tiên lấy một số document từ database làm input
- Thực hiện tính toán để tạo ra kết quả
- Kết quả này được truyền sang stage tiếp theo
- Quá trình tiếp tục cho đến stage cuối cùng của pipeline
- Stage cuối cùng trả về kết quả tổng hợp (aggregated output)
Các stage của pipeline được đặt trong một mảng (array) của phương thức:
db.collection.aggregate()
Aggregation pipeline có thể gồm nhiều stage khác nhau. Trong session này sẽ thảo luận 9 stage quan trọng nhất của aggregation pipeline:
$project$limit$group$match$sort$skip$addFields$merge$out
4.1.1 Stage $project
Stage $project dùng để:
- Lấy các document cần thiết
- Thao tác với document bằng cách:
- Thêm field mới
- Xóa field hiện có
- Thêm field được tính toán
Sau đó các document đã chỉnh sửa sẽ được chuyển sang stage tiếp theo.
Cú pháp:
{ $project: { <specification(s)> } }
Trong đó <specification(s)> có thể nhận các giá trị như trong Bảng 4.1.
Bảng 4.1 Giá trị của <specification> trong $project
| Value | Description | Example |
|---|---|---|
| field: 0 hoặc false | Field không được đưa vào kết quả | {_id:0} |
| field: 1 hoặc true | Field được đưa vào kết quả | {certificate_number:1} |
| new field: expression | Tạo field mới dựa trên expression | {grade:"Grade field"} |
Ví dụ
Giả sử người dùng muốn thực hiện aggregation trên dữ liệu trong collection inspections của database sample_training.
Để xem dữ liệu hiện có trong collection:
db.inspections.find()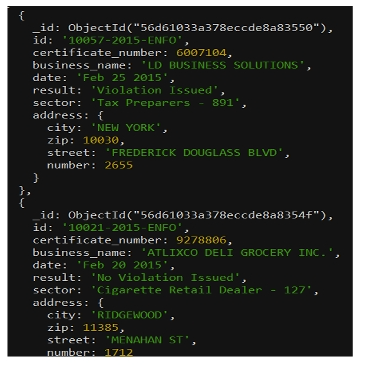
Chỉ hiển thị một số field
Giả sử người dùng chỉ muốn xem các field:
- certificate_number
- business_name
- address
Truy vấn:
db.inspections.aggregate([
{ $project :
{ certificate_number:1,
business_name:1,
address:1
}
}
])
Lưu ý:
Field _id được hiển thị mặc định, vì vậy nếu muốn loại bỏ nó cần đặt:
_id:0
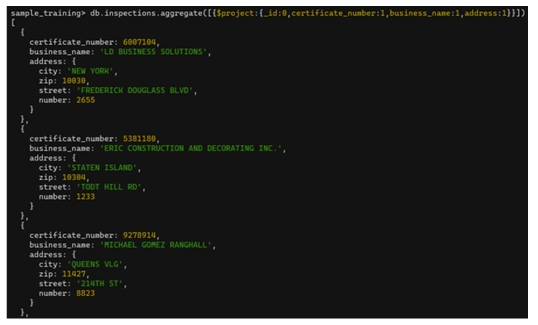
Kết quả trả về tất cả document nhưng chỉ chứa các field được chỉ định.
4.1.2 Stage $limit
Stage $limit được sử dụng để giới hạn số lượng document được chuyển sang stage tiếp theo.
Cú pháp:
{ $limit: <64-bit positive integer> }
Số document được chuyển sang stage tiếp theo được xác định bởi giá trị <64-bit positive integer>.
Ví dụ
Sử dụng $limit và $project trên collection inspections để trả về 2 document và chỉ hiển thị các field:
- certificate_number
- business_name
- address
Truy vấn:
db.inspections.aggregate([
{ $limit:2 },
{ $project:{
certificate_number:1,
business_name:1,
address:1
}}
])
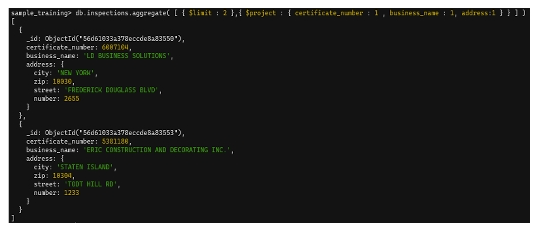
4.1.3 Stage $group
Stage $group được sử dụng để nhóm các document dựa trên:
- một field
- một khóa
- hoặc một nhóm field
Cú pháp:
{
$group:{
_id:<expression>, // Group key
<field1>:{<accumulator>:<expression>},
...
}
}
Các tham số trong cú pháp này được mô tả trong Bảng 4.2.
Bảng 4.2 Tham số của $group
| Specification | Description |
|---|---|
_id:<expression> | Xác định field dùng để nhóm dữ liệu |
<field> | Field dùng để tính toán |
<accumulator> | Hàm được áp dụng lên field |
Các hàm accumulator phổ biến
| Function | Description |
|---|---|
$avg | Tính trung bình |
$bottom | Lấy phần tử nhỏ nhất |
$bottomN | Lấy N phần tử nhỏ nhất |
$top | Lấy phần tử lớn nhất |
$topN | Lấy N phần tử lớn nhất |
$min | Giá trị nhỏ nhất |
$minN | N giá trị nhỏ nhất |
$max | Giá trị lớn nhất |
$mergeObjects | Gộp các document |
$first | Giá trị của document đầu tiên |
$last | Giá trị của document cuối cùng |
$count | Đếm số document |
$sum | Tính tổng giá trị |
Ví dụ $group
Giả sử người dùng muốn:
- Nhóm document theo
address.city - Đếm số document trong mỗi nhóm
Truy vấn:
db.inspections.aggregate([
{ $group:{
_id:"$address.city",
count:{ $count:{} }
}}
])

Ví dụ tiếp theo
Người dùng muốn:
- Giới hạn 5000 document trước khi nhóm
- Nhóm theo address.city
- Đếm số document mỗi nhóm
Truy vấn:
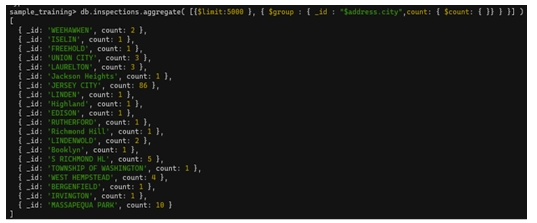
db.inspections.aggregate([
{ $limit: 5000 },
{ $group: { _id: "$address.city", count: { $count: {} } } }
])
$group kết hợp $limitĐổi thứ tự các stage
Người dùng cũng có thể đổi thứ tự $group và $limit.
Ví dụ:
- Nhóm document theo address.city
- Đếm số document trong mỗi nhóm
- Sau đó chỉ hiển thị 10 nhóm
db.inspections.aggregate([
{ $group: { _id: "$address.city", count: { $count: {} } } },
{ $limit: 10 }
])
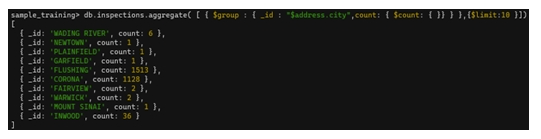
$group kết hợp $limit📌 Lưu ý
Kết quả đầu ra sẽ thay đổi tùy theo thứ tự các stage trong pipeline.
4.1.4 Stage $match
Giai đoạn $match trong aggregation pipeline giúp lọc các document dựa trên một điều kiện, sau đó chuyển kết quả sang stage tiếp theo.
Cú pháp:
{$match: { <expression> } ... }
Nguyên lý hoạt động
$match nhận document làm đầu vào và lọc chúng theo biểu thức điều kiện.
Ví dụ:
Trong collection inspections, người dùng muốn:
- Ẩn trường
_id - Hiển thị các trường
business_namevàaddress.city - Chỉ lấy các document có
address.city = "JERSEY CITY" - Giới hạn 10 document
Truy vấn:
db.inspections.aggregate([
{ $project: { _id:0, "address.city":1, business_name:1 } },
{ $match: { "address.city": "JERSEY CITY" } },
{ $limit:10 }
])
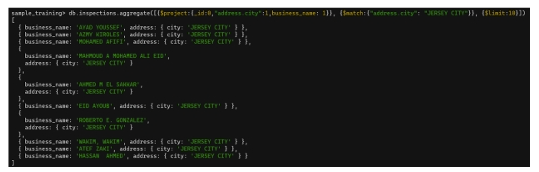
$match với $limit và $project4.1.5 Stage $sort
Như tên gọi, $sort dùng để sắp xếp các document theo thứ tự tăng hoặc giảm dựa trên một hoặc nhiều trường.
Danh sách đã sắp xếp sẽ được chuyển sang stage tiếp theo.
Nếu sắp xếp theo nhiều trường, MongoDB sẽ sắp xếp từ trái sang phải theo thứ tự các trường.
Cú pháp:
{$sort: { field1: <sort order>, field2: <sort order>, ... }}
Bảng 4.4: Các tham số của $sort
| Tham số | Mô tả |
|---|---|
| field1, field2 | Tên trường cần sắp xếp |
| sort order | 1 = tăng dần, -1 = giảm dần |
Ví dụ
Trong collection inspections, người dùng muốn:
- Sử dụng 5000 document
- Ẩn trường
_id - Hiển thị
business_namevàaddress.city - Sắp xếp theo:
address.citygiảm dầnbusiness_nametăng dần
- Chỉ hiển thị 10 document
Truy vấn:
db.inspections.aggregate([
{ $project:{ _id:0,"address.city":1,business_name:1 } },
{ $limit:5000 },
{ $sort:{ "address.city":-1,"business_name":1 } },
{ $limit:10 }
])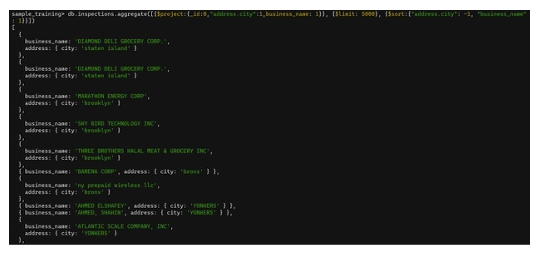
$sort với $limit và $projectTrong kết quả:
- Trường
address.cityđược sắp xếp theo thứ tự giảm dần. - Vì vậy:
- Các tên thành phố viết chữ thường sẽ xuất hiện trước theo thứ tự giảm dần.
- Sau đó các tên thành phố viết chữ hoa cũng xuất hiện theo thứ tự giảm dần.
- Hai bản ghi có cùng tên thành phố sẽ được sắp xếp tăng dần theo
business_namenhư đã chỉ định.
4.1.6 Stage $skip
Giai đoạn $skip được dùng để bỏ qua một số document trước khi chuyển sang stage tiếp theo.
Cú pháp của $skip:
{$skip: <64-bit positive integer>}
Số lượng document được chuyển sang stage tiếp theo sẽ được kiểm soát bởi số lượng chỉ định trong <64-bit positive integer>.
Ví dụ
Giả sử người dùng muốn:
- Sử dụng truy vấn giống truy vấn của
$sort - Nhưng bỏ qua 10 document đầu tiên thay vì giới hạn kết quả là 10 document
Truy vấn:
db.inspections.aggregate([
{ $project:{ _id:0,"address.city":1,business_name:1 } },
{ $limit:5000 },
{ $sort:{ "address.city":-1,"business_name":1 } },
{ $skip:10 }
])
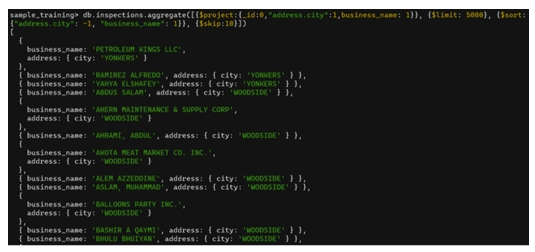
$skip với $limit, $sort và $projectTrong kết quả:
- 10 document đầu tiên (những document có
address.cityviết chữ thường) đã bị bỏ qua.
4.1.7 Stage $addFields
Đúng như tên gọi, giai đoạn $addFields được dùng để thêm một trường mới vào document.
Nó sẽ:
- Lấy các document từ stage trước
- Thêm trường mới được chỉ định
- Trả về document đã cập nhật cho stage tiếp theo
Cú pháp:
{$addFields: { <new field1>: <expression>, ... }}
Trong đó:
<new field1>: tên trường mới<expression>: giá trị của trường
Người dùng có thể thêm nhiều trường trong một truy vấn.
Ví dụ
Trong collection inspections, người dùng muốn:
- Thêm trường
address.country - Giá trị =
"USA"
Sau đó hiển thị các trường:
business_nameaddress.cityaddress.country
Cho 5 document.
Truy vấn:
db.inspections.aggregate([
{ $addFields:{ "address.country":"USA" } },
{ $limit:5 },
{ $project:{ _id:0,business_name:1,"address.city":1,"address.country":1 } }
])

$addFields với $limit và $project4.1.8 Stage $out
Giai đoạn $out dùng để ghi kết quả của pipeline vào một collection.
Nếu collection đã tồn tại:
$outsẽ ghi đè toàn bộ dữ liệu cũ bằng kết quả truy vấn.
Cú pháp:
{ $out: { db: "<output-db>", coll: "<output-collection>" } }
Trong đó:
- db: tên database chứa collection kết quả
- coll: tên collection kết quả
Ví dụ
Người dùng muốn:
- Lấy 8 document từ collection
inspections - Chỉ giữ các trường:
certificate_numberbusiness_nameaddress
- Lưu kết quả vào collection
out_inspection1
Truy vấn:
db.inspections.aggregate([
{ $limit:8 },
{ $project:{ certificate_number:1,business_name:1,address:1 } },
{ $out:"out_inspection1" }
])
Sau đó để xem dữ liệu:
db.out_inspection1.find()

out_inspection1Collection out_inspection1 gồm 8 document, trong đó 2 document cuối có address.city = NEW YORK.
Bây giờ, giả sử người dùng muốn:
- bỏ qua 10 document đầu tiên trong collection
inspections - sau đó đưa vào collection
out_inspection13 document có các trường:certificate_numberbusiness_nameaddress
- với điều kiện
address.citylà NEW YORK
Để làm điều đó, người dùng có thể chạy truy vấn sau:
db.inspections.aggregate([
{ $skip: 10 },
{ $match: { "address.city": "NEW YORK" } },
{ $project: { certificate_number: 1, business_name: 1, address: 1 } },
{ $limit: 3 },
{ $out: "out_inspection1" }
])
Để xem các document trong collection out_inspection1, người dùng có thể chạy truy vấn:
db.out_inspection1.find()Hình 4.12 hiển thị kết quả của truy vấn này.

out_inspection1Hình 4.12 cho thấy collection out_inspection1 hiện có 3 document thay vì 8 document ban đầu.
Điều này là do stage $out đã xóa các document trước đó và thay thế chúng bằng các document từ truy vấn gần nhất.
4.1.9 Stage $merge
Giai đoạn $merge tương tự như giai đoạn $out và được dùng để lưu kết quả đầu ra của pipeline vào một collection mới trong cùng database hoặc ở database khác.
Điểm khác biệt là $merge không xóa các document cũ.
Nó sử dụng một trường định danh (identifier) để xác định duy nhất document, và khi tìm thấy bản ghi trùng khớp thì nó thực hiện các hành động như:
- thay thế document đang tồn tại
- giữ nguyên document đang tồn tại
- hoặc gộp (merge) các document
Nếu không tìm thấy bản ghi khớp, nó sẽ thực hiện các hành động như:
- chèn document mới
- loại bỏ document
- hoặc báo lỗi
Đó là các hành động như chèn document hoặc loại bỏ document. Cú pháp của $merge như sau:
{
$merge: {
into: <collection> -or- { db: <db>, coll: <collection> },
on: <identifier field> -or- [ <identifier field1>, ... ],
let: <variables>,
whenMatched: <replace|keepExisting|merge|fail|pipeline>,
whenNotMatched: <insert|discard|fail>
}
}
Danh sách phía dưới mô tả các tham số được sử dụng trong giai đoạn $merge.
Các tham số của giai đoạn $merge
1. into
Chỉ định collection mà các document sẽ được đưa vào trong cùng database nơi truy vấn đang được thực hiện.
Nếu không phải cùng database, tham số này sẽ chỉ định database và collection mà các document sẽ được ghi vào.
Nếu collection được chỉ định chưa tồn tại, MongoDB sẽ tạo một collection mới.
2. on
Chỉ định trường định danh duy nhất cho các document.
Nó được dùng để xác định xem một document trong kết quả truy vấn có khớp với một document trong collection đầu ra hay không.
3. whenMatched
Chỉ định hành động phải thực hiện nếu identifier của một document trong collection đầu ra khớp với identifier của document trong kết quả truy vấn.
Tham số này cho phép:
- thay thế document đang tồn tại
- giữ nguyên document đang tồn tại
- hoặc gộp các document
Khi gộp document, các field còn thiếu trong collection đầu ra sẽ được thêm vào.
Nếu các field tồn tại ở cả hai document, giá trị từ kết quả truy vấn sẽ ghi đè lên giá trị trong collection đầu ra.
Nếu identifier trong kết quả truy vấn và collection đầu ra khớp nhau, thao tác merge cũng có thể bị lỗi tùy theo cấu hình.
4. whenNotMatched
Chỉ định hành động phải thực hiện nếu identifier của document trong collection đầu ra không khớp với identifier của document trong kết quả truy vấn.
Trong trường hợp này, document từ kết quả truy vấn có thể:
- được chèn vào collection đầu ra
- bị loại bỏ
- hoặc thao tác merge có thể bị lỗi
Ví dụ, giả sử người dùng muốn đưa các document từ collection inspections vào collection out_inspection1, trong đó address.city là HAZLET.
Nếu tìm thấy bản ghi khớp, các document phải được thay thế trong collection out_inspection1.
Nếu không tìm thấy bản ghi khớp, document phải được chèn vào collection out_inspection1.
Để làm điều đó, người dùng có thể chạy truy vấn sau:
db.inspections.aggregate([
{ $skip: 10 },
{ $match: { "address.city": "HAZLET" } },
{ $project: { certificate_number: 1, business_name: 1, address: 1 } },
{
$merge: {
into: {
db: "sample_training",
coll: "out_inspection1"
},
on: "_id",
whenMatched: "replace",
whenNotMatched: "insert"
}
}
])
Để xem các document trong collection out_inspection1, người dùng có thể chạy truy vấn:
db.out_inspection1.find()
Hình 4.13 hiển thị kết quả của truy vấn này.

out_inspection1Hình 4.13 cho thấy collection out_inspection1 hiện có 4 document thay vì 3 document ban đầu.
Lý do là document có address.city là HAZLET không tìm thấy bản ghi khớp, vì vậy document đó đã được chèn vào collection.
4.1.10 $count stage
Stage $count là một toán tử aggregation dùng để đếm số lượng document đi qua pipeline.
Nó thường được đặt ở cuối aggregation pipeline và trả về một document duy nhất chứa kết quả đếm.
Cú pháp
{ $count: "<outputField>" }
Trong đó:
<outputField>là tên field sẽ chứa kết quả đếm.
Lưu ý
$count không thể tùy chỉnh gì thêm ngoài việc đặt tên field output.
Nó phải được đặt sau các stage như:
$match$project- hoặc các stage khác
để lọc hoặc định hình dữ liệu trước khi đếm.
Ví dụ
Nếu muốn đếm số user không hoạt động (inactive) và sống tại Los Angeles, ta có thể dùng $count.
db.users.aggregate([
{
$match: {
city: "Los Angeles",
isActive: false
}
},
{
$count: "inactive_users_in_LA"
}
])
Kết quả
[
{ inactive_users_in_LA: 8 }
]
Truy vấn hoạt động theo trình tự:
1️⃣ $match lọc các document có:
city = "Los Angeles"
isActive = false
2️⃣ $count đếm số document thỏa điều kiện.
4.1.11 $sortByCount stage
Stage $sortByCount dùng để:
- nhóm document theo một field
- đếm số lượng document trong mỗi nhóm
- tự động sắp xếp giảm dần theo count
Nó kết hợp chức năng của $group và $sort trong một bước.
Cú pháp
{ $sortByCount: "<field>" }
Trong đó:
<field> là tên field muốn group và đếm.
Ví dụ
Đếm số user trong mỗi thành phố và sắp xếp từ nhiều đến ít.
db.users.aggregate([
{ $sortByCount: "$city" }
])
Kết quả
{ _id: "New York", count: 15 }
{ _id: "Los Angeles", count: 14 }
{ _id: "Phoenix", count: 13 }
{ _id: "Philadelphia", count: 10 }
{ _id: "Dallas", count: 10 }
{ _id: "San Jose", count: 9 }
{ _id: "San Antonio", count: 9 }
{ _id: "Houston", count: 8 }
{ _id: "Chicago", count: 7 }
{ _id: "San Diego", count: 5 }
Ở đây:
_id= giá trị của field group (city)count= số document thuộc nhóm đó.
4.1.12 $sample stage
Stage $sample dùng để lấy ngẫu nhiên một số document từ collection.
Nó đặc biệt hữu ích khi:
- tạo mock dataset
- hiển thị featured users / featured products
- phân tích dữ liệu bằng random sampling
Cách hoạt động
MongoDB sẽ:
- shuffle các document nội bộ
- trả về số lượng document được yêu cầu
- không phụ thuộc thứ tự dữ liệu ban đầu
Cú pháp
{ $sample: { size: <number> } }
Trong đó:
size là số document muốn lấy ngẫu nhiên.
Ví dụ
Lấy 5 user ngẫu nhiên để hiển thị.
db.users.aggregate([
{ $sample: { size: 5 } }
])
Kết quả
MongoDB trả về 5 document bất kỳ trong collection.
Ví dụ:
{
name: "Bob Turner",
age: 55,
email: "[email protected]",
city: "New York",
isActive: false
}
{
name: "Charlie Walker",
age: 52,
city: "Los Angeles",
isActive: true
}
{
name: "Fiona Turner",
age: 51,
city: "Houston"
}
{
name: "Diana Turner",
age: 57,
city: "Philadelphia"
}
{
name: "Diana Anderson",
age: 19,
city: "San Jose"
}
4.2 Aggregation Pipeline Operators
Các operator trong aggregation pipeline được dùng để thực hiện:
- phép toán số học
- phép toán logic
- xử lý dữ liệu trong pipeline.
Các loại operator gồm:
- Arithmetic operators
- Array operators
- Boolean operators
- Comparison operators
- String operators
4.2.1 Arithmetic Operators
Các toán tử số học thực hiện các phép toán trên dữ liệu và trả về một giá trị duy nhất.
Bảng 4.6 mô tả một số arithmetic operator trong MongoDB.
Bảng 4.6 Arithmetic Operators
| Operator | Chức năng |
|---|---|
$add | Cộng nhiều số hoặc cộng số với date |
$subtract | Trừ hai số hoặc hai date |
$multiply | Nhân nhiều số |
$divide | Chia hai số |
$ceil | Làm tròn lên |
$floor | Làm tròn xuống |
$abs | Giá trị tuyệt đối |
$pow | Lũy thừa |
$exp | e mũ x |
$ln | log tự nhiên |
$log | log theo base |
$log10 | log cơ số 10 |
$mod | phép chia lấy dư |
$round | làm tròn |
$sqrt | căn bậc hai |
$trunc | cắt phần thập phân |
Ví dụ $add
Cú pháp
$add: [ <expression1>, <expression2>, ... ]
Trong đó <expression> có thể là:
- số
- hoặc kết hợp số và date.
Ví dụ
Trong database sample_analytics, giả sử muốn:
- tăng sales limit thêm 2000
- lưu kết quả vào field newLimit
db.accounts.aggregate([
{
$project:{
account_id:1,
limit:1,
newLimit:{
$add:["$limit",2000]
}
}
}
])
Kết quả
account_id: 371138
limit: 9000
newLimit: 11000
account_id: 674364
limit: 10000
newLimit: 120004.2 Aggregation Pipeline Operators
Các toán tử (operators) của aggregation pipeline được sử dụng trong nhiều stage của pipeline để thực hiện các phép tính số học hoặc logic.
Các loại toán tử aggregation pipeline gồm:
- Arithmetic operators (toán tử số học)
- Array operators (toán tử mảng)
- Boolean operators (toán tử logic)
- Comparison operators (toán tử so sánh)
- String operators (toán tử chuỗi)
4.2.1 Arithmetic Operators
Các toán tử số học thực hiện các phép toán số học trên các toán hạng và trả về một giá trị duy nhất.
Bảng 4.6 mô tả một số toán tử số học trong MongoDB.
Bảng 4.6: Arithmetic Operators
| Operator | Mô tả |
|---|---|
$add | Cộng hai hoặc nhiều số hoặc một số với một giá trị ngày. Nếu có giá trị date thì các giá trị khác được xem là milliseconds. |
$subtract | Trừ hai số hoặc hai ngày. Nếu trừ hai ngày sẽ trả về millisecond difference. |
$multiply | Nhân hai hoặc nhiều số. |
$divide | Chia hai số. |
$ceil | Trả về số nguyên nhỏ nhất ≥ giá trị cho trước. |
$floor | Trả về số nguyên lớn nhất ≤ giá trị cho trước. |
$abs | Trả về giá trị tuyệt đối của số. |
$pow | Tính lũy thừa của một số. |
$exp | Tính e^x (số Euler mũ x). |
$ln | Log tự nhiên. |
$log | Log với cơ số chỉ định. |
$log10 | Log cơ số 10. |
$mod | Phép chia lấy dư. |
$round | Làm tròn số. |
$sqrt | Căn bậc hai. |
$trunc | Cắt phần thập phân của số. |
Ví dụ $add
Cú pháp:
{$add:[<expression1>,<expression2>,...]}
Trong đó <expression> có thể là:
- số
- hoặc kết hợp giữa số và date.
Ví dụ
Trong database sample_analytics, người dùng muốn:
- tăng limit bán hàng trong collection
accountsthêm 2000 - lưu kết quả vào field newLimit
Truy vấn:
db.accounts.aggregate([
{
$project:{
account_id:1,
limit:1,
newLimit:{$add:["$limit",2000]}
}
}
])
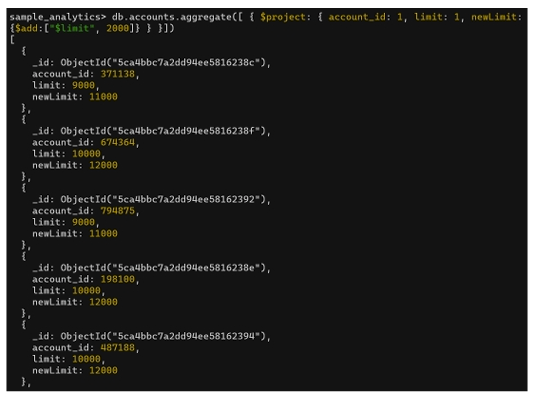
$addKết quả hiển thị:
- giá trị limit cũ
- và newLimit = limit + 2000
4.2.2 Array Operators
Một array là tập hợp các giá trị thuộc cùng một biến.
Mỗi phần tử trong array có index bắt đầu từ 0.
MongoDB cung cấp nhiều toán tử làm việc với array.
Bảng 4.7: Array Operators
| Operator | Mô tả |
|---|---|
$first | Lấy phần tử đầu tiên của array |
$firstN | Lấy N phần tử đầu tiên |
$last | Lấy phần tử cuối |
$lastN | Lấy N phần tử cuối |
$isArray | Kiểm tra giá trị có phải array |
$concatArrays | Nối nhiều array |
$filter | Lọc phần tử của array theo điều kiện |
$sortArray | Sắp xếp array |
$maxN | Lấy N giá trị lớn nhất |
$minN | Lấy N giá trị nhỏ nhất |
$arrayElemAt | Lấy phần tử tại index xác định |
$indexOfArray | Tìm vị trí của phần tử trong array |
$size | Đếm số phần tử của array |
$slice | Lấy một phần của array |
$arrayToObject | Chuyển key-value array thành document |
$objectToArray | Chuyển document thành array |
$in | Kiểm tra giá trị có trong array |
$map | Áp dụng expression lên từng phần tử |
$range | Tạo array theo dãy số |
Các toán tử array bổ sung
| Operator | Description |
|---|---|
$reduce | Áp dụng expression cho từng phần tử rồi gộp kết quả |
$reverseArray | Đảo thứ tự array |
$zip | Ghép hai array lại theo index |
Ví dụ $first và $last
Cú pháp:
$first:<expression>
$last:<expression>
<expression> phải trả về một array.
Ví dụ
Trong database sample_training, collection grades có:
scores = [exam, quiz, homework]
Người dùng muốn:
- lấy điểm exam (phần tử đầu tiên của array).
Truy vấn:
db.grades.aggregate([
{
$addFields:{
exam_score:{$first:"$scores"}
}
},
{
$project:{
student_id:1,
class_id:1,
exam_score:1
}
}
])
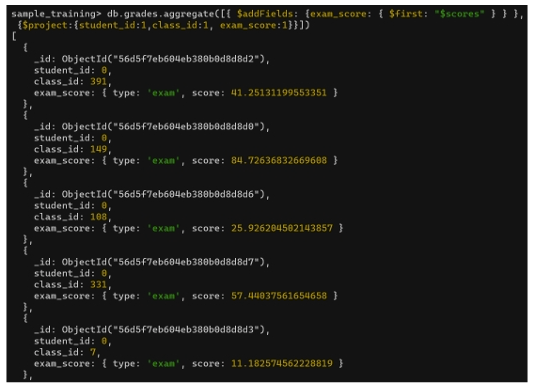
$firstKết quả hiển thị:
student_idclass_idexam_score
Bây giờ giả sử người dùng muốn lấy điểm bài tập (homework score), đây là phần tử cuối cùng trong mảng scores.
Để làm điều này, người dùng có thể chạy truy vấn với toán tử $last như sau:
db.grades.aggregate([
{ $addFields: { homework_score: { $last: "$scores" } } },
{ $project: { student_id:1, class_id:1, homework_score:1 } }
])
$lastKết quả hiển thị điểm homework của mỗi sinh viên, được lấy từ phần tử cuối của mảng scores.
4.2.3 Boolean Operators
Toán tử Boolean nhận các biểu thức (expressions) làm tham số và đánh giá chúng thành giá trị Boolean (true hoặc false).
Sau đó nó trả về một giá trị Boolean như mô tả trong Bảng 4.8.
Bảng 4.8: Boolean Operators
| Name | Description |
|---|---|
$and | Trả về true nếu tất cả biểu thức đều đúng, ngược lại trả về false. Chấp nhận nhiều biểu thức. |
$not | Trả về true nếu biểu thức là false, và ngược lại. Chỉ chấp nhận một biểu thức. |
$or | Trả về true nếu ít nhất một biểu thức đúng. Chấp nhận nhiều biểu thức. |
Ví dụ toán tử $and
Cú pháp:
{ $and: [ <expression1>, <expression2>, ... ] }
Trong cú pháp này:
<expression> có thể là bất kỳ biểu thức hợp lệ nào trả về giá trị Boolean.
Ví dụ thực tế
Trong database sample_training có collection trips, chứa:
tripdurationusertype
Giả sử người dùng muốn:
- tạo field mới
op_status - field này = true nếu:
tripduration = 379
và
usertype = "Subscriber"
Các document khác sẽ có op_status = false.
Truy vấn:
db.trips.aggregate([
{ $project:{ tripduration:1, usertype:1 }},
{ $addFields:{
op_status:{
$and:[
{$eq:["$tripduration",379]},
{$eq:["$usertype","Subscriber"]}
]
}
}},
{ $limit:4 }
])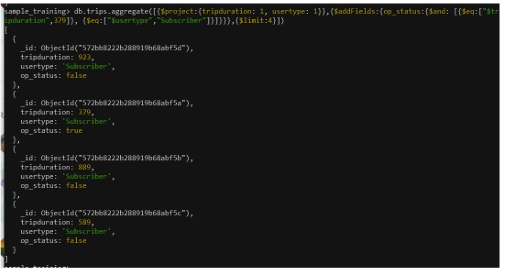
$andKết quả hiển thị field op_status cho mỗi document.
- Nếu điều kiện đúng →
true - Nếu sai →
false
4.2.4 Comparison Operators
Như tên gọi của nó, toán tử so sánh dùng để so sánh hai biểu thức và trả về giá trị Boolean.
Bảng 4.9 liệt kê các toán tử so sánh.
Bảng 4.9: Comparison Operators
| Name | Description |
|---|---|
$cmp | So sánh hai biểu thức. Trả về: 0 nếu bằng nhau 1 nếu biểu thức thứ nhất lớn hơn -1 nếu nhỏ hơn |
$eq | Trả về true nếu hai biểu thức bằng nhau |
$gt | Trả về true nếu biểu thức thứ nhất lớn hơn |
$gte | Trả về true nếu biểu thức thứ nhất lớn hơn hoặc bằng |
$lt | Trả về true nếu biểu thức thứ nhất nhỏ hơn |
$lte | Trả về true nếu biểu thức thứ nhất nhỏ hơn hoặc bằng |
$ne | Trả về true nếu hai biểu thức khác nhau |
Ví dụ $gt và $lt
Cú pháp:
{ $gt/$lt: [ <expression1>, <expression2> ] }
Ví dụ thực tế
Trong database sample_analytics có collection accounts, chứa trường limit.
Người dùng muốn tìm các document có limit:
limit > 9000
và
limit < 12000
Truy vấn:
db.accounts.aggregate([
{
$project:{
account_id:1,
limit:1,
limit_status:{
$and:[
{$gt:["$limit",9000]},
{$lt:["$limit",12000]}
]
},
products:1
}
}
])
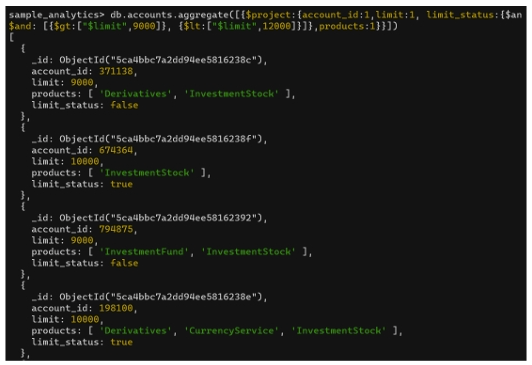
$gt và $ltKết quả hiển thị:
account_idlimitproductslimit_status(true/false)
4.2.5 String Operators
Các toán tử chuỗi làm việc với dữ liệu kiểu string.
Một số toán tử được liệt kê trong Bảng 4.10.
Bảng 4.10: String Operators
| Name | Description |
|---|---|
$concat | Kết hợp nhiều chuỗi thành một chuỗi |
$dateFromString | Chuyển string thành date |
$dateToString | Chuyển date thành chuỗi |
$indexOfBytes | Tìm vị trí substring theo UTF-8 byte index |
$indexOfCP | Tìm vị trí substring theo UTF-8 code point index |
$ltrim | Xóa khoảng trắng ở đầu chuỗi |
$regexFind | Tìm substring đầu tiên khớp regex |
$regexFindAll | Tìm tất cả substring khớp regex |
$regexMatch | Kiểm tra chuỗi có khớp regex |
$replaceOne | Thay thế lần xuất hiện đầu tiên |
$replaceAll | Thay thế tất cả |
$rtrim | Xóa khoảng trắng cuối chuỗi |
$split | Tách chuỗi thành mảng |
$strLenBytes | Độ dài chuỗi theo UTF-8 bytes |
$strLenCP | Độ dài chuỗi theo UTF-8 code points |
$strcasecmp | So sánh chuỗi không phân biệt hoa thường |
$toLower | Chuyển chuỗi thành chữ thường |
$toString | Chuyển giá trị thành string |
$trim | Xóa khoảng trắng đầu và cuối |
$toUpper | Chuyển chuỗi thành chữ hoa |
Ví dụ $concat
Cú pháp:
{ $concat: [ <expression1>, <expression2>, ... ] }
Ví dụ thực tế
Trong database sample_training có collection trips.
Collection này có:
start station nameend station name
Người dùng muốn:
- ghép hai tên trạm
- dùng dấu
" - "làm dấu phân cách - lưu vào field
source_destination.
Truy vấn:
db.trips.aggregate([
{
$project:{
tripduration:1,
source_destination:{
$concat:[
"$start station name",
" - ",
"$end station name"
]
}
}
}
])

$concatKết quả hiển thị:
Howard St & Centre St - E 17 St & Broadway
E 33 St & 2 Ave - South St & Whitehall St
Central Park S & 6 Ave - Central Park S & 6 Ave
...Bài tập
Bối cảnh: quản lý sinh viên và điểm số.
Dataset mẫu
Tạo collection students:
db.students.insertMany([
{
name: "An",
age: 20,
city: "Hanoi",
scores: [7,8,9],
major: "IT",
active: true
},
{
name: "Binh",
age: 22,
city: "Hanoi",
scores: [6,7,8],
major: "Business",
active: false
},
{
name: "Chi",
age: 21,
city: "Danang",
scores: [9,9,8],
major: "IT",
active: true
},
{
name: "Dung",
age: 23,
city: "Saigon",
scores: [5,6,7],
major: "Business",
active: true
},
{
name: "Ha",
age: 20,
city: "Saigon",
scores: [8,7,9],
major: "IT",
active: false
},
{
name: "Lan",
age: 22,
city: "Danang",
scores: [6,8,7],
major: "Marketing",
active: true
}
])
Bài tập thực hành
Bài 1 — $project + $add
Tính tổng điểm của mỗi sinh viên
Yêu cầu output:
name
totalScore
Gợi ý:
$project
$add
Bài 2 — $match
Lấy sinh viên:
city = Hanoi
age > 20
Bài 3 — $group
Đếm số sinh viên theo city
Output:
city
count
Bài 4 — $group + $avg
Tính điểm trung bình của mỗi major
Output:
major
avgScore
Bài 5 — $sort + $limit
Lấy 3 sinh viên có tổng điểm cao nhất
Bài 6 — $skip
Bỏ qua 2 sinh viên đầu, lấy 3 sinh viên tiếp theo
Bài 7 — $addFields
Thêm field:
status = "pass" nếu totalScore >= 24
status = "fail" nếu < 24
Gợi ý:
$cond
Bài 8 — $sortByCount
Thống kê số sinh viên theo major
Bài 9 — $sample
Lấy 2 sinh viên random
Bài 10 — $count
Đếm số sinh viên active = true
Bài 11:
Viết 1 pipeline duy nhất:
-
Lọc sinh viên
active = true -
Tính
totalScore -
Chỉ giữ các field
name
city
totalScore
-
Sắp xếp theo
totalScoregiảm dần -
Lấy 3 sinh viên đầu
Các aggregrate sử dụng trong bài toán này:
| Stage | Dùng |
|---|---|
$project |
✔ |
$match |
✔ |
$group |
✔ |
$sort |
✔ |
$limit |
✔ |
$skip |
✔ |
$addFields |
✔ |
$count |
✔ |
$sample |
✔ |
$sortByCount |
✔ |
$add |
✔ |
Bài 2:
1. Tạo một database có tên Inventory và một collection có tên sales_invent.
Chèn các document sau vào collection sales_invent.
[
{
customername: "Richard",
gender: "M",
purchased_product: "cereals",
quantity: 6,
price: 60
},
{
customername: "Williams",
gender: "M",
purchased_product: "Vegetables",
quantity: 10,
price: 150
},
{
customername: "Emma",
gender: "F",
purchased_product: "Fruits",
quantity: 8,
price: 200
},
{
customername: "John",
gender: "M",
purchased_product: "Baby Food",
quantity: 3,
price: 300
},
{
customername: "Smith",
gender: "M",
purchased_product: "Fruits",
quantity: 5,
price: 180
}
]
Sử dụng collection sales_invent, thực hiện các yêu cầu sau
3.
Loại bỏ trường _id và chỉ hiển thị 10 document đầu tiên của collection sales_invent, chỉ bao gồm các trường:
-
customername -
purchased_product -
price
4.
Sử dụng aggregation pipeline stages để:
-
Nhóm các document theo trường
purchased_product -
Tính tổng doanh thu (Total sale amount) cho mỗi sản phẩm
Chỉ trả về những sản phẩm có Total sale amount ≥ 500.
5.
Sử dụng aggregation pipeline stages để:
-
Chỉ hiển thị 3 document đầu tiên của collection
sales_invent -
Chỉ bao gồm các trường:
-
customername -
purchased_product
-
-
Trong đó
customernameđược sắp xếp tăng dần (ascending order).
6.
Thêm một trường mới có tên product_type với giá trị "edibles" vào tất cả các document trong collection sales_invent.
7.
Trong stage đầu tiên của aggregation pipeline:
-
Nhóm theo trường
purchased_product -
Cộng tất cả các giá trị của trường
quantity -
Lưu kết quả vào một trường mới có tên Total_quantity
Trong stage thứ hai:
-
Ghi (write) kết quả của stage đầu vào một collection mới tên Product_report
-
Collection này nằm trong cùng database Inventory.
8. Sử dụng toán tử biểu thức số học (arithmetic expression operator) để tính tổng giá trị (total price) theo công thức:
price * quantity
9. Chỉ hiển thị chi tiết sản phẩm trong trường hợp:
quantity > 5
10.
Sử dụng toán tử biểu thức chuỗi (string expression operator) để:
-
Nối (
concatenate) hai trường:
customername + purchased_product
Lưu kết quả vào trường mới có tên customer_detail
Định dạng:
customername - purchased_product
Chỉ hiển thị kết quả cho khách hàng nam (male customers).
Bài 2:
Part 1 — Create Database and Insert Data (3 points)
Create database:
companyDB
Create collection:
employees
Insert the following documents:
{
employee_id: 1,
name: "An",
age: 27,
department: "Engineering",
salaries: [1200, 1300, 1250],
skills: ["MongoDB", "NodeJS", "Docker"],
projects: [
{ project: "ERP", hours: 120 },
{ project: "CRM", hours: 95 }
]
}
{
employee_id: 2,
name: "Binh",
age: 30,
department: "Marketing",
salaries: [900, 950, 1000],
skills: ["SEO", "Content", "Analytics"],
projects: [
{ project: "Campaign A", hours: 80 },
{ project: "Branding", hours: 70 }
]
}
{
employee_id: 3,
name: "Chi",
age: 26,
department: "Engineering",
salaries: [1400, 1450, 1500],
skills: ["MongoDB", "Python", "AI"],
projects: [
{ project: "AI Chatbot", hours: 110 },
{ project: "ERP", hours: 100 }
]
}
{
employee_id: 4,
name: "Dung",
age: 29,
department: "Finance",
salaries: [1100, 1150, 1200],
skills: ["Excel", "Accounting"],
projects: [
{ project: "Budget 2026", hours: 90 },
{ project: "Audit", hours: 60 }
]
}
{
employee_id: 5,
name: "Huy",
age: 28,
department: "Engineering",
salaries: [1350, 1380, 1420],
skills: ["Docker", "Cloud", "Security"],
projects: [
{ project: "Cloud Migration", hours: 130 },
{ project: "Security Review", hours: 85 }
]
}
Scoring
| Task | Points |
|---|---|
| Create database and collection | 1 |
| Insert documents correctly | 2 |
Part 2 — Advanced Queries (5 points)
Question 1 (1 point)
Find employees where:
-
department = "Engineering" -
and
age < 29
Question 2 (1 point)
Find employees who have the skill:
-
"MongoDB"
Question 3 (1 point)
Find employees who have both of these skills:
-
"MongoDB" -
"AI"
Question 4 (1 point)
Find employees whose salaries array contains a value greater than or equal to 1400
Question 5 (1 point)
Display only these fields:
-
name -
department -
skills
Do not show _id
Part 3 — Array and Embedded Document Queries (4 points)
Question 1 (1.5 points)
Find employees who have a project where:
-
project = "ERP" -
and
hours >= 100
Use $elemMatch
Question 2 (1.5 points)
Find employees who have at least 3 skills
Question 3 (1 point)
Sort employees by:
-
agedescending -
then
nameascending
Part 4 — Update and Delete (3 points)
Question 1 (1.5 points)
Add a new skill:
-
"DevOps"
to employee with:
-
employee_id = 1
Question 2 (1.5 points)
Remove the skill:
-
"Excel"
from employee with:
-
employee_id = 4
Part 5 — Aggregation Pipeline (4 points)
Generate statistics showing the average working hours per project.
Pipeline requirements
-
$unwindtheprojectsarray -
$groupby project name -
calculate average hours
-
$sortby average hours descending -
$projectthe final output
Output format
-
project -
average_hours
Example output
Cloud Migration → 130
ERP → 110
AI Chatbot → 110
CRM → 95
Budget 2026 → 90
Security Review → 85
Campaign A → 80
Branding → 70
Audit → 60
Scoring
| Component | Points |
|---|---|
$unwind |
1 |
$group |
1 |
$avg |
1 |
$sort + $project |
1 |
Part 6 — Index (1 point)
Create a compound index on:
-
department -
age
Part 7 — Transaction (1 point)
Within a transaction:
-
increase the age of employee
employee_id = 1by 1 -
increase the age of employee
employee_id = 3by 1 -
add the skill
"Kubernetes"to employeeemployee_id = 5
Then commit the transaction.
Submission Instructions
Students must submit their work in a clearly organized folder.
Each submission should include:
1. One MongoDB script file (.js)
The file must contain all commands in the correct order, including:
-
database creation
-
collection creation
-
document insertion
-
queries
-
update/delete commands
-
aggregation pipeline
-
index creation
-
transaction commands
2. One report file (.pdf or .docx)
The report should include:
-
Student full name
-
Student ID
-
Exam code / variant number
-
Screenshots showing execution results of the main tasks
Screenshots should clearly show:
-
inserted data
-
query results
-
update/delete results
-
aggregation results
-
created index
-
transaction execution
Folder naming format
StudentID_FullName_RollNumber
Example:
22110456_NguyenVanA_01
Bài viết liên quan:



Dịch vụ thiết kế Wesbite

